Post originally published on https://claudiajs.com/. Republished with author’s permission.
Introduction
Effective test automation is one of the corner stones of modern software quality, but for many teams out there, moving to AWS Lambda creates major test automation challenges. With no control over infrastructure, and an almost magical execution environment, it can be difficult to judge how much local automated tests actually de-risk important concerns. Wiring everything up just makes tests too brittle and too slow, but running things in isolation doesn’t give anyone enough confidence.
With a bit of upfront thinking about code design, and building testability in, it can be relatively easy to test Lambda functions, API Gateway wrappers and all the typical service integrations, while still keeping the maintenance cost and execution time in check. Here’s how!
How Lambda Changes the Game for Testing
Services running in AWS Lambda are great because developers do not need to care too much about infrastructure. But that doesn’t remove infrastructure risks — it just changes them. Although scaling and distribution risks are no longer a big issue, configuration, wiring and deployment become significantly more important. Some things, such as testing database disconnects and service restarts, aren’t even possible to cause in an automated way, save from launching a nuclear attack on an AWS data centre. So we have to design the software differently to de-risk such concerns.
Unless you’re working internally at AWS, the infrastructure where code runs in Lambda is a big unknown, and lots of people are justifiably concerned about how much a passing local test means for de-risking production environments. It’s trivially easy to set up several copies of the same software in Lambda, so the typical brute-force solution is to run all tests completely integrated, end-to-end. This might be almost free, but it’s not very effective time-wise. First of all, although new deployments don’t cost anything directly, they aren’t instantaneous, so they introduce indirect cost in lost developer time. Even with a simple AWS Lambda + API Gateway combination, a deployment might take a minute or so due to rate-limits on configuration API calls. That’s enough to definitely eliminate the option of running a clean deployment for each test. Likewise, because most people use Lambda functions to communicate to other services such as S3 or DynamoDB, testing everything end-to-end often causes tests to be slow and brittle, limiting the number of automated tests people can afford to run after each commit. On the other hand, speeding up tests but compromising on risk coverage is dangerous. Fast tests that do not address risks are like fast food. Easy to make, easy to consume, but in the long-term damaging your health.
In order to solve that puzzle, most teams will need to re-think how they approach design and testing.
A Small But Important Terminological Digression
Testing terminology is often a cause of chaos and misunderstanding, in particular when people mistake the type of risk and the area of coverage. For example, it’s a popular belief that unit tests are purely technical developer-oriented tests, but they don’t have to be. Unit tests cover an area of a code unit, typically a small function, in isolation. They can inspect that unit of code from a technical perspective, or from a business perspective. They can also inspect it from a performance standpoint. Luckily, in most cases, a small unit of code often doesn’t do anything important business-wise, so the mapping from surface area to risk type is correct in many cases for unit tests. However, as the area starts growing, the difference becomes more important. That’s particularly problematic when discussing integration tests.
Without trying to start a comment war, I’d like to be able to discuss two types of tests separately in this article, but for most people the two groups have the same name. So I’ll have to give them different names in order to refer to them separately in this article. Here it goes:
- Integration tests are those that primarily de-risk connections between various components, normally something you build and something that someone else has built. For example, a test that checks if my code saves things correctly to an S3 file system would be an integration test. The primary characteristic identifying an integration test is the type of risk it covers, and this category does not imply anything about the area of coverage. They can be automated against a single unit of code, around several components, through a subsystem or even around the entire system.
- Integrated tests are those that check the system as a single piece, integrated into the final form. The primary characteristic of such tests is the area they cover, not the type of risk they are inspecting. So, for example, it’s possible to have a integrated test that checks for security compliance, or an integrated test for business workflows.
These two terms describe two different dimensions of a test. Of course, it’s possible to have an integrated test that checks for integration risks, but they don’t have to. And because most people don’t question the two dimensions, they always run integration tests fully integrated. This, unfortunately, creates a major headache in a situation where the environment is a huge risk, such as when your software runs in the cloud.
The deeper the code is in the system, the more difficult it is to exercise all the boundary conditions end-to-end. For example, to properly test for XML parsing problems we may need to come up with lots of weird scenarios that cause an invalid XML message to get generated. But what if there’s some kind of validation upfront that discards invalid documents in another component? Then the internal XML parsing module will never get any of those weird scenarios. So it’s not enough to think about edge cases of just one component, we have to consider all the components in combination.
Let’s say, optimistically, that we’re only talking about two components and that each has 10 important edge cases. To reasonably cover just the expected risks, we’ll need 100 test cases — a product of the two types of variations. But if we divide the concerns, and inspect each component separately, there are only 20 test cases needed. However, we’ve not really covered all the risks then, because there might be problems in the way those two components talk to each other. That’s where integration tests come in. As long as we can cover the integration of the two components separately, it’s far better to run smaller tests. They’ll work faster, they will be easier to maintain, and there will be significantly fewer tests to run compared to trying to cover everything with integrated tests. Instead of 100 integrated tests, we can have 20 component tests, five or so integration tests and perhaps one more end-to-end smoke test just to confirm that everything is connected correctly. Even with just two components, we can reduce the number of test cases by 75% and significantly speed up the majority of them, probably reducing total execution time by 95%. Add more components into the mix and the numbers rise significantly.
The larger the area of coverage, the slower the tests are generally, and the more difficult to maintain. But if we design our code so that we can check different types of risks separately, then tests become reasonably easy to work with. So the trick is in designing the code for testability.
How This Idea Applies to Lambda Functions
Here’s a simple Lambda function that kind of works, but gets the whole design wrong. It listens to S3 events, and when a file is uploaded to a S3 bucket, it uppercases the contents, and saves the result to a file in a different folder on S3. The transformation is simple in this case, just to keep the code easy to read, but you can imagine this doing much more complex things, for example converting spreadsheets to PDFs.
var aws = require('aws-sdk');
exports.handler = function (event, context) {
var convert(bucket, fileKey) {
var s3 = new aws.S3(),
Transform = require('stream').Transform,
uppercase = new Transform({decodeStrings: false}),
stream;
uppercase._transform = function (chunk, encoding, done) {
done(null, chunk.toUpperCase());
};
stream = s3.getObject({
Bucket: bucket,
Key: fileKey
}).createReadStream();
stream.setEncoding('utf8');
stream.pipe(uppercase);
s3.upload({
Bucket: bucket,
Key: fileKey.replace(/^in/, 'out'),
Body: uppercase,
ACL: 'private'
}, context.done);
},
eventRecord = event.Records && event.Records[0];
if (eventRecord) {
if (eventRecord.eventSource === 'aws:s3' && eventRecord.s3) {
convert(
eventRecord.s3.bucket.name,
eventRecord.s3.object.key
);
} else {
context.fail('unsupported event source');
}
} else {
context.fail('no records in the event');
}
};
The problem with this function is that it’s almost impossible to test well in an automated way. Sure, we can load it even without running in Lambda, but we’d still have to connect to a real S3 service. We could run tests with simulated events that look similar to S3 events, but that will still be very slow and brittle. It will be difficult to test error scenarios. For example, testing what happens when the upload breaks mid-way would need some kind of network failure exactly at the right moment, but things like that are difficult to automate and simulate. Because this function is difficult to test properly, many important edge cases just won’t be covered.
The first step in making this kind of function testable is to look at all the different concerns, and test them separately. Then look at the integration between the different points and inspect that separately as well. Finally, have one test that just checks if everything is configured and connected correctly, running end-to-end.
Here’s a quick list of different risks in this function:
- Wiring and configuration: Are we receiving the S3 events from the correct bucket? Are we saving to the correct bucket? Does the role for the Lambda function have the correct access rights for the bucket?
- Technical workflows: Are we using the incoming events correctly? Are we handling the errors well?
- Business logic: Is the file conversion correct? Are we saving the results to the right folder based on the input file name?
- Integration: Are we reading the Lambda event structure correctly? Are we reading and writing files to S3 correctly?
To be able to inspect each of those separately, we first need to break down the code into several functions. One good guide for that is the Hexagonal architecture pattern, also called Ports-and-Adapters.
The Hexagonal Architecture is a design pattern where the core of an application does not directly talk with external resources or allow any external collaborators to talk to it directly. Instead, it talks to a layer of boundary interfaces, using protocols designed specifically for that application. External collaborators then connect to those interfaces,and translate from the concepts and protocols important for resource to the ones important for the application. For example, the core of the application in a Hexagonal Architecture wouldn’t directly receive Lambda events, it would receive something in an application-specific format, say with filePath and location describing where to read the file from. An adapter would be responsible for converting between the Lambda event format and the application event format.
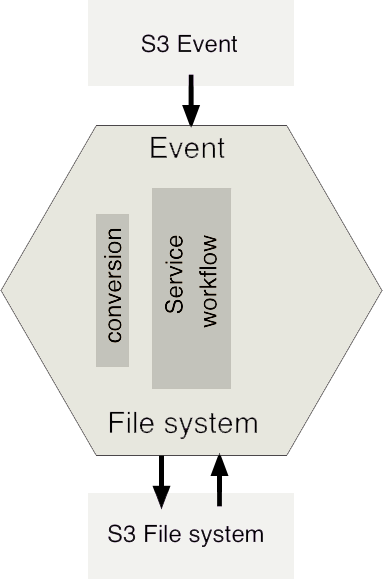
Similarly, the core of the application would not talk to S3 directly, but it would talk to a boundary interface that is specific for its needs. For example, the FileSystem could be any object that has two functions: readAsStream and writeFromStream. We would then write a separate S3FileSystem object that implements that particular interface, and talks to S3.
This separation would allow us to test S3 integration without worrying about internal workflows. It would also allow us to test internal error handling easier, by providing a different FileSystem interface that we could control easily, and trigger errors.
So let’s start to break this monolith apart. The first thing we need to do is to pull out the service workflow, the core of our hexagon, from the Lambda processing interface. This would allow us to could supply it with any event, file system or converter. To keep it consistent with Node.js execution, we’ll also provide it with a callback for asynchronous execution. For homework, to try out an even more extreme case of Hexagonal Architecture, convert this to use the Promise objects available with Lambda using Node.js 4.3.2.
module.exports = function conversionService(event, fileSystem, converter, callback) {
if (!event) {
callback('event not specified');
return;
}
var outputFilePath, inputStream, convertedStream;
try {
outputFilePath = event.filePath.replace(/^in/, 'out');
inputStream = fileSystem.readAsStream(event.filePath, event.location);
convertedStream = converter(inputStream);
fileSystem.writeFromStream(
outputFilePath,
event.location,
convertedStream,
callback
);
} catch (e) {
callback(e);
}
};
This is now a nice isolated function, that we can test separately by proving an in-memory file system interface, a simpler converter, and generally exercise all kinds of weird edge cases. It would have dozens of very quick tests to prove what happens when file reading fails, when the conversion breaks, and when writing fails. The actual conversion details or how we write or read streams aren’t important here, we only care about the overall workflow. For example, it would be much easier to test now what happens when the event file path does not include the expected prefix. We might get events uploaded to other directories, and they should ideally be ignored. The way the code works at the moment would cause them to be overridden with uppercase content.
The most important thing when designing this function would be to imagine external interfaces so they enable us to isolate those risks completely. The way we want to use external interfaces from this function, so that it’s simple and easy to manage, will drive how we implement the other components. That’s why, for example, writeFromStream has a callback argument at the end, so it is convenient to use from this function.
Next, the S3FileSystem class would implement the two file interaction functions our service needs:
var aws = require('aws-sdk');
module.exports = function S3FileSystem() {
var self = this,
s3 = new aws.S3();
self.readAsStream = function (s3Key, bucket) {
var stream = s3.getObject({
Bucket: bucket,
Key: s3Key
}).createReadStream();
stream.setEncoding('utf8');
return stream;
};
self.writeFromStream = function (s3Key, bucket, stream, callback) {
s3.upload({
Bucket: bucket,
Key: s3Key,
Body: stream,
ACL: 'private'
}, callback);
};
};
This object cares about all the S3 specific concerns, for example setting the correct access control list. The conversion service function doesn’t care about ACLs on S3. On the other hand, the S3 file processing no longer cares about file conversion, the right way to rename input files to output files, all the exceptions around uploads to other folders and so on. Instead of trying out dozens of workflow tests, we can execute only two integration tests to prove how the functions use the AWS SDK. For example, a good test would be to upload small a file to a predefined location, and check if the readAsStream function returns the correct stream contents.
The next piece to transform would be the content conversion function. When designing the service, we imagined it working with streams directly, so let’s implement that interface:
module.exports = function uppercaseStream (inputStream) {
var Transform = require('stream').Transform,
uppercase = new Transform({decodeStrings: false});
uppercase._transform = function (chunk, encoding, done) {
done(null, chunk.toUpperCase());
};
inputStream.pipe(uppercase);
return uppercase;
};
This is again an isolated function with a well defined scope and risk profile. We can test it with in-memory streams, prove the conversion business logic and inspect what it does with boundary conditions. For example, a good test would make sure we avoid the unicode case conversion problems that allowed accounts to be hijacked on Spotify. All those tests would be quick and we could directly create the boundary conditions, instead of having to fight the surrounding components. And we could run thousands of tests here if we wanted, very quickly, without having to worry about S3 writing latency or Lambda deployments.
Next, we need to convert from the Lambda S3 events to our event interface, and deal with all the potential formatting issues.
module.exports = function parseS3Event(lambdaEvent) {
var eventRecord = lambdaEvent.Records && lambdaEvent.Records[0];
if (eventRecord && (eventRecord.eventSource === 'aws:s3' && eventRecord.s3)) {
return {
filePath: eventRecord.s3.bucket.name,
location: eventRecord.s3.object.key
};
} else {
return false;
}
}
We can test this function in isolation as well, supplying some example events that come from S3 and elsewhere. Separating the function like this would allow us to be more flexible in the future, if we need to add more event sources. For example, we use Lambda functions to convert mind maps to PDFs and images in MindMup 2.0, and several Lambdas need to receive events from the same S3 bucket, because they handle different formats. A good way to achieve that with AWS is to send the S3 bucket events to SNS, and then subscribe various Lambdas to the SNS queue. Unfortunately, that changes the event format. When the event conversion is separated into a small function such as this one, we could easily accommodate the new format with a very small, isolated change. We could also test it well in this unit of code, quickly. Testing the actual S3 -> SNS -> Lambda flow would just introduce another moving part and another source of latency, and it would be completely unnecessary.
Lastly, we need to wire everything up. The actual Lambda function then just needs to care about connecting the right components:
var parser = require('./parse-s3-event'),
fileSystem = require('./s3-file-system'),
uppercaseStream = require('./uppercase-stream'),
conversionService = require('./conversion-service');
exports.handler = function (event, context) {
conversionService(parser(event), fileSystem, uppercaseStream, context.done);
}
We could, in theory, also test this function locally, just to verify that it’s connecting everything. However, there is more risk in something not being configured well here than a single line of code being wrong. I would prefer to test this directly on Lambda, one final fully integrated test, and I’d do that by pushing a file to S3 and waiting for it to be converted. That would really test everything end-to-end, not just my impression of how end-to-end might behave. That test would be slow, potentially brittle, but it’s just a single, small, final test and we could afford to keep it like that. The risk profile would justify maintaining it.
This would be a great way to use the powerful Lambda aliases, where we can create a new version, assign the ‘smoke-test’ alias to it, and use it for an automated post-deployment test. Once the final test passes, we can just re-assign the production alias to the new function version, without re-deploying things. That would make sure that the final tested version ends up being the one we actually use in production.
For the really paranoid, with the cloud, there’s also a risk that something stops working after deployment although you didn’t change anything. Smoke tests like the one I suggested for post-deployment are great for monitoring, especially if they are automated and isolated so they don’t disrupt normal work. Once we have a fully automated test that checks if everything is wired up and configured correctly, we can fire it off every ten minutes or so and get a warning if something got stuck due to external factors.
For some nice theoretical ideas that expand on the Hexagonal Architecture, check out the Repositories and Services ideas from Domain Driven Design, as well as the related Anti-Corruption Layer pattern. All these ideas help with dividing the code around various areas of concern, so they can be tested separately, and they’re absolutely crucial to get the really complex services easy to maintain, not just easy to test.
If you have any questions and comments, feel free to leave them in the comments below.
Read next: