
Article originally published on The New Stack.
The goal of every tech leader is to deliver bug-free products to customers at high velocity. Today’s cloud-native technology can empower engineering teams to iterate, at scale, faster than ever. But teams that don’t also change how they deliver software will struggle to benefit from the agility and speed to deployment that cloud native can offer.
Hosted CI/CD solutions can do a very good job of solving the “integration” part, such as compiling code and with varying degrees of performance and usability. Semaphore’s platform, for example, is based on bare metal hardware to provide the best possible performance. This makes a big difference in productivity in scenarios of parallel testing.
But in a cloud-native approach, managing many microservices in parallel makes delivery more challenging than integration. We need a quick, standardized way of delivering new services to production. And we need to make sure that ops work doesn’t explode in complexity, as we no longer deploy and run a single application, but dozens or even hundreds of services.
The first step is to embrace the programmability of the cloud — you describe your infrastructure as code and manage it in a version control system. Once you treat all infrastructure as you do application code, you can apply continuous delivery to address the challenges of operational complexity. But for that to happen, your CI/CD tool needs to be programmable, too.
Traditional hosted CI/CD services offer deployment features optimized for monolithic Web application deployment, with limited flexibility. When teams move to containers and cloud-native computing, they tend to rely on a CI vendor as a “workhorse” — but often invest engineering time in operating their own instances of Jenkins, which is sometimes combined with Spinnaker, for CD. This is a forced move due to lack of a well-rounded CI/CD product. Teams then face the time-sinking task of maintaining and scaling internal infrastructure, while suffering from a poor user experience and stability issues. It’s a lot of work that brings no value to the company’s end customers.
At Semaphore, we subscribe to the idea that while problems can be complex, solutions must be simple. Since its inception in 2012, we guided product development by two principles: speed and simplicity. About a year ago, we asked ourselves: what kind of a CI/CD product would these principles translate to today?
The answers we found have led us to create a whole new CI/CD product — Semaphore 2.0, which launched this month. The new Semaphore is based on a number of principles and patterns that aim to improve developer productivity for cloud native environments:
1. Speed always matters.
Nobody wants their builds to run slower. If developers need to wait for more than about 10 minutes for Continuous Integration results, they lose focus and work less effectively. A CI/CD product should provide tools to measure and speed up build time.
Take the engineering team at Par8o, an enterprise healthcare company. They use a development workflow that is similar to GitHub flow, merging to master once a story has been verified in the QA environment.
The problem was this was happening too rarely, as running all tests on development laptops was taking more than two hours. So in one workday, the
entire engineering team is unable to merge more than three times per day.
Once they started using Semaphore’s automatic test parallelization feature called Boosters, average build time dropped to just 13 minutes, improving team morale and productivity. Such challenges will continue to matter in the future.
2. Every developer should be able to define and run a custom CD pipeline in minutes.
Most teams developing apps with Docker need to use multi-stage pipelines. For example, in the CI phase we usually need to build container images once, “fan out” to multiple parallel jobs for testing, then “fan in” to collect test coverage results.
Some teams use different strategies across stages. For example, teams at companies such as Toyota have tests that run against different environments, such as QA, staging and production. The code base is the same, but is combined with different configuration or parameters. These tests don’t need to run at the same time, but manually on demand with a system of record. Changing one step in a build should seamlessly reflect in all environments.
Another common use case is to “gate” deployments on the success of another build. For example, we may have multiple applications that all use one library. In that case, we want those applications to not deploy if the tests for that library fail.
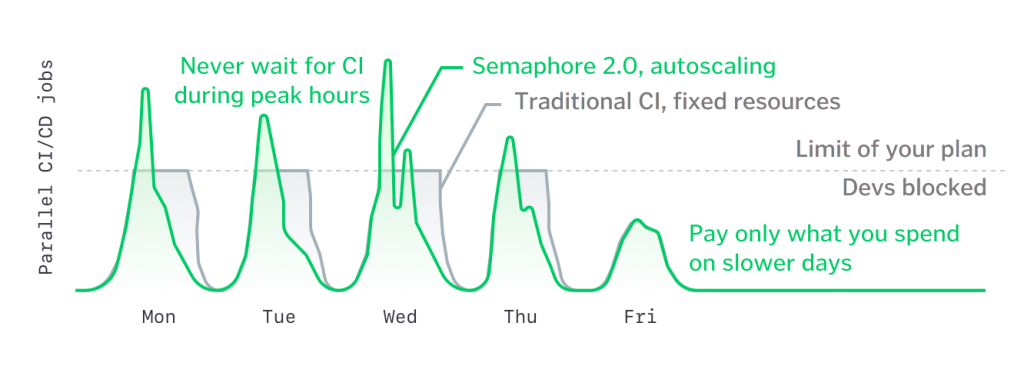
3. Infrastructure is moving from fixed to ephemeral resources.
When CI/CD resources are limited, developers are often blocked in busy times of the week. This is in contrast with the cloud-native “pay only what you use” model, in which the resources we use scale automatically to support the team’s actual needs.
4. A CI/CD feedback loop is more than a pull request status.
The tool of choice should be programmable and act as a handy extension of developers’ natural workflow.
Bootstrapping a new project, including a working CI/CD pipeline, should ideally take minutes. As always automation helps move faster while removing the risk associated with human error.
By describing our CI/CD pipelines in code, as we already do for our cloud infrastructure, we also increase visibility, enable quick onboarding and enable fast transfer of knowledge. If all functions of the CI/CD tool are exposed through a command-line interface, developers can interact and build upon it as easily as they work with code libraries.
5. CD throughput needs to be measured.
Instead of prescribing the same key numbers for every project, CI/CD tool should let users choose their own metrics and define their own dashboards. Some projects are having an issue with build time. On others it’s most critical to know how often we deploy to users.
Most metrics, however, are no longer relevant on a per-repository level. When an application is composed of many microservices, what matters are aggregate metrics. So CI/CD dashboards can include summaries of the latest work across a family of services, insights about deploys to production or average build duration.
Cloud-native computing was once reserved only for the biggest and most advanced engineering organizations like Netflix or Spotify. The rise of Docker, Kubernetes and related tools and services is making the model accessible in the mainstream. Likewise, doing Continuous Delivery at scale is in a transition from requiring a specialized in-house team to becoming a turn-key service. At Semaphore, we’re thrilled to be part of this journey, and remain committed to making CI/CD easy for everyone.
