Machine learning is everywhere. The state-of-the art of the field is advancing at an astronomical pace. GPT-3 can answer significantly complex questions, Stable Diffusion can generate incredible images from just words, and the list goes on. It’s nothing short of amazing.
But while the state of the art is being pushed daily, the long tail (e.g. the industry) is struggling to keep up. Most Machine Learning projects still have a significantly high failure rate. Data Science and ML teams are under increasing pressure to deliver successful Machine Learning models to the rest of the organization. Often, that delivery comes in the form of a microservice.
A Machine Learning microservice is an API that serves the ML team’s model. Designing a good Machine Learning microservice can be a challenging process. One of the most challenging aspects is keeping prediction latency down. Often, there will be requirements on how fast predictions need to be served, especially if the model is mission-critical.
In this article, we’ll go over 4 techniques that Machine Learning practitioners can leverage to scale their Machine Learning microservices. These techniques allow a microservice to more easily scale to thousands of users.
1. Leverage the Cloud
The API is working on the development machine. Awesome. It’s now time to deploy it to production. Chances are that some sort of Public Cloud (e.g. AWS, GCP, or Azure) is available.
Choosing exactly which Cloud Service to use to deploy your microservice can make a big difference.
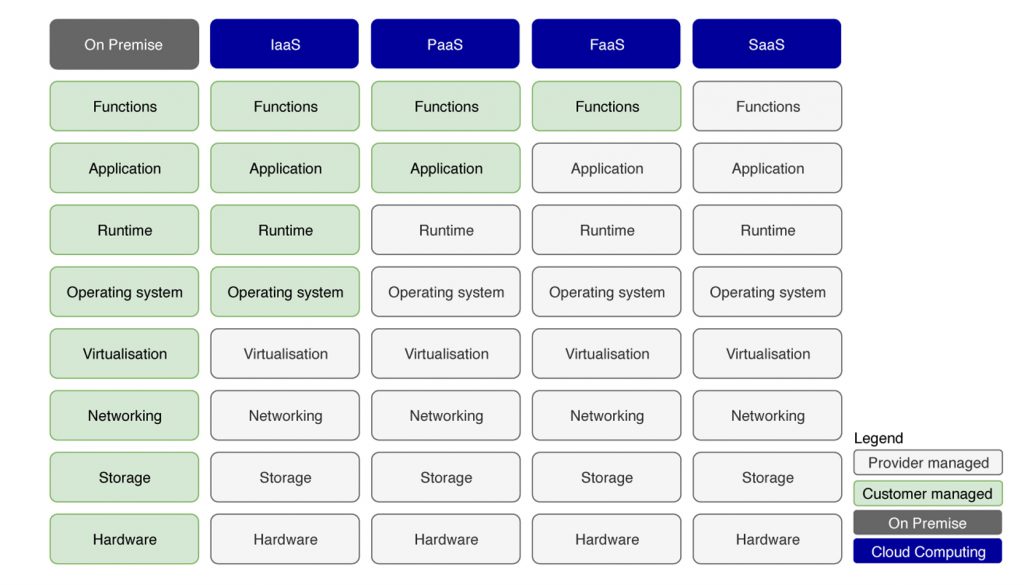
There are 5 major types of services:
- SaaS: (not relevant for this article).
- FaaS: Function as a Service. You give a function to the Cloud vendor, and they take care of the rest (e.g. Azure functions, AWS Lambda).
- PaaS: Platform as a Service. You give a container to the Cloud vendor, and they take care of the rest (e.g. Cloud Run, AWS Beanstalk).
- IaaS: Infrastructure as a Service. You rent a machine from the Cloud vendor (e.g. EC2 on AWS).
- On-site: (not relevant for this article).
All of these have pros and cons. Generally, the more control you have over your infrastructure, the more expensive it gets (e.g. EC2 is more expensive than Lambda). However, if you rent an EC2 machine, that probably means that the machine is always on. One big advantage of PaaS and FaaS services is that they are elastic (e.g. you don’t have to pay if nobody is using your API). When using FaaS and PaaS services, the Cloud provider will automatically scale your microservice depending on traffic. If you are renting a virtual machine to deploy your service, you are limited to that single machine, and will be billed all the time, even if you are not making any predictions.
Generally, it’s a good idea to start simple, and gain more and more control over infrastructure as your needs evolve. This means that you should start by leveraging the most Cloud Native services first (e.g. start with FaaS, and move towards IaaS as your needs evolve).
Here’s an example:
- Design an app as a function.
- Deploy the API to Google Cloud Functions (FaaS).
- Example problem: permanent storage is needed, and Google Cloud Functions don’t offer it.
- Redesign the app as a container.
- Deploy the API to Google Cloud Run (PaaS).
- Example problem: a GPU is needed, and Google Cloud Run doesn’t offer it.
- Redesign the app to leverage GPUs.
- Deploy the API to Google Compute Engine (IaaS).
You can check out compare cloud to find the equivalent services for your Cloud provider.
Choosing the right microservice platform will make sure that your API can scale to the right requirements, and that you design the most efficient service possible.
2. Parallelize
Like most Machine Learning practitioners, chances are that you’re designing your microservice in Python. Even though Python is thought of as a slow programming language, there are some lesser-known techniques that can make it significantly faster.
There’s a high likelihood you can parallelize a process in your microservice and deliver predictions faster. Generally speaking, there are 3 main concurrency APIs that you can leverage in Python: Multi-processing, Multi-threading, and AsyncIO. Which one you choose largely depends on what type of task you want to parallelize. IO-bound tasks (e.g. calling an external API) should leverage threading or AsyncIO, while CPU-bound tasks (e.g. Linear Algebra) should leverage multi-processing.
Here’s an API decision tree from one of the best concurrency resources out there: superfastpython.com
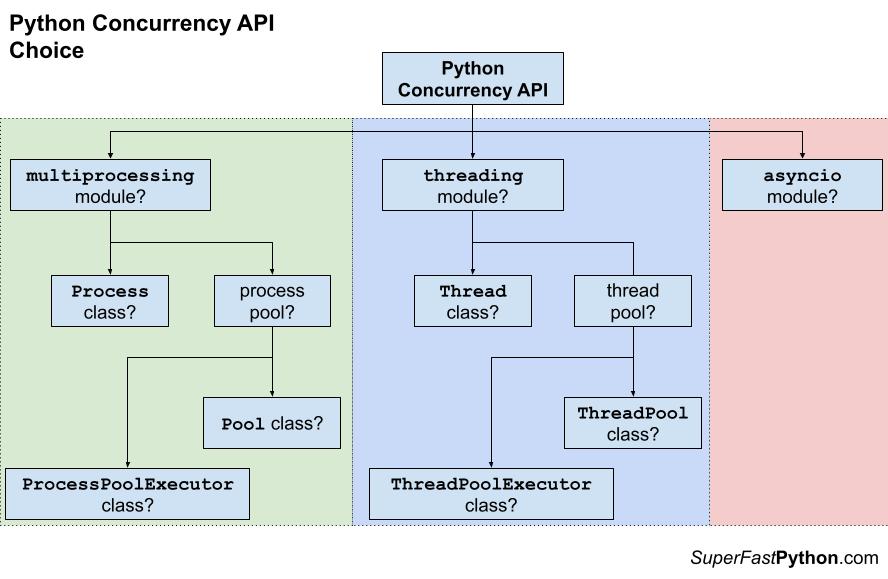
Let’s take a look at a very simple example: we get some data from our user, fetch some external data, and then make a prediction on that fetched data:
from fastapi import FastAPI
from pipeline import model
app = FastAPI()
@app.post("/predict/")
async def predict(items):
item_data_array = []
for item in items:
item_data = fetch_item_data(item) # <- IO BOUND TASK
item_data_array.append(item_data)
predictions = model.predict(item_data_array)
return predictionsSince fetch_item_data is a function that calls an external API (e.g. an IO-bound task), we can parallelize it using threads. This decreases the readability of our code, but significantly increases speed:
from fastapi import FastAPI
from pipeline import model
import concurrent.futures
import asyncio
import functools
app = FastAPI()
@app.post("/predict-fast/")
async def predict_fast(items):
item_data_array = []
# less readable, but significantly faster
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
loop = asyncio.get_event_loop()
futures = [
loop.run_in_executor(
executor,
functools.partial(
fetch_item_data,
item,
),
)
for item in items
]
for r in await asyncio.gather(*futures):
item_data_array.append(r)
predictions = model.predict(item_data_array)
return predictionsNext time you design your microservice, consider parallelizing some of the tasks to increase scaleability.
3. GPU-based inference
As models are getting larger, and datasets are getting bigger, the need for GPUs is quickly increasing. Training on a GPU regularly means a 10x (!) decrease in training time for your model. Popular frameworks, such as Hugging Face for NLP, are even designed to leverage multiple GPUs.
Most ML engineers should be pretty familiar with training models on GPUs. But what about inferencing? It’s also possible to leverage a GPU when making predictions. Hugging face, for example, uses a method called “Int8 mixed-precision matrix decomposition”. This works by reducing the mathematical precision of some model weights without impacting the accuracy of the model.
For example, this code:
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)loads the optimized ‘8-bit’ version of the bigscience/bloom-2b5. If a GPU is available, the device_map=auto keyword argument would automatically make use of it.
It’s worth investigating if your framework supports inferencing on GPUs, but there are some caveats:
- Having GPUs available at runtime is not so common. For example, Google Cloud Run does not support GPUs, but AWS lambda looks like it does.
- GPUs are expensive, especially if you don’t shut them off when you finish. So be aware of that.
- Make sure you choose the right hardware. Multiple CPU-based inferences in parallel could have similar performance at a lower cost than a GPU-based inference.
4. Use a batching endpoint
It’s common for a Machine Learning microservice to serve an endpoint to make predictions. This endpoint has several responsibilities:
- Validating data that is passed to the API
- Cleaning and formatting the data to be used in the model
- Making a prediction with the model
- Formatting the result
- Returning the result to the API caller
Here’s a simple example:
from fastapi import FastAPI
from pipeline import model,
clean_data,
format_data,
data_is_valid
app = FastAPI()
@app.post("/predict/")
async def predict(item):
if not data_is_valid(item):
return {"message": "data not valid"}
item = clean_data(item)
predictions = model.predict(item)
output = format_data(predictions)
return outputBeing able to scale means that your API endpoint gracefully handles simultaneous invocations in very short intervals. This means that we need to take advantage of anything we can do to improve our latency. To do this, we can leverage the fact that Python is mostly based on the C programming language. Numpy, for example, does this by further extending Python to take advantage of the C programming language. As a result, it’s very fast.
The speed of Numpy (and other scientific libraries) really shines when dealing with more than one element. For example, model inference, matrix multiplication, or pandas dataframe computations are much faster if done in batch. One way of getting quick gains in scaling is to create a batch prediction endpoint for a service:
from fastapi import FastAPI
from typing import List
from pipeline import model,
clean_data,
format_data,
data_is_valid
app = FastAPI()
@app.post("/batch-predict/")
async def predict(items: List[str]):
items = list(set(items)) # <- remove duplicates
items = [i for i in items
if data_is_valid(i) == True] # <- leverage list comprehensions
items = clean_data(items) # <- probably has some numpy or pandas
predictions = model.predict(items) # <- faster and more efficient than calling .predict N times
outputs = format_data(predictions)
return outputsBy creating a batch prediction endpoint, you are doing a lot of the work that would normally be up to the API caller. However, you are also improving the efficiency of your microservice. If your app scales well, calling the batch-predict endpoint once will be much faster than calling the predict endpoint N times.
5. Bonus
Here are 3 bonus tips to help improve the performance of your service:
- Look into pruning: pruning trims insignificant weights from your model, making it smaller and likely faster to operate.
- Optimization frameworks: leveraging Apache TVM and ONNX can significantly optimize both the speed and size of your model.
- Leverage Python: we’ve talked about Threads and Processes, but tools like
lru_cachecan also help speed up your service, especially if you are making external API calls. Staying up-to-date with the latest software can also make your application faster. Python 3.11, for example, is 10-60% faster than Python 3.10.
Conclusion
There’s still no way to automagically scale your custom Machine learning microservice. Nevertheless, this article has given you a wide range of solutions that will help you easily scale a microservice to thousands (or even millions) of users.
The best technique to optimize really depends on your use case. Are costs a concern? Then stay away from GPUs. Do you receive a lot of repeated calls? Then leverage a batch endpoint. Is your Cloud Function (e.g., FaaS) slow? Perhaps it’s time to choose another service, like PaaS (e.g., Cloud Run).
It’s not worth optimizing just for optimization sake. Remember, perfect is the enemy of good. Focus on serving your users, and optimize when you encounter a performance bottleneck. Hopefully, the tips above are a good menu to choose from.
