When I began experimenting with the OpenAI API, I didn’t pause to consider the range of available models. Instead, I used what was generally regarded as the most potent model at the time, GPT-3.5. But with the announcement of GPT-4’s general availability, I decided it was time to delve further.
Initially, I hadn’t planned to write this article, let alone publish it. It started with me exploring other models to understand their purpose and why they were created. Upon realizing that other developers had similar questions, I decided that this topic warranted a post. This is that post.
My aim is to provide an overview of all the currently available text models and offer guidelines to assist you in choosing the best fit for your AI application.
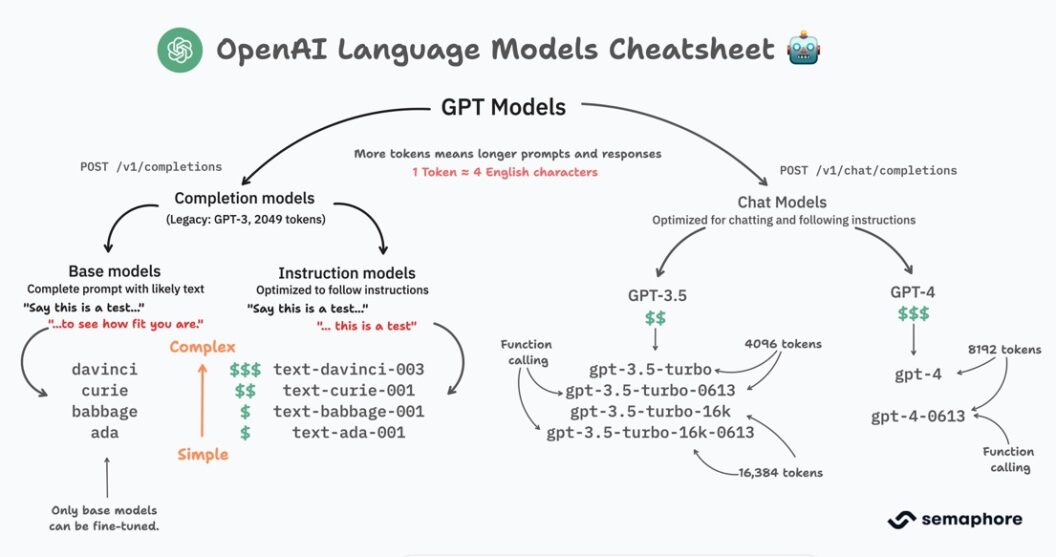
Before delving deeper, let’s review the available GPT generations.
The Three GPT Generations
OpenAI has introduced three generations of Large Language Models (LLMs). These models can execute all kinds of text-processing tasks, including question-answering, translation, creative content writing, summarizing, and role-following behavior.
- GPT-3 is the first generation of LLMs from OpenAI (GPT-2 was never publicly released). While effective at text generation, it can get confused and make mistakes.
- GPT-3.5 represents a minor update to GPT-3. It is more factual and less prone to harmful outputs than GPT-3. Also, it’s faster.
- GPT-4 is the latest generation of LLMs from OpenAI. It significantly surpasses GPT-3 or GPT-3.5 in power, producing more coherent, accurate, and creative text. It’s also multi-modal, meaning it can process audio and images.
Considerations When Selecting a Language Model
When selecting the appropriate Large Language Models (LLMs) for our application, there are several factors to consider.
Text Completion vs. Chat Models
A completion model attempts to extend the user’s prompt with relevant text. For instance, if our prompt is “The horse is,” the model will likely respond with something like “a domesticated animal.” Completion models do not have conversational capabilities. We send a single request, receive a response, and that’s the end of the interaction.
On the other hand, chat models are optimized for engaging in conversations. While they technically function as completion models, they can tell apart who said what, leading to a more natural conversation flow. We can pose questions, receive answers, and make follow-up requests. Anyone who has used ChatGPT would be familiar with this type of interaction.
In the table below, you can find both completion and chat models. As illustrated, both types of models use different API endpoints.
| Completion | Chat | |
|---|---|---|
| Endpoint | /v1/completion | /v1/chat/completion |
| Models | davinci curie babbage ada text-davinci-003 text-curie-001 text-babbage-001 text-ada-001 | All “gpt-4” models All “gpt-3.5-turbo” models |
OpenAI has labeled all completion models as legacy. While they remain available and updated this decision suggests that OpenAI’s focus will shift toward chat models in the future.
Instruction Following Capabilities
Base completion models, such as “davinci” or “curie,” perform poorly when it comes to following instructions, as the example below demonstrates (note: you can try all the examples in this article for yourself in the OpenAI playground).
Giving the model the instruction, “Say this is a test,” results in rather random text. While this might be entertaining, given our intended use, it’s not particularly helpful.

OpenAI offers several models fine-tuned to follow instructions. Any of these will do:
- All the “gpt-3.5-turbo” models
- All the “gpt-4” models
- All models beginning with “text-*”.
To illustrate the difference that fine-tuning makes, let’s apply the same prompt to “text-davinci-003”:

The full breakdown of model behavior follows below:
Base completion models | Instruction-following models |
|---|---|
| davinci | text-davinci-003 |
| curie | text-davinci-002 |
| babbage | text-davinci-001 |
| ada | text-curie-001 |
| text-babbage-001 | |
| text-ada-001 | |
| All gpt-3.5-turbo models | |
| All gpt-4 models |
Fine-Tunable Models
If you have been wondering about the relevance of models like “davinci”, “curie”, “babbage”, and “ada”, this is where they finally come into play. These base models are the only ones that can be fine-tuned.
But what is fine-tuning? Fine-tuning is the process of further training a model to carry out a specific task by feeding the model with example questions and responses. A fine-tuned model can achieve superior results, diminished costs, and enhanced latency for a given task.
The training data consists of example prompts, paired with their optimal completions, formatted as JSON Lines:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
For instance, if we wanted to train the model to be an expert in Barbie dolls, the first lines of the training data might look like these:
{ "prompt": "Can you tell me about the first Barbie doll ever released?", "completion": "The first Barbie doll was introduced by Mattel at the American International Toy Fair in New York on March 9, 1959. It was named Barbie after the creators' daughter, Barbara. The doll was a teenage fashion model, available in either a black and white striped swimsuit or a bandeau-style swimsuit with high-heeled shoes, sunglasses, and earrings." }
{ "prompt": "What is the most expensive Barbie ever sold?", "completion": "The most expensive Barbie doll ever sold at auction was the Stefani Canturi Barbie, which fetched $302,500 in 2010. This Barbie was designed by Australian jewelry designer Stefani Canturi. She was adorned with a necklace featuring a one-carat pink diamond." }
{ "prompt": "What are some popular Barbie playsets?", "completion": "There are many popular Barbie playsets that have been released over the years. Some of these include the Barbie Dreamhouse, the Barbie Dream Camper, the Barbie Care Clinic Vehicle, and the Barbie Malibu House. These playsets often come with a variety of accessories and can be used with any Barbie doll." }
...
Once the examples are ready, we upload them using the openai cli to begin the training. This process has a cost, so check out the pricing page before starting as you may need to process thousands of examples. It may also take several hours to complete. However, once trained, the model should excel as a world-class Barbie expert.
Token Capacity and Model Size
A significant factor to consider is the size of the model’s “context window,” measured in tokens. A token can represent a word, a part of a word, punctuation marks, or symbols (for English, a token represents, on average, four characters).
The larger the model’s token capacity, the more text it can process. However, the token capacity does not say anything about the model’s “intelligence.” For that, we need to consider the number of parameters.
Large language models are artificial neural networks, and the parameters are the connections and weights between the neurons in the network. The number of parameters relates to how much information the model can “remember” or “learn” from the training data it has been exposed to. In other words, the more parameters a model has, the more knowledgeable it is. A large model can reason, understand complex concepts, and make more nuanced decisions.
While OpenAI has not officially disclosed the size of its models, the Microsoft AI Reference page offers guidance. For the rest, we only have estimations.
Model | Capabilities | Token window | Parameters |
|---|---|---|---|
| ada | Capable of very simple tasks, usually the fastest model in the GPT-3 series, and lowest cost. | 2049 | 350 Millions |
| text-ada-001 | Same as “ada” but fine-tuned for instruction following. | 2049 | 350 Millions |
| babbage | Capable of straightforward tasks, very fast, and lower cost. | 2049 | 3 Billions |
| text-babbage-001 | Same as “babbage” but fine-tuned for instruction following. | 2049 | 3 Billions |
| curie | Very capable, but faster and lower cost than Davinci. | 2049 | 13 Billions |
| text-curie-001 | Same as “curie” but fine-tuned for instruction following. | 2049 | 13 Billions |
| davinci | Most capable GPT-3 model. It can do any task the other models can, often with higher quality. | 2049 | 175 Billions |
| text-davinci-003 | Better quality, longer output, and consistent instruction-following. Supports the inserting text feature. | 4097 | 175 Billions |
| text-davinci-002 | Similar to text-davinci-003 but trained with supervised fine-tuning instead of reinforcement learning | 4097 | 175 Billions |
| gpt-3.5-turbo | Most capable GPT-3.5 model and optimized for chat. | 4096 | 175 Billions |
| gpt-3.5-turbo-16k | Same capabilities as the standard gpt-3.5-turbo model but with 4 times the context. | 16,384 | 175 Billions |
| gpt-3.5-turbo-0613 | Same as “gpt-3.5-turbo” but with the function calling feature. | 4,096 | 175 Billions |
| gpt-3.5-turbo-16k-0613 | Same as “gpt-3.5-turbo-16k” but with the function calling feature. | 16,384 | 175 Billions |
| gpt-4 | More capable than any GPT-3.5 model, able to do more complex tasks, and optimized for chat. | 8,192 | Estimated at > 1 trillion |
| gpt-4-0613 | Same as “gpt-4” but with the function calling feature. | 8,192 | Estimated at > 1 trillion |
Pricing
Whether it’s completion, chatting, or fine-tuning, every interaction with the API incurs a cost. Generally, the larger the model, the higher the price. The exception is the “gpt-3.5-turbo” series, which is the same size as “davinci” but costs a tenth of the price, making it one of the most cost-effective models for powering AI applications.
Before building your application, carefully examine the OpenAI pricing page to estimate your system’s API costs.
Other Considerations
While I have covered the more general factors to consider when choosing a model, there are a few other minor aspects that might be significant in certain scenarios:
- Function calling: The “gpt-3.5” and “gpt-4” models ending in “0613” have been trained to detect the need for function calling based on the user’s prompt, and they respond with a structured call request instead of regular text. This feature allows us to integrate a GPT model with the external world.
- Static vs. updated models: All the models ending in a version number, such as “gpt-3.5-turbo-0613”, “gpt-3.5-turbo-16-0613”, or “gpt-4-0613”, are static — they do not receive updates. Using a static model is like pinning dependencies, you know they won’t change so it’s safer to build a product on top but sooner or later OpenAI will deprecate the model and you’ll have to switch up. As new versions of the models are released, the older ones are deprecated. The unversioned models, such as “gpt-3.5-turbo” and “gpt-4”, are periodically being updated by OpenAI.
- Multi-modal capabilities: Only “gpt-4” supports multi-modal capabilities, meaning it can process images and text. Unfortunately, this feature is not available to the general public yet, but you can see a few examples of how it works.
A Few Thoughts on Choosing a Model
The “gpt-3.5-turbo” series is the most cost-effective of all the available models. Since it’s also the second-largest model, it’s a logical choice for basing a minimum viable product (MVP) on. Yet, the parameter size of a model only tells part of the story. The rest comes from experimentation.
Avoid using ChatGPT, as this application injects its own prompts. Instead, use the OpenAI playground or access the API directly for better control. Experiment with the prompts your application will need to determine which model works best.
Training your model might be worthwhile if you have lots of training data. It’s an investment that could pay off in the long term, as a trained model requires fewer prompts to do the same work (and fewer prompts equals fewer tokens, leading to lower costs). Before proceeding, however, estimate the cost of the fine-tuning process itself; everything is outlined on the pricing page.
Conclusion
As we’ve explored, OpenAI offers a range of options, each with unique capabilities, costs, and implications. The “gpt-3.5-turbo” series, being the most cost-effective, is a popular choice, but understanding your specific application needs, fine-tuning possibilities, and budget constraints will guide you toward the most appropriate option.
Other articles that might interest you:
- Word Embeddings: Giving Your ChatBot Context For Better Answers
- Exploring Function Calling in OpenAI’s GPT Models
- 10 Best Alternatives To ChatGPT: Developer Edition
- Build a ChatGPT-Powered Chatbot With Flutter
- ChatGPT Writes Code: Will It Replace Software Developers?
References:

{kind=link}