Running a microservice infrastructure involves a wide variety of organizational and technical challenges, many of them regarding the communication between services. Traditionally, operations and developer teams take care of these challenges and implement their own solutions. But there is a more unified, standardized, and scalable way: service meshes.
This article introduces the concept of service meshes, the problems they solve, and the features they offer. As Kubernetes is a widespread and well-understood platform for running microservice infrastructures, we’re going to focus on service meshes built for Kubernetes.
Challenges in microservice environments
While calls to other modules within a monolithic application are simple in-memory operations, calling a service in a microservice-based application is more complex. Communicating with another service entails real network calls, which inherently introduce their own class of problems.
Consequently, developers need to answer a variety of questions when building a microservice architecture:
- Must the network communication between the services be encrypted?
- How can a service make sure that it is communicating with the correct peer service?
- Which services are allowed to communicate with each other? How can these rules be enforced?
- How should resilience features such as retries or service timeouts be implemented?
- What does traffic management look like, e.g. load balancing or routing traffic to a newer service version?
A service mesh is an infrastructure layer that addresses these problems in a holistic and standardized way. There are plenty of service meshes available, the most popular ones being Google’s Istio, HashiCorp’s Consul, and Buoyant’s Linkerd.
How service meshes for Kubernetes work
All popular service mesh implementations for Kubernetes follow the same fundamental idea: they deploy a network proxy next to each service instance. Note that my use of the term “service” here refers to the actual microservice, not a Kubernetes Service. These network proxies intercept the service’s network traffic, and they are the precise point where all service mesh features are enforced. To accomplish this, a service mesh has a control plane and a data plane.
Control plane and data plane
The data plane consists of a large number of proxy servers, each of them sitting next to a single service instance. The service mesh automatically injects those proxy servers into the Kubernetes pods of the service. In Kubernetes terms, the proxies are sidecar containers, thus they are also referred to as sidecar proxies.
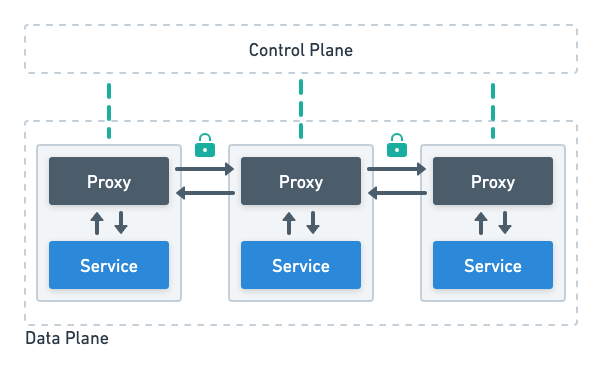
Outbound requests of a service are intercepted by the proxy server within its own pod. The proxy then establishes an encrypted connection with the target service. Because inbound requests are intercepted as well, the actual connection will be established with the target service’s proxy. Once the connection is established, the service mesh features can be applied.
The control plane consists of components that are responsible for controlling the proxies in the data plane. It is aware of all services and the networking constraints imposed on them and provides this information to the sidecar proxies. In most cases, the control plane is a simple Kubernetes namespace.
Advantages
This approach comes with several advantages for the operation of existing services and the adoption of new ones.
First, networking policies and features are managed in a central place: the control plane. The services themselves are no longer in charge of networking security, resilience, observability, and traffic management. This means that such capabilities don’t need to be implemented within the services anymore, which enables developers to focus on business capabilities instead. Thus, building new services will become cheaper and less networking-heavy.
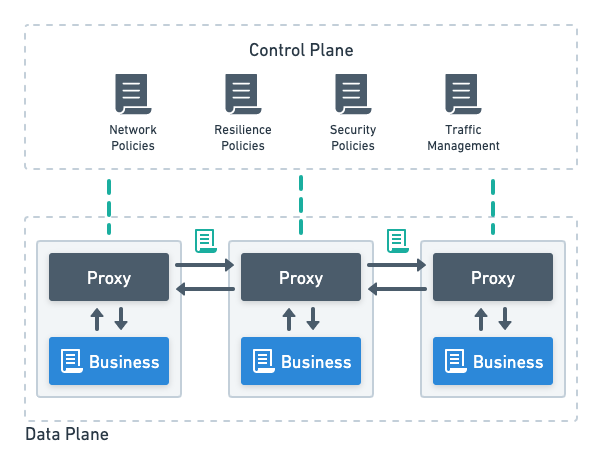
Also, the networking policies are first-class Kubernetes resources. They are not implemented as obscure application code within the service, rather they are defined in a declarative and uniform fashion. This means that the networking configuration is standardized across all services in the infrastructure and even across Kubernetes clusters. Making networking behavior transparent to other parts of the organization, such as operations teams, is a major step towards improved reliability.
Drawbacks
There are some drawbacks that should be considered when adapting a service mesh. Injecting a sidecar proxy into all Kubernetes pods has significant implications. The infrastructure is expanded by n proxy servers, where n is the number of service instances. Each proxy server consumes additional CPU and memory resources, and each service call will be extended by two proxy hops. This is considerable operational overhead.
Also, besides understanding their services and Kubernetes, developers also need to understand how the service mesh works. Figuring out whether a feature is already covered by the service mesh or needs to be implemented in the application, troubleshooting the application, setting up a deployment workflow for the service mesh itself – all of these require thorough knowledge about the service mesh.
Features
By intercepting both inbound and outbound traffic, the service mesh has full control over inter-service communication. The exact feature set depends on the particular service mesh implementation, but there are capabilities that most service meshes have in common.
Security
Standardized security policies are one of the greatest advantages of service meshes. There are three security aspects taken into account by service meshes: encrypted inter-service communication, service-to-service authentication, and authorization of inter-service communication.
Encrypted inter-service communication
Service meshes provide encrypted inter-service communication via mutual TLS (mTLS). Typically, the service mesh assigns a unique certificate to each service. For outbound requests, the client service verifies the identity of the target service using the service mesh’s certificate authority. After the target service has successfully verified the certificate of the client service, an encrypted connection is established.
Requesting the certificate data from the certificate authority in the control plane is a time-consuming operation. To circumvent this, some service meshes deploy local node agents that keep an in-memory copy of the certificates that are kept up-to-date by the control plane. According to their vendors, this shortens the certificate checks to a few microseconds.
Service-to-service authentication
A connection encrypted via mTLS not only allows for secure communication, it also enables identity-based communication between services, so that a service is guaranteed to communicate with the expected peer service. To check this, each service is equipped with an X.509 identity and uses this identity to authenticate itself against other services.
Service-to-service authentication also paves the way for authorized inter-service communication.
Authorized inter-service communication
It is common practice not to allow inter-service communication by default. Services that need to communicate with each other should be explicitly authorized to do so. In traditional setups, this is oftentimes checked manually within the service: client services have to authenticate themselves using a service token, and they have to be “whitelisted” by the target service for the communication to be permitted.
Services within a service mesh are uniquely identified using service-to-service authentication. This enables the service mesh to allow or disallow traffic between two defined services. For example, Consul uses intentions to authorize inter-service communication. The following Kubernetes manifest allows a service called web to communicate with an api service:
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceIntentions
metadata:
name: web-to-api
spec:
destination:
name: api
sources:
- name: web
action: allowA Kubernetes manifest is a declarative and standardized specification, as opposed to custom-built application code that performs these checks.
Resilience
A service mesh shifts all networking capabilities into their own infrastructure layer. This also means that resilience features can be handled by the service mesh – primarily retries and timeouts.
Retries and timeouts
Requested services may not respond within a defined timeout period or become unavailable. In these cases, it might make sense to retry the request. In a microservice environment, where everything happens via network calls, retries and timeouts are fundamental building blocks for resilience.
Implementing a proper retry mechanism isn’t a trivial task. The developer must decide how many retry attempts are appropriate, and how long the intervals between the retries should be. This is a difficult trade-off to make: on the one hand, the number of retries should be enough for the client to get an actual response; on the other hand, too many retries cause a flood of traffic that the target service can’t handle, making it unavailable again. These retry storms are a serious threat to any distributed system.
Some service meshes provide an intelligent and data-driven solution for finding a proper balance: for instance, Linkerd monitors the ratio between normal requests and retry requests. Retry requests are only allowed if this ratio is below a previously defined limit–the so-called retry budget. For a retry budget of 25%, the proxies will only perform retries until the extra load on the target service exceeds 25%. The service itself doesn’t notice these retries.
Fault injection
To thoroughly test resilience and stability when a fault occurs, certain service meshes have built-in fault injection as a form of chaos engineering. Fault injection artificially increases the number of erroneous responses, exposing how the system copes with them.
Just as with automatic retries, fault injection doesn’t require any changes in the application code.
Traffic management
Intercepting network traffic empowers the service mesh to manage it. There are various kinds of traffic management that meet different demands.
Traffic routing
Service meshes are capable of routing traffic based on Layer 7 criteria such as HTTP methods, request headers, or path prefixes. Depending on these criteria, requests may be routed to different backends. In Consul, routing all HTTP requests with a payment path prefix to a service called payment would look as follows:
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceRouter
metadata:
name: web
spec:
routes:
- match:
http:
pathPrefix: /payment
destination:
service: paymentSuch routing would also be possible using Kubernetes itself. However, service meshes have built-in support for more complex use cases, such as canary deployments.
Traffic splitting and canary deployments
After routing the traffic to a service, the service mesh can additionally split it. That is, the traffic can be split among two or more instances of the respective service, e.g. the first request goes to instance #1, while the next request goes to instance #2, and so on.
There are various criteria for how the traffic should be split, and which service instances should be considered as targets. For instance, weighting could be used for splitting and service versions could be used for target selection, e.g. 80% of the traffic should be routed to instances running version 1.0 of the service, and 20% of the traffic should go to instances running version 2.0.
This mechanism facilitates rollout strategies such as canary or blue-green deployments. In the aforementioned example, service version 2.0 could be tested on 20% of the users.
Traffic mirroring
Besides splitting traffic between peer service instances, it can also be cloned (or mirrored) among service instances. These service instances don’t necessarily need to be in the same environment. For testing purposes, traffic from the production environment could be mirrored to a new service version in the staging environment. Testing new versions with real production workloads allows for much more confident releases and deployments.
Observability
Because all inter-service communication is taking place within the data plane, the service mesh knows the behavior of the services. Thus, collecting service and network metrics is a breeze.
The majority of service meshes collect the “golden metrics” – request success rates, requests per second, and latency – and supply a built-in dashboard for this data. Where these metrics are sent to depends on the service mesh and can usually be customized.
Since a service mesh spans the entire microservice infrastructure, it is able to capture and visualize the topology of the infrastructure. Visualizing the topology along with configured inter-service communication can give helpful insights about the infrastructure.
Conclusion
A service mesh promotes inter-service communication to a first-class citizen. Networking between services is no longer implemented manually as language-specific application code, potentially opaque to other teams. Instead, its behavior is clearly defined in a declarative, organization-wide, language-agnostic, and standardized way.
There is, however, a cognitive and operational overhead to service meshes and organizations have to carefully gauge whether they need to make this trade-off. In any case, inter-service communication is one of the most critical paths in any distributed system, and moving it into a dedicated layer does justice to it.