High-Availability is crucial in Redis to ensure the continuous availability of data and prevent downtime. Although Redis is known for its high performance, there are instances where a single server might not be sufficient to meet the data requirements of an organization. Running Redis across multiple servers provides a resilient architecture where the system can continue to operate without interruption and data loss in-spite of one or more server failures. This also has an added benefit of enhanced performance.
This article covers Redis High-Availability (HA) strategies. We will start off with Leader-Follower architecture which is based on data replication and learn how Redis Cluster builds on top of it. This will be followed by a discussion of Redis Sentinel, which uses a set of external processes (sentinels) to monitor Leader-Follower deployments before closing off by covering Proxy based setup.
What is Redis?
Redis is an open-source, in-memory data structure store. Its core data types include String, List, Hash, Set, Sorted Set Geospatial indexes, HyperLogLog and Bitmap. You can use Redis as a messaging system, thanks to its support for Redis Streams, Pub/Sub as well as List (which can act as a queue). Although it’s an in-memory store, you can choose from a spectrum of persistence options. Transactions and Pipeline capabilities help build performant applications at scale, while Lua scripting, server-side Functions and Redis Modules enable you to extend Redis’ functionality.
Now, let’s dive into the various Redis HA architectures.
Leader-Follower topology
A Leader-Follower architecture consists of multiple Redis nodes, where one node is designated as the Leader (also known as the Primary), while the others function as Followers (or Replicas). The Leader-Follower replication mechanism in Redis is the cornerstone of operating Redis in a distributed and highly-available manner. By default, replicas are configured to be read-only, which means they reject all write commands. This design ensures that the data on the replicas remains consistent with that of the primary node.
Writable replicas can introduce inconsistencies between the primary and the replica, hence they are not recommended for use.

The primary node continuously replicates data to the replica nodes, ensuring that they are exact copies of the primary node. One of the advantages of the asynchronous replication process is that the primary node does not have to wait for a command to be processed by the replicas, ensuring low latency and high performance. In addition, the primary node tracks which replica has processed which command, as the replicas periodically acknowledge the amount of data they have received.
Replication serves the dual purpose of improving data safety and high availability, as well as facilitating scalability by using multiple replicas for read-only queries. Slow O(N) operations can be offloaded to replicas, improving the overall performance of the system. By leveraging replication, Redis can operate as a reliable and scalable distributed database.
Redis Cluster
Since Redis is an in-memory database, one of its limitations is that the amount of data that can be accommodated is dependent on the available RAM of the host machine. To overcome this limitation, data needs to be distributed across multiple Redis servers. Redis Cluster is an advanced feature that builds on top of the Leader-Follower replication mechanism to enable horizontal scalability. A Redis Cluster comprises multiple shards, each of which can have a primary node and zero or more replica nodes. If you scale out the number of shards in a cluster, data is automatically partitioned and distributed across the primary Redis nodes – this process is known as Sharding.
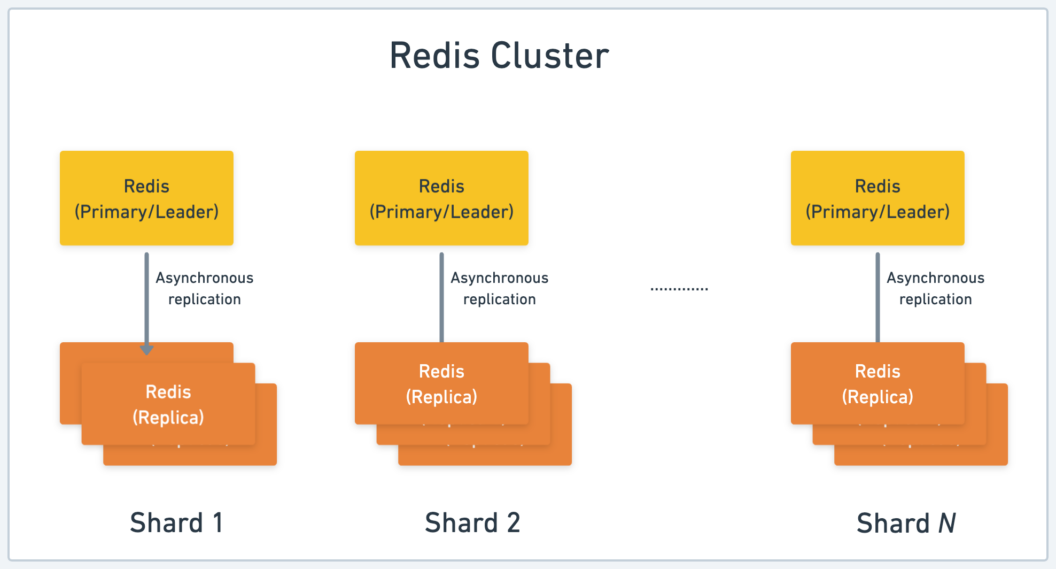
In Redis sharding implementation, every key is part of a logical Hash slot. A Redis Cluster is divided into 16384 hash slots, and a deterministic formula is used to derive the key to hash slot mapping, i.e. [ CRC16(key) mod 16384 ]. There are often scenarios where your application might need to operate on multiple keys at once (multi-key operations): for example, deleting many keys at once. Since Redis Cluster shards/distributes data across multiple nodes, these keys might not be present in the hash slot. If you operate on multiple keys that belong to different hash slots, the operation will fail with a CROSSSLOT error.
To overcome this, Redis Cluster provides Hash Tags – you can use curly braces {} to specify the part of the key that will be hashed. This enables users to control the key to hash slot mapping and make the process deterministic. Here is an example of how you might use hash tags. For instance, if you have the user purchase information for user 37 in a Redis Hash called user:37:purchases and the user metadata info in user:37:info, curly braces {} can be used to define the part of the key that will be hashed. In this case it could be as follows: {user:37}:purchases and {user:37}:info. The hash slot is decided by the sub-string {user:37} (not the entire key).
It’s worth noting that, Redis version 7.0 introduced Sharded Pub/Sub, which can be used with a Redis Cluster. Unlike regular Pub/Sub where each message is sent to every node in the cluster (even across shards), sharded Pub/Sub restricts the message to within a given shard of a cluster. Shard channels are assigned to slots using the same algorithm as keys. Messages must be sent to the node that owns the slot for the channel, and are forwarded to all nodes in the shard. Clients can subscribe to a shard channel through the primary node or any of its replicas.
Redis Cluster provides automatic data distribution across multiple nodes, enabling users to scale beyond a single server. In addition, it ensures that operations can continue even when a subset of the nodes experiences failures or is unable to communicate with the rest of the cluster. This feature provides increased reliability and fault tolerance for Redis users.
Redis Sentinel
Redis Sentinel is a distributed system which is designed to run in a configuration where there are multiple Sentinel processes cooperating together. Redis Sentinel uses a quorum-based approach to ensure the failover decision is made by a majority of Sentinels, preventing the risk of split-brain scenarios. It also supports configuration updates, automatic node discovery, and can notify administrators of important events.
It constantly checks if primary and replica instances are working as expected. If a primary is not working as expected, Sentinel can start a failover process, whereby a replica is promoted to primary and the other replicas are reconfigured to use the new primary. Sentinel also acts as a configuration provider for service discovery – clients connect to Sentinels in order to ask for the address of the current Redis primary responsible for a given service. If a failover occurs, Sentinels will report the new address.
Sentinel can also notify the system administrator, or other systems (via an API) that something is wrong with one of the monitored Redis instances.
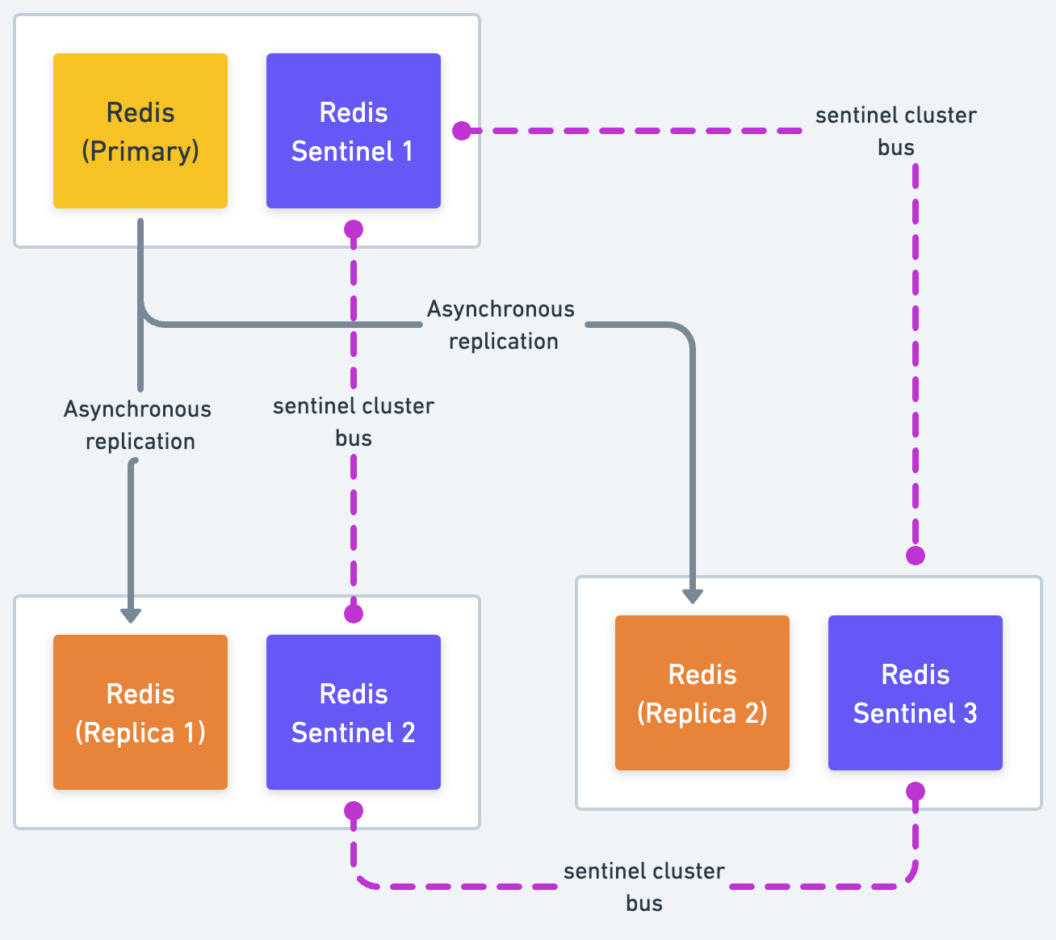
This setup consists of three sentinel servers operating alongside Redis nodes. It is based on three boxes, each box running both a Redis process and a Sentinel process. If the primary fails, sentinels 2 and 3 will agree about the failure and will be able to authorize a failover (based on quorum).
Proxy
A proxy based HA architecture sits somewhere between the Redis Cluster and Redis Sentinel. Like Sentinel, it relies on an external component to front-end a fleet of Redis servers. It also takes care of data partitioning using custom schemes, just like Redis Cluster does.
A Server-side proxy consists of an intermediate server that speaks the Redis protocol and fans out the request to the appropriate Redis server from a fleet of servers.
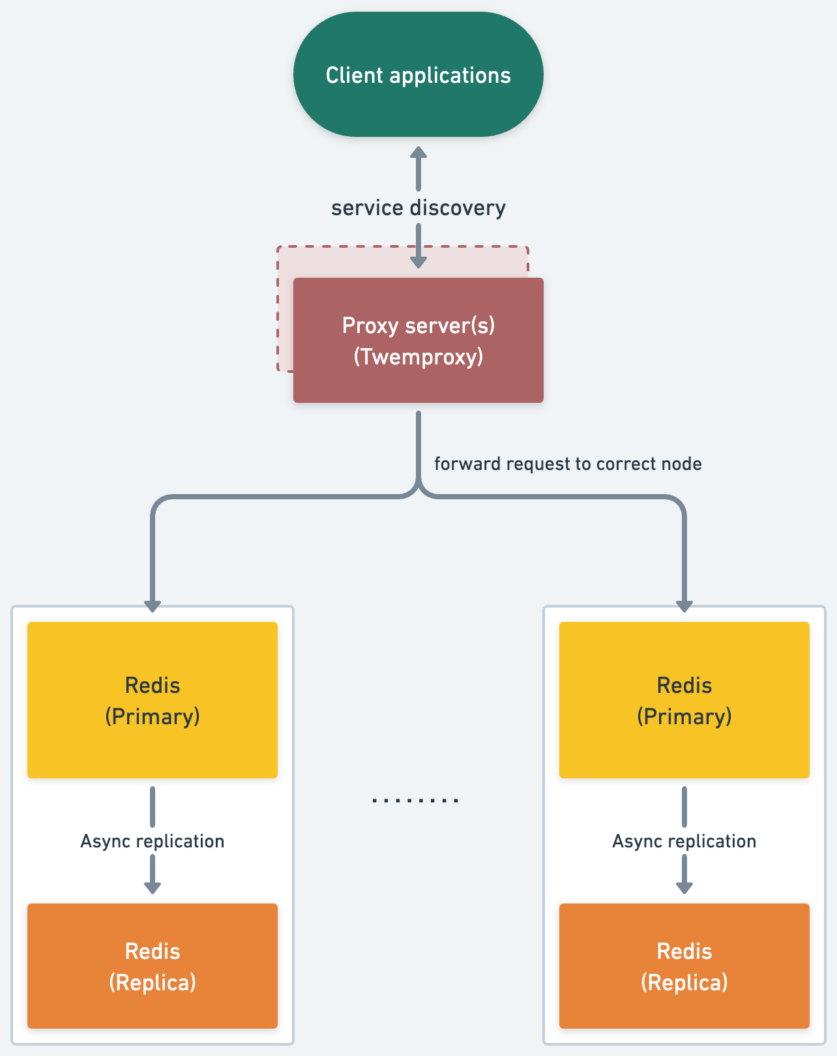
A popular server-side proxy solution is twemproxy. It was built primarily to reduce the number of connections to the caching servers on the backend. This, together with protocol pipelining and sharding enables you to horizontally scale your distributed caching architecture.
Deployment options for Redis
The architectures discussed above can be deployed in multiple ways, including :
- On-premises, where you manage the infrastructure yourself.
- Using Kubernetes with Operators or Helm Charts.
- In the Cloud, where you can use a fully-managed Redis service.
- Or a combination of the above (Hybrid model)!
Since the options seem limitless and can be overwhelming, let’s focus on the Cloud-based Redis solutions.
Since Redis is popular and widely used in production, there is no shortage of cloud-based, hosted Redis offerings from a variety of vendors, big and small. Most (if not all) of these providers typically offer Redis as a fully-managed service that provides high availability and fault tolerance out of the box. They also provide additional features such as data persistence, monitoring, and alerting. Although most cloud providers currently standardize Redis Cluster or Primary-Replica as the HA architectures, some of them might also offer Redis Sentinel as an option. You will need to evaluate the pros and cons of each option and choose the one that best fits your needs.
Which HA Architecture is right for you?
Let briefly discuss the pros and cons of each architectural approach and when you should use it.
Leader-Follower topology
Pros
- Simple architecture – Easy to understand and implement.
- Future proof – Can be upgraded to Redis Cluster.
- Data Migration – It’s easier to migrate data from another Redis setup.
Cons
- Since replica nodes are read-only, it can only be used to scale reads. If your application is write-heavy, you will need to consider other options.
- No concept of data partitioning – the primary node is the single source of truth for all the data.
Choose it when
- You have a read-heavy application.
- You don’t (or can’t) use a Redis Cluster (e.g. because of multi-key operations constraints).
Redis Cluster
Pros
- Data is automatically partitioned across the cluster.
- You can scale both reads (add more replicas in a shard) and writes (add more shards).
Cons
- Requires Redis Cluster-aware client.
- You need to design your application with multi-key operation constraints in mind.
- For fine-grained control, you need to modify the application to use client-side sharding with hashtags.
- Complex architecture – Running a Redis Cluster at large scale introduces additional operational complexity as well as large infrastructure requirements.
Choose it when
- You need the ability to scale both reads and writes.
- The programming language you are using for client application has a battle-tested, well maintained Redis Cluster client.
- You can tolerate architectural complexity for additional functionality (as discussed above).
Redis Sentinel
Pros
- It provides automatic failover.
- Also acts as a configuration provider for service discovery – clients don’t need to be aware of the Redis topology.
Cons
- Complex architecture – extra server fleet to maintain.
- You need a specialized (Redis Sentinel aware) client.
Choose it when
- You need automatic failover, but don’t want to (or can’t) use a Redis Cluster.
- You can tolerate architectural complexity for additional functionality – if not, stick to primary-replica based architecture.
Proxy-based solution
Pros
- You get load balancing, data partitioning with the additional benefit of connection management.
- Doesn’t require a specialized client (Cluster or Sentinel aware) – so you can continue to use a standalone Redis client.
Cons
- Complex architecture – extra server fleet to maintain.
- Must resort to third-party components, which are not part of the standard Redis tooling (like Redis Cluster or Sentinel).
Choose it when
- You are using Redis as a simple cache and don’t need automatic failover.
- You want/need to enhance your Primary-Replica setup, but don’t want to use Redis Cluster or Sentinel.
Conclusion
This article covered different high-availability architectures for Redis. We also discussed the pros and cons of each approach and provided guidance on which use case is best suited for each one. At the time of writing, Redis Cluster is the default recommended solution, since it provides both read and write scalability along with automatic data partitioning. Consider using other approaches only if you have a specific use case that cannot be satisfied by Redis Cluster.
