Kubernetes is a fantastic platform to run resilient applications and services at scale. But let’s face it, getting started with Kubernetes can be challenging. The path that code must take from the repository to a Kubernetes cluster can be dark and full of terrors.
But fear not! Continuous integration and Delivery (CI/CD) come to the rescue. In this article, we’ll learn how to combine Semaphore with AWS Elastic Container Registry (ECR) and Kubernetes Service (EKS) to get a fully-managed cluster in a few minutes.
What We’re Building
We’re going to set up CI/CD pipelines to fully automate container creation and deployment. By the end of the article, our pipeline will be able to:
- Install project dependencies.
- Run unit tests.
- Build and tag a Docker image.
- Push the Docker image to Amazon Container Registry.
- Provide a one-click deployment to Amazon Kubernetes.
As a starting point, we have a Ruby Sinatra microservice that exposes a few HTTP endpoints. We’ll go step by step, doing some modifications along the way to make it work in the Amazon ecosystem.
What You’ll Need
Before doing anything, you’ll need to sign up for a few services:
Also, you should install some tools on your machine as well:
- Git: to handle the code.
- curl: the Swiss Army knife of networking.
- Docker: to build the containers.
- eksctl: to create the Kubernetes cluster on Amazon.
- kubectl: to manage the cluster.
- aws-iam-authenticator: required by AWS to connect to the cluster.
With that out of the way, we’re ready to get started. Let’s begin!
Fork the Repository
As an example, we’re going to use a Ruby Sinatra application as it provides a minimal API service and includes a simple RSpec test suite.
You can get the code by cloning the repository:
- Go the semaphore-demo-ruby-kubernetes repository and click the Fork button on the top right side.
- Click the Clone or download button and copy the address.
- Open a terminal in your machine and clone the repository:
$ git clone https://github.com/your_repository_urlBuild a Container
Before we can run our app in the cluster, we need to build a container for it. Applications packaged in a container can be easily deployed anywhere. Docker, the industry standard for containers, is supported by all cloud providers.
Our Docker image will include Ruby, the app code, and all the required libraries.
Take a look a the Dockerfile:
FROM ruby:2.5
RUN apt-get update -qq && apt-get install -y build-essential
ENV APP_HOME /app
RUN mkdir $APP_HOME
WORKDIR $APP_HOME
ADD Gemfile* $APP_HOME/
RUN bundle install --without development test
ADD . $APP_HOME
EXPOSE 4567
CMD ["bundle", "exec", "rackup", "--host", "0.0.0.0", "-p", "4567"]The file goes through all the required steps to build and start the microservice.
To build the image:
$ docker build -t semaphore-demo-ruby-kubernetes .Once completed, the new image will look like this:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
semaphore-demo-ruby-kubernetes latest d15858433407 2 minutes ago 391MBWithin the container, the app listens on port 4567, so we should map it to port 80 in your machine:
$ docker run -p 80:4567 semaphore-demo-ruby-kubernetesOpen a second terminal to check out the endpoint:
$ curl -w "\n" localhost
hello world :))We’re off to a good start. Can you find any other endpoints in the app?
The CI/CD Workflow
To automate the whole testing, building and deploying process, we’re going to use our powerful continuous integration and delivery platform.
We’ll use Semaphore to automatically:
- Install and cache dependencies.
- Run unit tests.
- Continuously build and tag a Docker container.
- Push container to Amazon Container Registry.
On manual approval:
- Deploy to Kubernetes.
- Tag the latest version of the container and push it to the registry.
Set up Semaphore
Setting up Semaphore to work with our code is super easy:
- Login to your Semaphore account.
- Use the + (plus sign) button next to Projects:
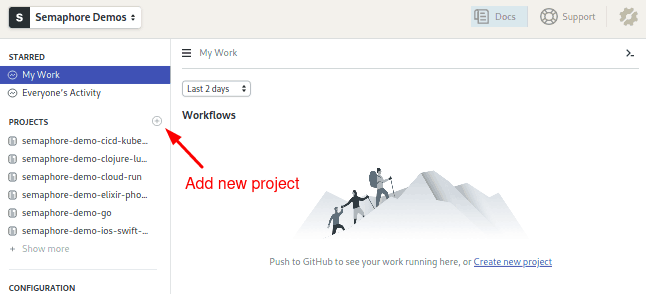
- Semaphore will show your GitHub repositories, click on Choose to add CI/CD to it:
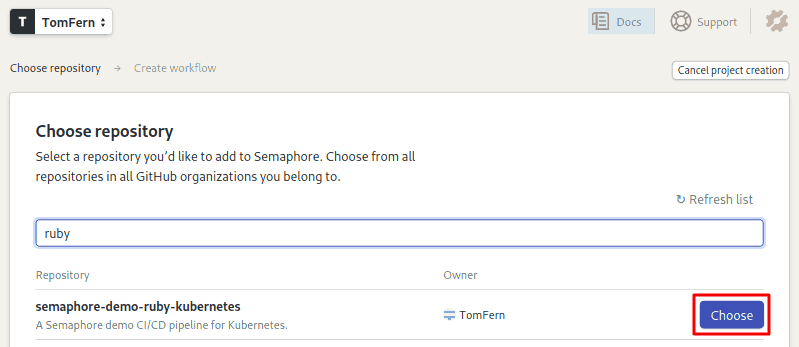
- Select the option: I will use the existing configuration.
Our repository has a starter CI/CD configuration. Semaphore should pick it up once you make any modification:
- Open a new window on GitHub and go to your repository.
- Use the Create new file button to create an empty file:
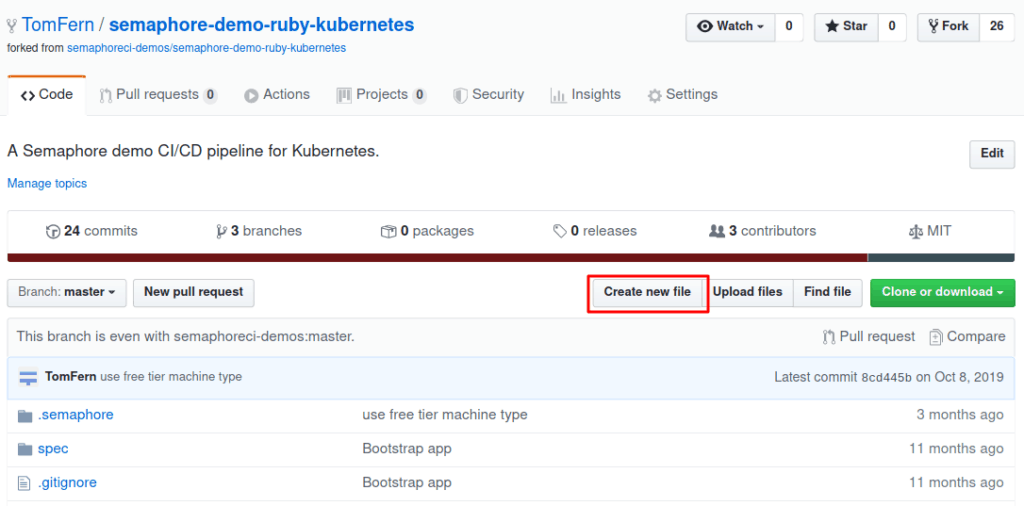
- Type any file name and use Commit to add the file.
- Go back to Semaphore and you’ll find that the CI/CD process has already started:
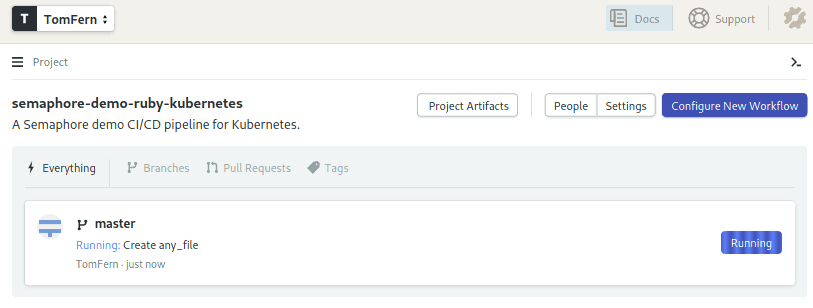
We have some sample Semaphore pipelines already included in our app. Unfortunately, they weren’t planned for AWS. No matter—we’ll make new ones.
For now, let’s delete the components we won’t need:
- Click on master branch.
- Click on Edit Workflow to bring up the Workflow Builder UI:
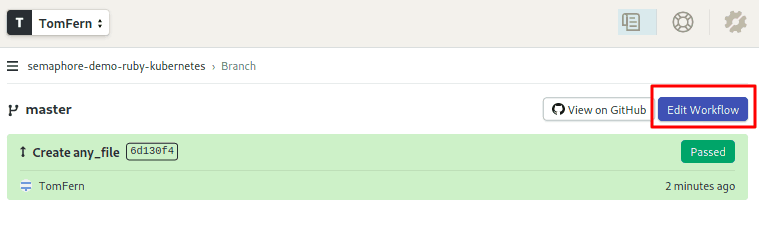
- Scroll right to the Promotions box.
- Click on the Dockerize and use the Delete Promotion to delete the deployment pipelines:
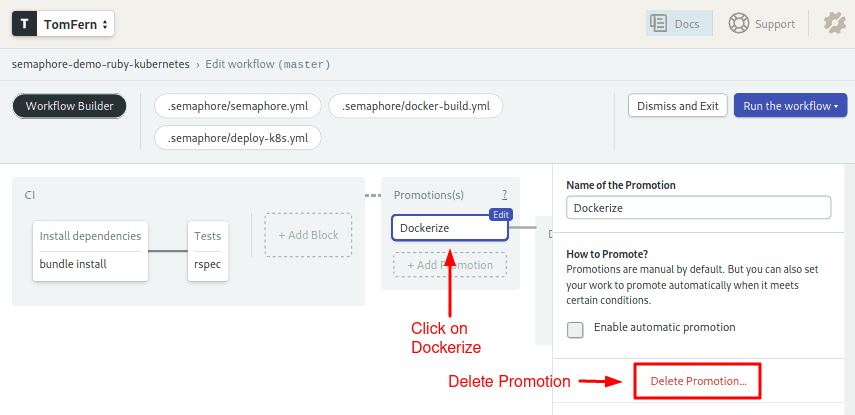
Why are we doing this? Amazon does things in its own way; the generic deployment that comes with the demo won’t work. The good news, is that we get to create one from scratch.
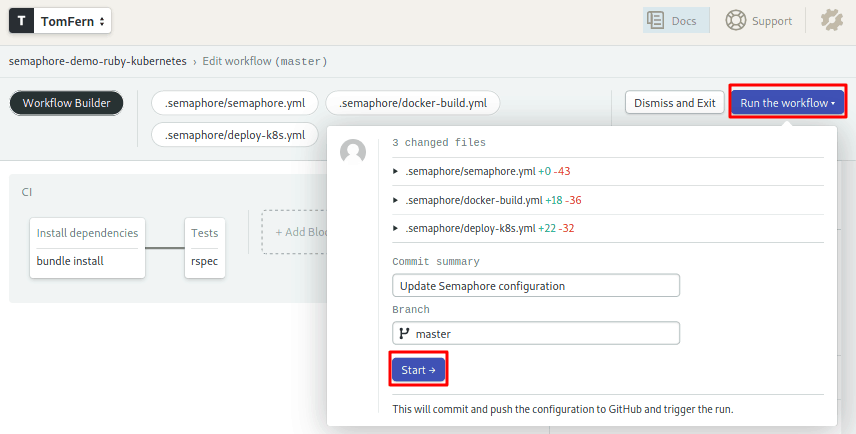
Save your changes:
- Click on Run the workflow.
- Click on Start.
The CI process starts again. This time, sans any deployment steps:
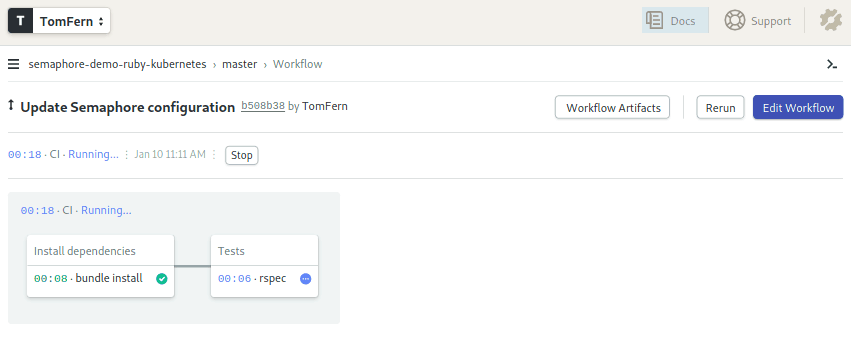
The CI Pipeline
With Semaphore Continuous Integration (CI), we can continually test our code. Each time we make a modification and push it to GitHub. Semaphore will run the test we setup. That way, we’ll have immediate feedback when we introduce a failure.
Click on Edit Workflow again to examine how the CI pipeline works.
Name and Agent
Click on the CI Pipeline gray box:
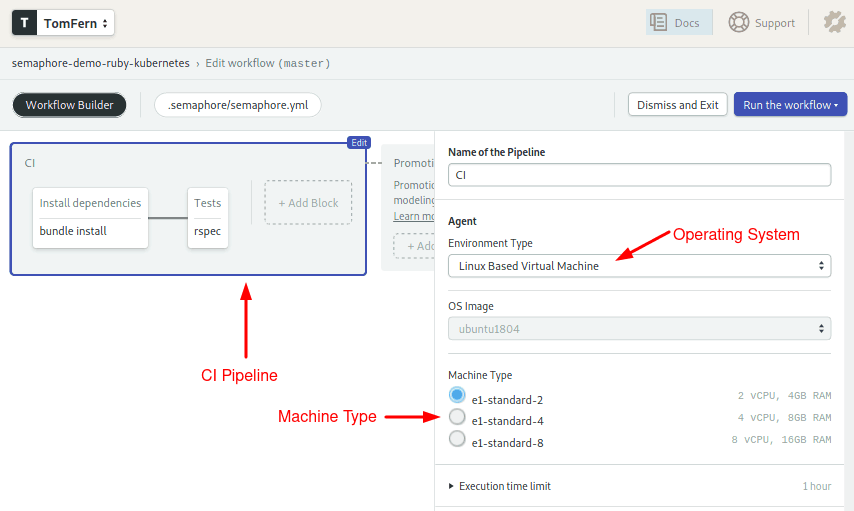
The pipeline begins with a declaration of name and agent. The agent defines which of the available machine types will drive the jobs. For the operating system, we’ll use an Ubuntu 18.04.
Install dependencies block
Blocks and jobs define what to do at each step of the pipeline. On Semaphore, blocks run sequentially, while jobs within a block run in parallel. The pipeline contains two blocks, one for installation and another for for running tests.
Click on the Install dependencies block:
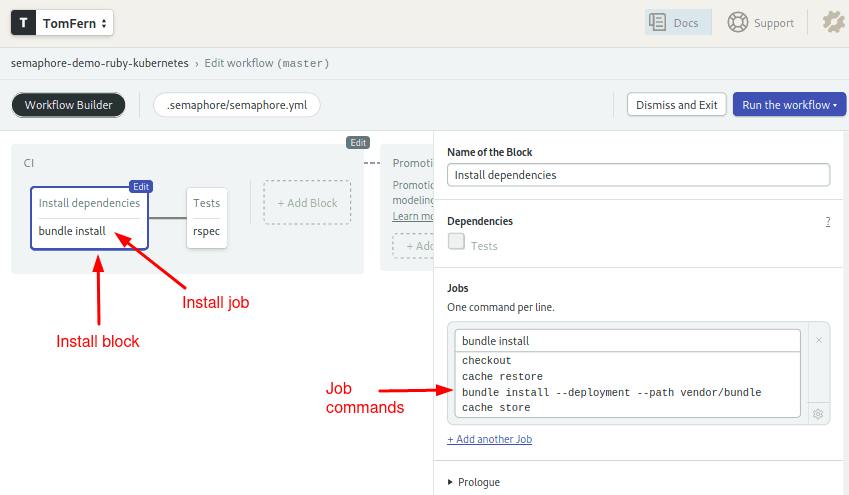
The first block downloads, installs, and caches the Ruby gems:
checkout
cache restore
bundle install --deployment --path vendor/bundle
cache storeThe checkout command clones the code from GitHub. Since each job runs in a fully isolated machine, we must use the cache utility to store and retrieve files between jobs.
Tests block
The second block runs the unit tests:
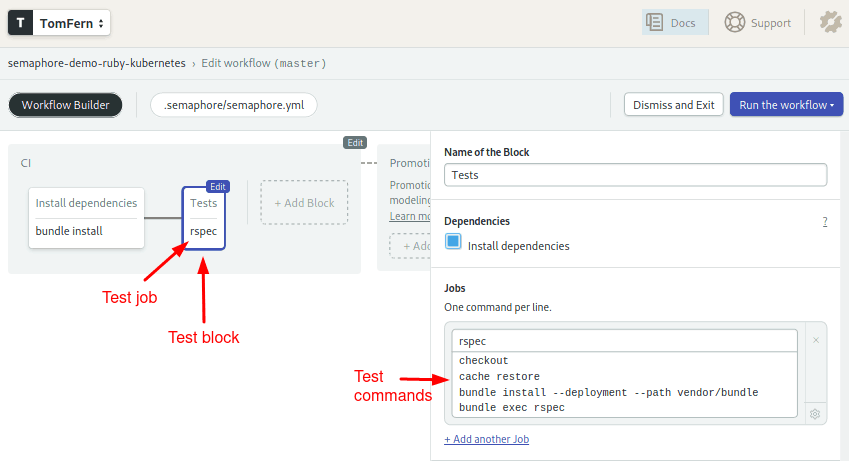
Notice that we repeat checkout and cache to get the files into the job. The project includes RSpec code that tests the API endpoints:
checkout
cache restore
bundle install --deployment --path vendor/bundle
bundle exec rspBuild and Push Images to the Registry
In this section, we’re going to create a Semaphore pipeline to build Docker images and store them in an Amazon container registry.
Create an IAM User
Since Amazon vehemently recommends creating additional users to access its services, let’s start by doing that:
- Go to the AWS IAM Console
- On the left menu go to Users
- Click the Add user button
- Type “semaphore” on the user name
- Select Programmatic Access. Click Next: Permissions.
- Click on Attach existing policies directly.
- Open the Filter policies menu: check AWS managed – job function.
- Select AdministratorAccess policy. Go to Next: Tags.
- You may add any optional tags to describe the user. Go to Next: Review.
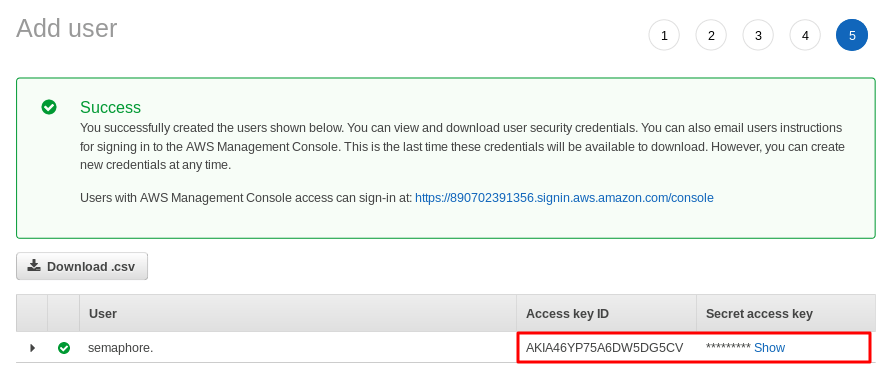
- Click Next and then Create user.
- Copy and save information displayed: Access Key ID and Secret access key
Create a Container Registry (ECR)
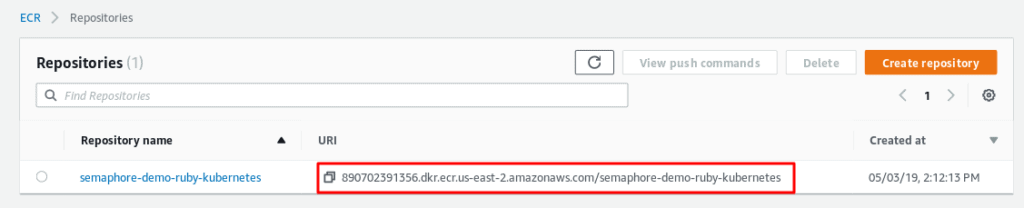
To store our Docker images, we are going to use Amazon Elastic Container Registry (ECR):
- Open AWS ECR dashboard.
- Click the Create repository button.
- Type a registry name: “semaphore-demo-ruby-kubernetes”
- Copy the new registry URI.
Push Your First Image to ECR
Being a private registry, we need to authenticate with Amazon. We can get a docker login command with:
$ aws ecr get-login --no-include-email
docker login -u AWS -p REALLY_LONG_PASSWORD https://....Tag your app image with the ECR address:
$ docker tag semaphore-demo-ruby-kubernetes "YOUR_ECR_URI"And push it to the registry:
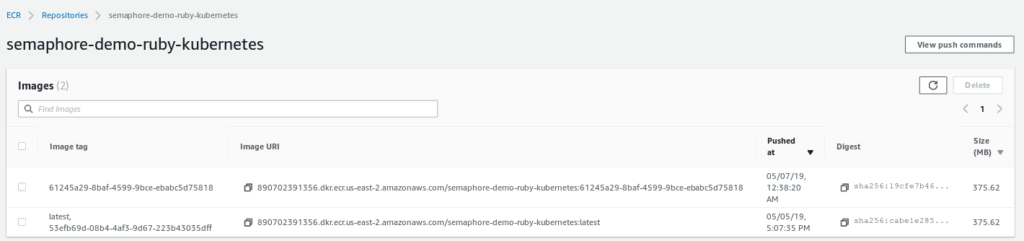
$ docker push "YOUR_ECR_URI"Wait a few minutes for the image to be uploaded. Once done, check your ECR Console:

The build docker pipeline
Connect Semaphore to AWS
We need to supply Semaphore with the access keys to our Amazon services. Semaphore provides a secure mechanism to store sensitive information such as passwords, tokens, or keys.
Semaphore can encrypt data and files and make them available to the pipeline when required.
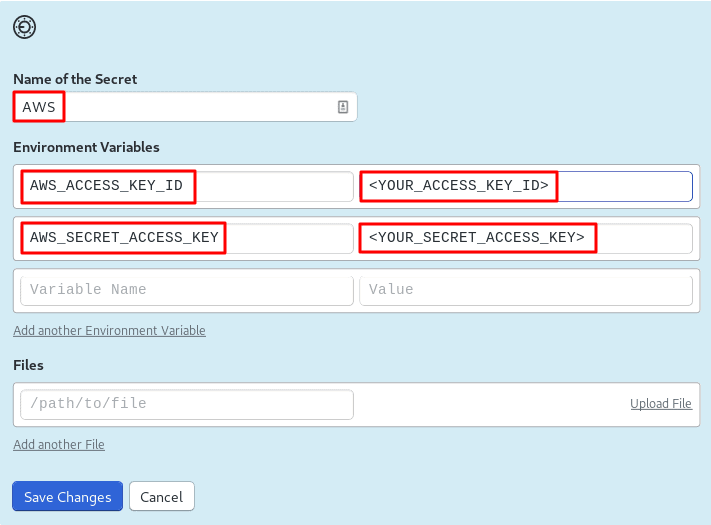
- Go to your Semaphore account.
- On the left navigation bar, under Configuration, click on Secrets.
- Hit the Create New Secret button.
- Create the AWS secret. Use access keys for the semaphore IAM user you created earlier:
Create the Docker Build Pipeline
In this section, we’ll tell Semaphore how to build a Docker image. We’ll do it by creating a new Dockerize pipeline.
We can create multiple pipelines and connect them together with promotions:
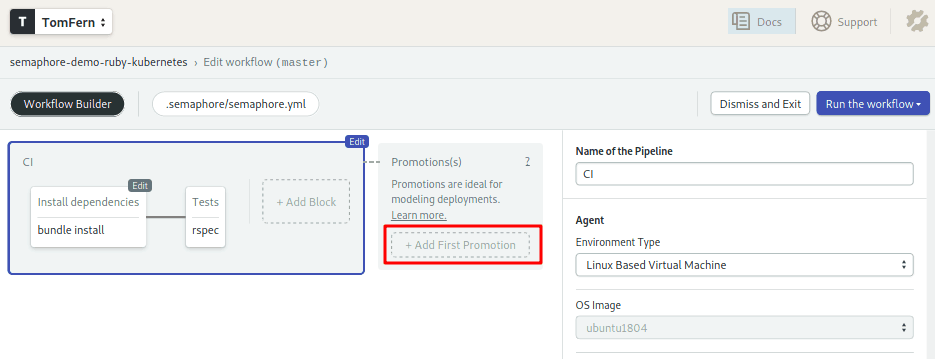
- Click on Edit Workflow.
- Scroll right to the end of the CI Pipeline.
- Click on the + Add first promotion dotted line box:
- Set the name of the pipeline to: “Dockerize”.
- Check the Enable automatic promotion option. This will trigger the Dockerize pipeline automatically if all tests pass:

Configure the Dockerize pipeline:
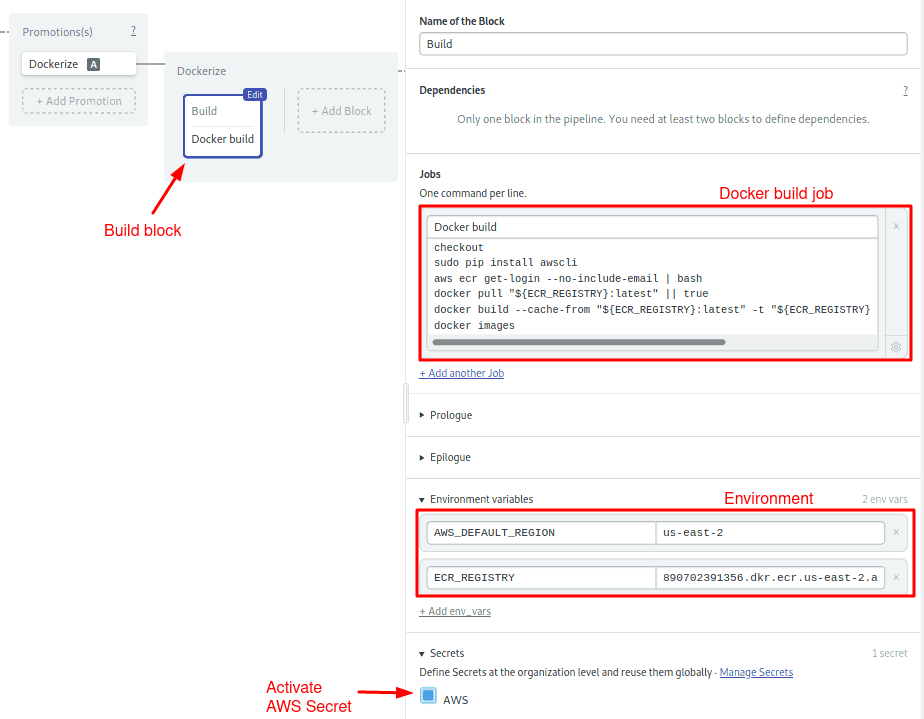
- Click on the new pipeline and name it: “Dockerize”. Ensure that the agent is Ubuntu and the machine is e1-standard-2.
- Click on the first block on the new pipeline, the one called Block #1.
- Rename the block: “Build”.
- Under the job section, change the name of the job to: “Docker build”
- Type the following commands in the box:
checkout
sudo pip install awscli
aws ecr get-login --no-include-email | bash
docker pull "${ECR_REGISTRY}:latest" || true
docker build --cache-from "${ECR_REGISTRY}:latest" -t "${ECR_REGISTRY}:${SEMAPHORE_WORKFLOW_ID}" -t Dockerfile.ci .
docker images
docker push "${ECR_REGISTRY}:${SEMAPHORE_WORKFLOW_ID}"- Open the Secrets section and check the AWS secret.
- Open the Environment Variables section. Use + Add env_vars to create two variables:
AWS_DEFAULT_REGION= YOUR_AWS_REGION (e.g. us-east-2)
ECR_REGISTRY= YOUR_ECR_URI (the address of your ECR repository)
The build job does the bulk of the work:
- Gets the code with
checkout. - Installs the
awsclitool. - Gets a login token for the ECR service.
awscliaccess the access keys from the AWS secret. Once logged in, Docker can directly access the registry. docker pullattempts to retrieve the latest image in ECR. If the image is found, Docker may be able to reuse some of its layers.docker buildgenerates the new image. Notice here we’re using a $SEMAPHORE_WORKFLOW_ID to tag the image. This is a built-in Semaphore variable that is unique for every workflow. In addition, we’re using a different Dockerfile, one that fetches the base image from Semaphore Container Registry, which is faster than the public Docker registry and isn’t affected by any rate limits.docker pushuploads the image to ECR.
To make your first automated build, save the workflow:
- Click on Run the Workflow on the top-right corner.
- Click Start.
After a few seconds the workflow will complete:
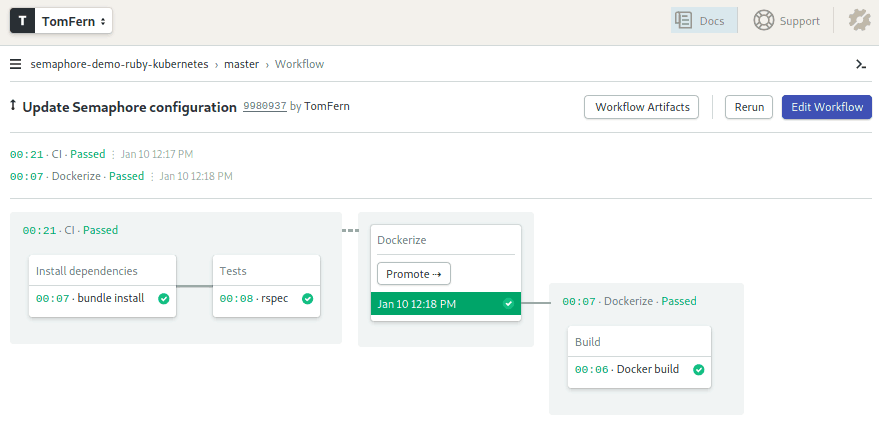
And you should also find a new image uploaded to ECR:
Deploy to Kubernetes
Kubernetes is an open-source platform to manage containerized applications. We’re going to use Amazon Elastic Container Service for Kubernetes (EKS) for our cluster.
Create a SSH Key
You’ll need to create an SSH key to access the cluster nodes. If you don’t have a key, creating one is easy:
$ ssh-keygenJust follow the on-screen instructions. When asked for a passphrase, leave it blank. A new key pair will be created in $HOME/.ssh.
Create the Cluster
Creating a Kubernetes cluster manually is really hard work. Fortunately, eksctl comes to the rescue:
$ eksctl create cluster
[ℹ] using region us-east-2
[ℹ] setting availability zones to [us-east-2c us-east-2a us-east-2b]
[ℹ] subnets for us-east-2c - public:192.168.0.0/19 private:192.168.96.0/19
[ℹ] subnets for us-east-2a - public:192.168.32.0/19 private:192.168.128.0/19
[ℹ] subnets for us-east-2b - public:192.168.64.0/19 private:192.168.160.0/19
[ℹ] nodegroup "ng-c592655b" will use "ami-04ea7cb66af82ae4a" [AmazonLinux2/1.12]
[ℹ] creating EKS cluster "floral-party-1557085477" in "us-east-2" region
[ℹ] will create 2 separate CloudFormation stacks for cluster itself and the initial nodegroup
[ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=us-east-2 --name=floral-party-1557085477'
[ℹ] 2 sequential tasks: { create cluster control plane "floral-party-1557085477", create nodegroup "ng-c592655b" }
[ℹ] building cluster stack "eksctl-floral-party-1557085477-cluster"
[ℹ] deploying stack "eksctl-floral-party-1557085477-cluster"
[ℹ] buildings nodegroup stack "eksctl-floral-party-1557085477-nodegroup-ng-c592655b"
[ℹ] --nodes-min=2 was set automatically for nodegroup ng-c592655b
[ℹ] --nodes-max=2 was set automatically for nodegroup ng-c592655b
[ℹ] deploying stack "eksctl-floral-party-1557085477-nodegroup-ng-c592655b"
[✔] all EKS cluster resource for "floral-party-1557085477" had been created
[✔] saved kubeconfig as "~/.kube/aws-k8s.yml"
[ℹ] adding role "arn:aws:iam::890702391356:role/eksctl-floral-party-1557085477-no-NodeInstanceRole-GSGSNLH8R5NK" to auth ConfigMap
[ℹ] nodegroup "ng-c592655b" has 1 node(s)
[ℹ] node "ip-192-168-65-228.us-east-2.compute.internal" is not ready
[ℹ] waiting for at least 2 node(s) to become ready in "ng-c592655b"
[ℹ] nodegroup "ng-c592655b" has 2 node(s)
[ℹ] node "ip-192-168-35-108.us-east-2.compute.internal" is ready
[ℹ] node "ip-192-168-65-228.us-east-2.compute.internal" is ready
[ℹ] kubectl command should work with "~/.kube/config", try 'kubectl --kubeconfig=~/.kube/config get nodes'
[✔] EKS cluster "floral-party-1557085477" in "us-east-2" region is readyAfter about 15 to 20 minutes, we should have an EKS Kubernetes cluster online. Perhaps you’ve noticed that eksctl christened our cluster with an auto-generated name; for instance, I got “floral-party-1557085477”. We can set additional options to change the number of nodes, machine type or to set a boring name:
$ eksctl create cluster --nodes=3 --node-type=t2.small --name=just-another-appFor the full list of options, check the eksctl website.
Shall we check out the new cluster?
$ eksctl get cluster --name=floral-party-1557085477
NAME VERSION STATUS CREATED VPC
floral-party-1557085477 1.12 ACTIVE 2019-05-05T19:47:14Z vpc-0de007519690e492e ...$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-35-108.us-east-2.compute.internal Ready <none> 3h v1.12.7
ip-192-168-65-228.us-east-2.compute.internal Ready <none> 3h v1.12.7If you get an error saying that aws-iam-authenticator is not found, it’s likely that the is some problem with the authenticator component. Check the aws-iam-authenticator page for installation instructions.
Deployment Pipeline
We’re entering the last stage of CI/CD configuration. At this point, we have a CI pipeline and a Docker pipeline. We’re going to define a third pipeline to deploy to Kubernetes.
Create Secret for Kubectl
During the creation of the cluster, eksctl created a config file for kubectl. We need to upload it to Semaphore. The config has the access keys required to connect to Kubernetes.
Back on Semaphore, create a new secret and upload $HOME/.kube/config:
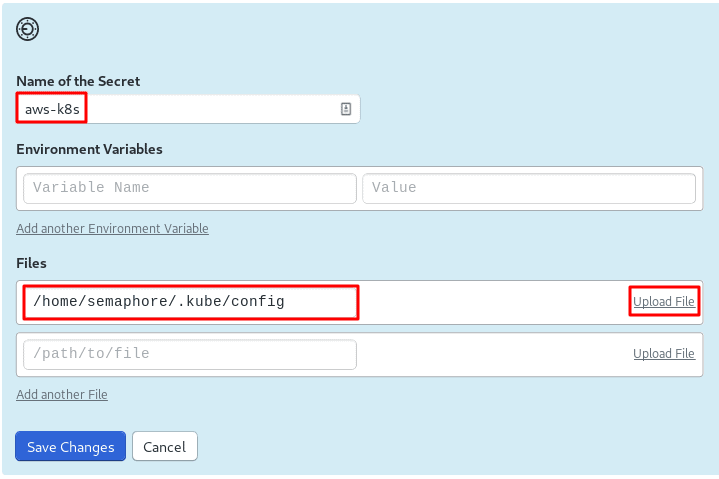
The Deployment Manifest
Automatic deployment is Kubernetes’ strong suit. All you need is a manifest with the resources you want online. We want to create two services:
- A load balancer that listens to port 80 and forwards HTTP traffic to application:
apiVersion: v1
kind: Service
metadata:
name: semaphore-demo-ruby-kubernetes-lb
spec:
selector:
app: semaphore-demo-ruby-kubernetes
type: LoadBalancer
ports:
- port: 80
targetPort: 4567- And the application container:
apiVersion: apps/v1
kind: Deployment
metadata:
name: semaphore-demo-ruby-kubernetes
spec:
replicas: 1
selector:
matchLabels:
app: semaphore-demo-ruby-kubernetes
template:
metadata:
labels:
app: semaphore-demo-ruby-kubernetes
spec:
containers:
- name: semaphore-demo-ruby-kubernetes
image: "${ECR_REGISTRY}:${SEMAPHORE_WORKFLOW_ID}"
imagePullSecrets:
- name: aws-ecr
You may have noticed that we used environment variables in the app manifest; this is not compliant with the YAML format, so the file, as it is, won’t work. That’s all right–we have a plan.
Create a deployment.yml with both resources separated with ---:
apiVersion: v1
kind: Service
metadata:
name: semaphore-demo-ruby-kubernetes-lb
spec:
selector:
app: semaphore-demo-ruby-kubernetes
type: LoadBalancer
ports:
- port: 80
targetPort: 4567
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: semaphore-demo-ruby-kubernetes
spec:
replicas: 1
selector:
matchLabels:
app: semaphore-demo-ruby-kubernetes
template:
metadata:
labels:
app: semaphore-demo-ruby-kubernetes
spec:
containers:
- name: semaphore-demo-ruby-kubernetes
image: "${ECR_REGISTRY}:${SEMAPHORE_WORKFLOW_ID}"
imagePullSecrets:
- name: aws-ecr
Deploying the Application
In this section, we’ll make the first deployment to the cluster. If you’re in a hurry, you may want to skip this section and go right ahead to the automated deployment.
Request a password to connect to ECR:
$ export ECR_PASSWORD=$(aws ecr get-login --no-include-email | awk '{print $6}')Send the username and password to the cluster.
$ kubectl create secret docker-registry aws-ecr \
--docker-server=https://<YOUR_ECR_URI> \
--docker-username=AWS --docker-password=$ECR_PASSWORD
$ kubectl get secret aws-ecrNext, create a valid manifest file. If you have envsubst installed on your machine:
$ export SEMAPHORE_WORKFLOW_ID=latest
$ export ECR_REGISTRY=<YOUR_ECR_URI>
$ envsubst < deployment.yml > deploy.ymlOtherwise, copy deployment.yml as deploy.yml and manually replace $SEMAPHORE_WORKFLOW_ID and $ECR_REGISTRY.
Then, send the manifest to the cluster:
$ kubectl apply -f deploy.ymlCheck the cluster status:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
semaphore-demo-ruby-kubernetes 1 1 1 1 1hGet the cluster external address for “semaphore-demo-ruby-kubernetes-lb”:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 31h
semaphore-demo-ruby-kubernetes-lb LoadBalancer 10.100.108.157 a39c4050a6f7311e9a6690a15b9413f1-1539769479.us-east-2.elb.amazonaws.com 80:32111/TCP 31hFinally, check if the API endpoint is online:
$ curl -w "\n" YOUR_CLUSTER_EXTERNAL_URL
hello world :))Superb!
Create deployment pipeline
Time to automate the deployment. Create a new pipeline:
- Click Edit Workflow.
- Click on the Dockerize promotion to open it.
- Scroll to the rightmost side
- Click on +Add First Promotion.
- Name your promotion: “Deploy to Kubernetes”.
- Click on the new pipeline, name it “Deploy to Kubernetes”.
- Click on the first block. Name the block: “Deploy”:
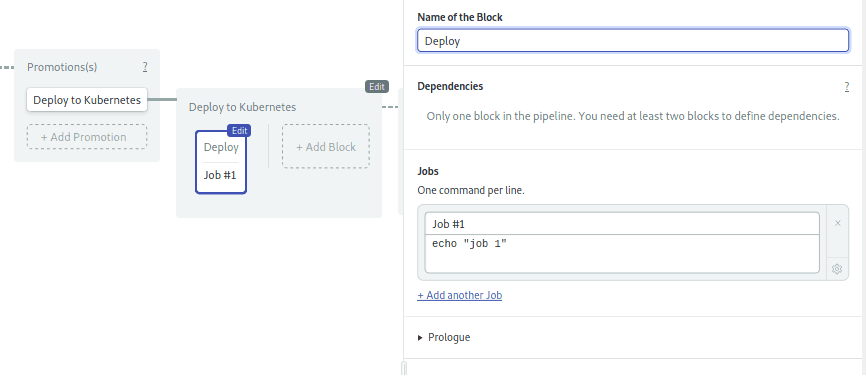
- Set the name of the job to “Deploy” and type the following commands in the box:
checkout
mkdir -p ~/bin
curl -o ~/bin/aws-iam-authenticator https://amazon-eks.s3-us-west-2.amazonaws.com/1.12.7/2019-03-27/bin/linux/amd64/aws-iam-authenticator
chmod a+x ~/bin/aws-iam-authenticator
export PATH=~/bin:$PATH
sudo pip install awscli
export ECR_PASSWORD=$(aws ecr get-login --no-include-email | awk '{print $6}')
kubectl delete secret aws-ecr || true
kubectl create secret docker-registry aws-ecr --docker-server="https://$ECR_REGISTRY" --docker-username=AWS --docker-password="$ECR_PASSWORD"
envsubst < deployment.yml | tee deploy.yml
kubectl apply -f deploy.ymlThis job is longer than the rest and has some new elements. Let’s break them down:
- Install aws-iam-authenticator (lines 2-5): download the program and add it to the PATH.
- Create ECR Secret in Kubernetes (lines 8-9): even though both ECR and the cluster are inside the Amazon cloud, we still need a token to connect each other. These lines send the registry’s username and password to Kubernetes.
- Deploy (lines 10-11): prepare the deployment file and sent it to the cluster.
To complete the block setup, repeat the last two steps you did when setting up the Dockerize pipeline:
- Under Environment Variable, define
AWS_DEFAULT_REGIONandECR_REGISTRY. - Open the Secrets section and activate the AWS secret:
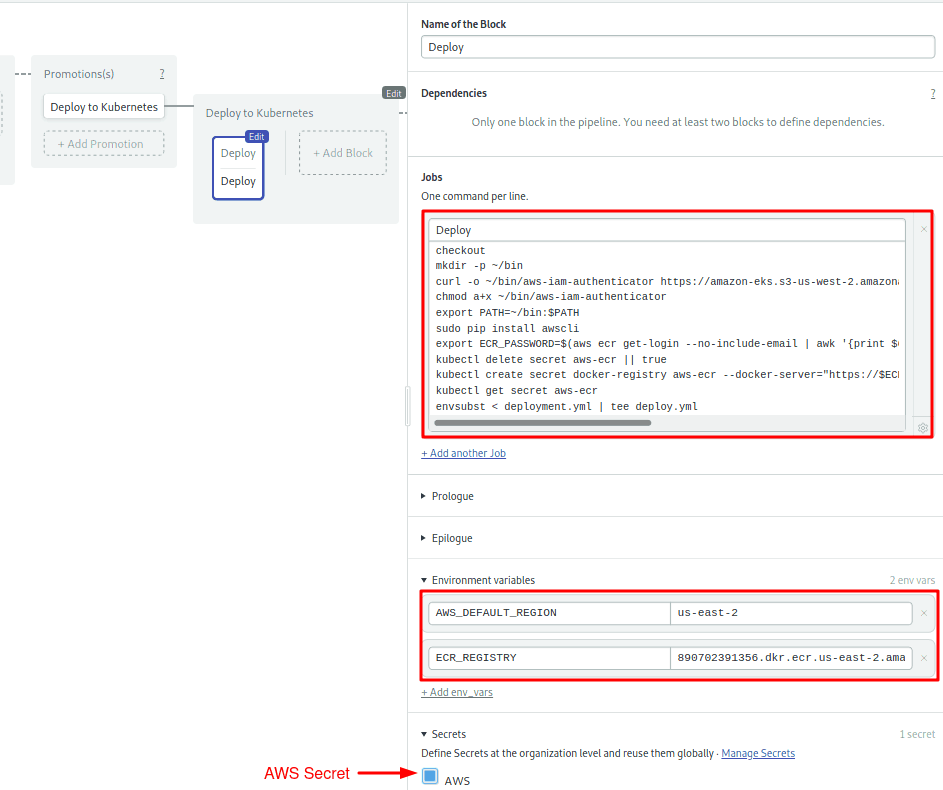
To complete the pipeline, we’ll need one more block.
The second block tags the current image as “latest” to indicate this is the image which is running on the cluster. The block retrieves it, slaps on the latest tag and pushes it again to the registry:
- Click on the + Add Block dotted box.
- Name the new block: “Tag latest release”.
- Name the job in the block: “Docker tag latest”.
- Define once more the Environment Variables and Secret as you did in the previous block.
- Type the following commands in the box:
sudo pip install awscli
aws ecr get-login --no-include-email | bash
docker pull "${ECR_REGISTRY}:$SEMAPHORE_WORKFLOW_ID"
docker tag "${ECR_REGISTRY}:$SEMAPHORE_WORKFLOW_ID" "${ECR_REGISTRY}:latest"
docker push "${ECR_REGISTRY}:latest"The final block should look like this:
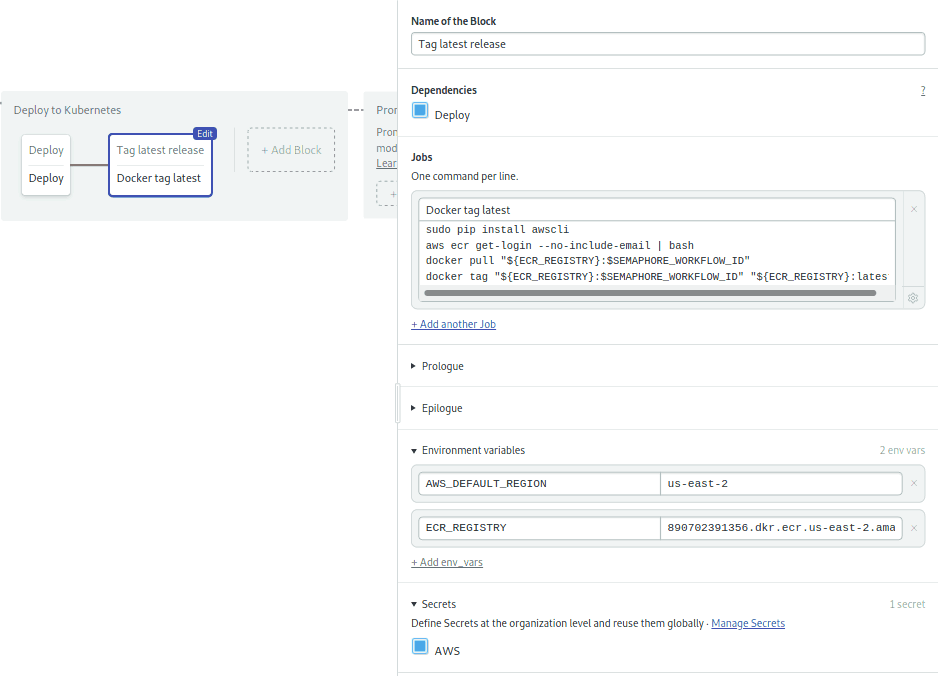
The pipeline is ready to go.
Save your changes:
- Click on Run the workflow
- Press Start
Deploy and test
Let’s teach our Sinatra app to sing. Add the following code inside the App class in app.rb:
get "/sing" do
"And now, the end is near
And so I face the final curtain..."
endPush the modified files to GitHub:
$ git add deployment.yml
$ git add app.rb
$ git commit -m "added deployment manifest"
$ git push origin masterThis will trigger a new build.
Hopefully, everything is green, and the docker image was created:
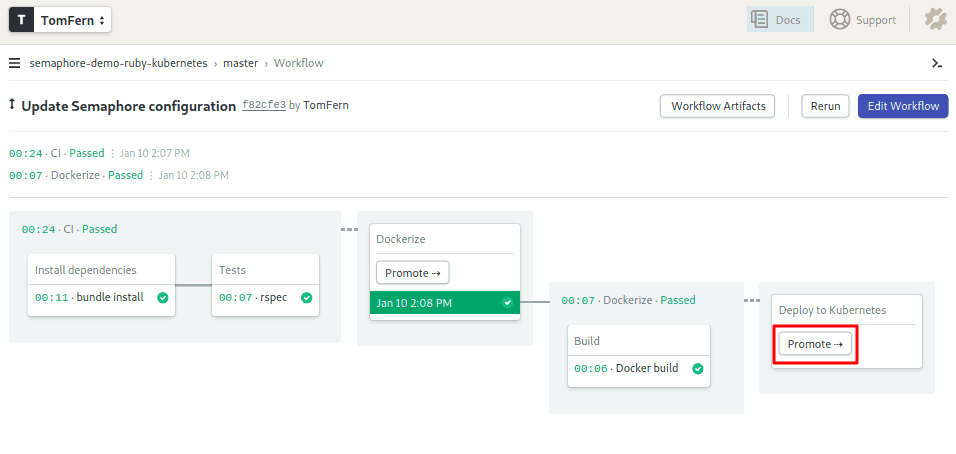
Time to deploy. Hit the Promote button. I’ll keep my fingers crossed. Did it work?
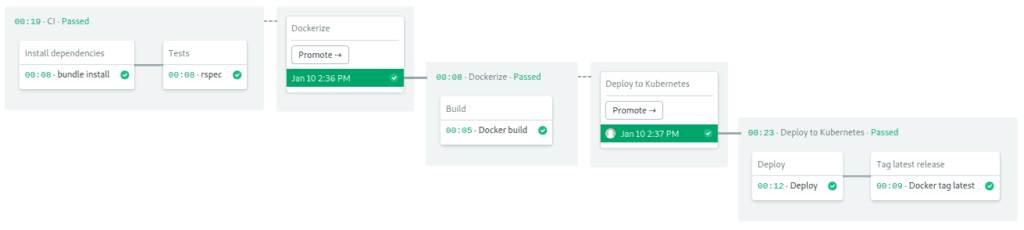
One more time, Ol’ Blue Eyes, sing for us:
$ curl -w "\n" YOUR_CLUSTER_EXTERNAL_URL/sing
And now, the end is near
And so I face the final curtain...The final curtain
Congratulations! You now have a fully automated continuous delivery pipeline to Kubernetes.
Feel free to fork the semaphore-demo-ruby-kubernetes repository and create a Semaphore project to deploy it on your Kubernetes instance. Here are some ideas for potential changes you can make:
- Create a staging cluster.
- Build a development container and run tests inside it.
- Extend the project with more microservices.
Want more Docker and Kubernetes? Don’t miss out this tutorials and docs:
- Learn about Docker and Kubernetes on Semaphore
- CI/CD for Microservices on DigitalOcean Kubernetes
- How to Release Faster with Continuous Delivery for Google Kubernetes
- A Step-by-Step Guide to Continuous Deployment on Kubernetes
This article originally appeared on DZone and is based on an episode of Semaphore Uncut, a YouTube video series on CI/CD.
