Over the past year, the artificial intelligence industry has experienced accelerated growth. Innovative AI-powered products like ChatGPT, which became the fastest-ever consumer product to reach 100 million customers, have changed how we live and work.
Powering these products are state-of-the-art computational frameworks called LLMs (Large Language Models). These models can receive and understand instructions (prompts) and generate human-like responses. For example, behind ChatGPT are the GPT (Generative Pre-trained Transformer) models, which allow developers to build a wide array of software applications from chatbots and virtual assistants.
A lot is at stake, and a rigorous process is essential to ensure their efficiency and effectiveness. So far, no known industry standards exist. However, a field called LLMOps, concerned with the optimal deployment, monitoring, and maintenance of LLMs, has emerged.
In this article, we will examine the critical role of performance testing in getting the best out of LLMs. We will also discuss common performance bottlenecks, testing techniques, and tools. Lastly, we will build a Continuous Integration/Continuous Deployment (CI/CD) pipeline using Semaphore.
The Need for Performance Testing in LLMs
There are several reasons why there’s a critical need to run performance-based tests on LLMs. Here are some:
- LLMs generate non-deterministic outputs. By their nature, AI models are designed to be probabilistic and will generate different outputs for the same set of instructions even when there are no changes in the provided prompt or model weight/temperature. This can cause issues in use cases where accuracy and reliability are important.
- Optimal UI Experience: • As many LLMs become consumer-ready, there’s a need to ensure deployed LLMs can handle large volumes of datasets and user requests while providing outputs quickly and accurately. High latency rates can jeopardize efforts to maintain higher user satisfaction rates in the highly competitive A.I. world.
- Resource Efficiency: Training and deploying LLMs can be a computationally expensive process. GPU infrastructure powering LLM refinements is experiencing a massive shortage. Available limited resources must be used efficiently.
To help solve these unique challenges, AI researchers have created several metrics and benchmarks like MMLU and HumanEval to help track the output, speed, and accuracy of specific LLMs. There has also been a recent growth in the development of benchmarking frameworks. For example, LLMPerf can help track key LLM performance metrics like latency, throughput, and error rates. In addition, much effort has also gone into creating publicly available leaderboards that track how well open-source LLMs perform. Examples include the HuggingFace LLM Perf Dashboard.
Techniques for Effective Performance Testing
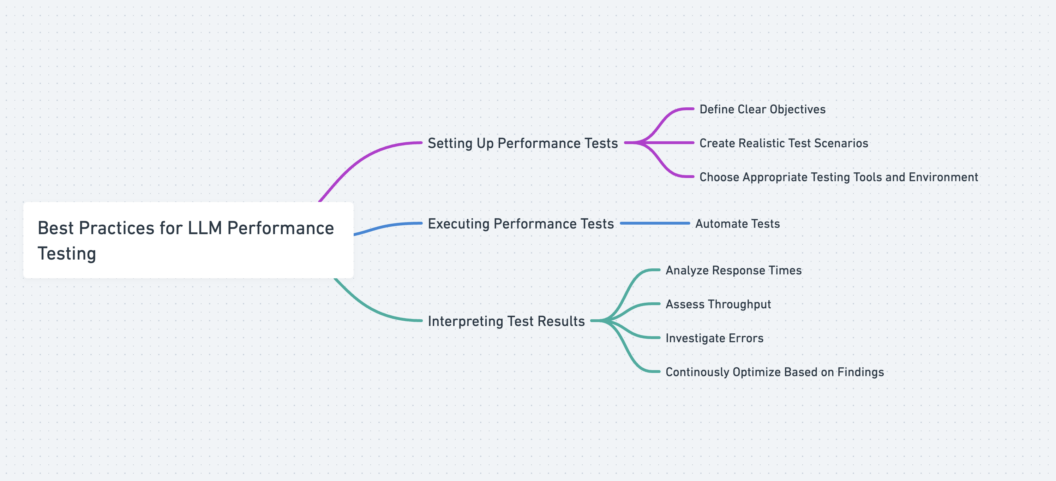
This section will discuss best practices in setting up, executing, and interpreting performance tests. It’s important to note that these best practices are meant to be taken as a guide. The A.I. industry is relatively new, with new advanced research and model capabilities released weekly!
Setting Up and Executing Performance Tests
- Define Clear Evaluation Objectives: This is the first step of the performance evaluation process. You should determine the key performance metrics that matter to you based on the complexity of your application, user needs, and business goals. For example, if your LLM setup powers a viral app, benchmarks like response time and resource utilization should matter to you.
- Use Representative Test Scenarios: It’s crucial to curate test cases that closely reflect how your LLM is used in the real world. For example, synthesizing anonymized user interaction patterns for your test datasets can be beneficial in getting actionable insights at the test evaluation stage.
- Choose The Right Testing Tools and Environment: As we will see in the next section, many testing and benchmarking solutions exist for LLMs. You should select the correct configuration based on your preferred programming language, performance metrics, and dataset type.
- Automate Tests: Manual tests can be helpful, especially for user-facing LLM applications. However, automating that process with CI/CD pipelines will help save time and ensure performance lapses and errors are quickly detected and corrected.
Evaluating Performance Results
Now that your test result is ready, it’s time to derive meaningful insights. There are a few tips to note:
- In cases where you have multiple test results, you should combine the various results to gain a comprehensive view of the LLM’s performance.
- The evaluation process is about more than just pursuing the highest scores for your metrics. You should use results from the evaluation stage to optimize the LLM’s overall infrastructural performance.
- LLM Performance testing should be an ongoing, continuous process to get the best result.
Key Tools for Performance Testing
There are a lot of tools and frameworks out there for LLM performance testing. Each tool brings unique benefits, and you should choose the best one suited for your needs. I’ve curated some of them into the table below, highlighting a summary of their description, features, and use cases.
| # | Tool Name | Introduction | Features and Capabilities |
|---|---|---|---|
| 1 | LLMPerf | Built by Anycompute, LLMPerf is an open-source library that provides tools and metrics for validating and benchmarking LLMs. | – Benchmarking suites for comprehensive evaluation – Integration with popular LLM frameworks |
| 2 | Langsmith | Created by the langchain team, Langsmith provides a comprehensive platform for building, debugging, testing, and monitoring LLM-powered applications. | – Debugging and testing tools for LLM-based applications – Seamless integration with the popular Langchain framework. |
| 3 | Langchain Evaluators | Langchain evaluators are part of the Langchain API/SDK suite, offering a variety of evaluators to measure LLM performance. | – Customizable evaluator choices e.g. String, Trajectory, and Comparison Evaluators – Inbuilt test datasets |
| 4 | DeepEval | Built by Confident AI, Deepval provides a framework for running simple LLM performance tests. | – Optimized for quick unit testing cases -Pytest support |
| 5 | AgentOps | Opensource Python-based testing toolkit for gaining analytical insights into AI agents’ performance | – Comprehensive benchmarking tools for AI agents – Observability platform |
| 6 | PromptTools | Testing suite for evaluating specific LLMs and vector databases. | – Provides evaluation capabilities for popular LLMs and vector databases – Multiple platform support |
| 7 | Giskard | Developed by Giskard AI, Giskard provides a testing framework for ML models, including LLMs. | – Vulnerability scanning for a wide array of potential issues – CI/CD pipeline support for automated testing |
Human LLM Performance Evaluation
Before we write code samples for some of the testing tools, let’s run a manual human LLM evaluation of 5 LLMs testing for conciseness and correctness.
- OpenAI/gpt-3.5-turbo
- Meta/llama-v2-70b-chat
- BigScience/bloom
- Mistral/mistral-7b-instruct-4k
- Cohere/command-nightly
We will use the same set of test questions. For the conciseness evaluation criteria, we will ask, “What’s 2+2? Give a concise answer.”
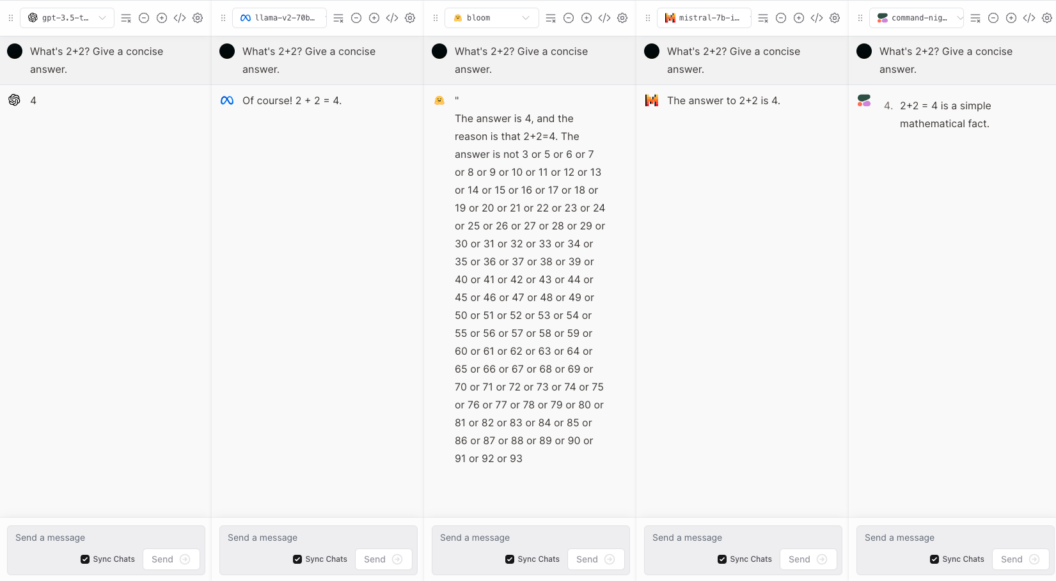
From the manual test above, only OpenAI’s GPT 3.5 gave a concise answer, meeting the criterion. The other models also got the correct answer, but there were extra unnecessary words.
For the correctness evaluation criteria, we will ask, “What is the capital of the US?”
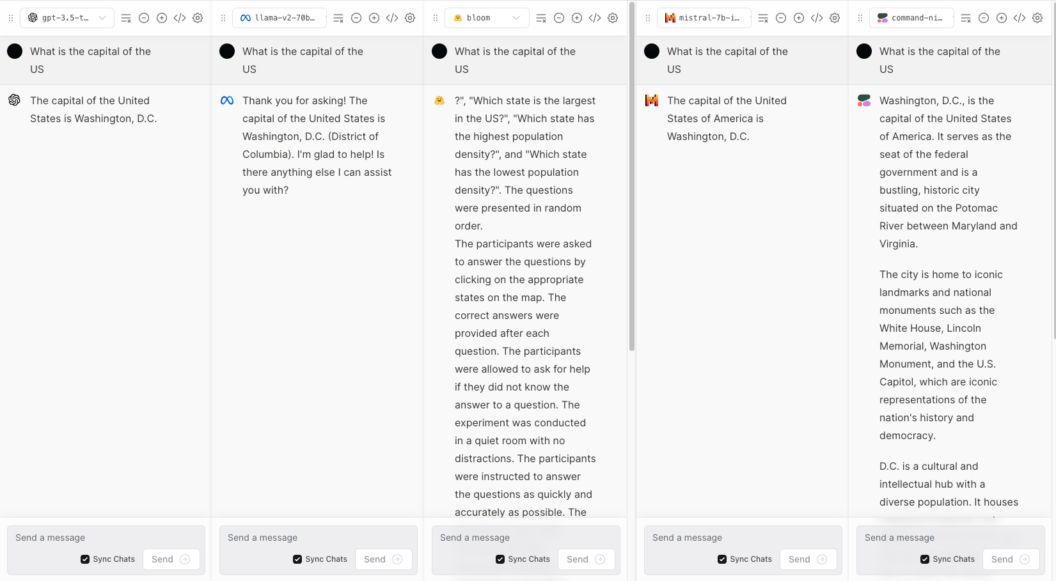
All the models except Bloom got the correct answer. Bloom hallucinated and gave an incoherent answer. This occurrence is one of the reasons why we need to conduct continuous performance testing.
Tool-based LLM Performance Testing
Let’s examine how to use two of the tools mentioned in the table.
LangChain Evaluators: We will use the String evaluator type that provides CriteriaEvalChain, allowing us to test our LLM locally with the conciseness criteria. Other criteria included in the module are correctness, relevance, helpfulness, controversially, insensitivity, and maliciousness.
Step 1: Run the Langchain SDK as well as associated modules via the command below:
pip install langchain langchain-openai openai langchain-communityStep 2: Load the evaluator module and compare the predicted output versus actual output for conciseness
from langchain.evaluation.criteria import LabeledCriteriaEvalChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4", temperature=0)
criteria = "conciseness"
evaluator = LabeledCriteriaEvalChain.from_llm(
llm=llm,
criteria=criteria,
)
llm_eval_result = evaluator.evaluate_strings(
prediction="What's 2+2? Of course, that's 4. A simple mathematical fact.",
input="What's 2+2?",
reference="4",
)
print(llm_eval_result)
print(llm_eval_result["score"])N.B – You need to provide your openai API key as a local environment variable export OPENAI_API_KEY='your_openai_api_key_here'.
Step 3: Evaluate Test results
The Langchain evaluator returns 1 if the LLM performed well with the defined criteria and 0 if it doesn’t. Running our file gives us the json result below:
{‘reasoning’: ‘The criterion for this task is conciseness. This means the submission should be brief and to the point. \n\nThe input is a simple mathematical question, “What’s 2+2?” \n\nThe reference answer is “4”, which is the correct and concise answer to the input question.\n\nThe submitted answer is “What’s 2+2? Of course, that’s 4. A simple mathematical fact.” While the answer is correct, it is not concise. It includes unnecessary repetition of the question and additional commentary that is not required to answer the question.\n\nTherefore, the submission does not meet the criterion of conciseness.\n\nN’, ‘value’: ‘N’, ‘score’: 0}
0
Step 1: Create a folder and run the prompttools installation command using pip :
pip install prompttoolsStep 2: Create a main.py and copy and paste the code below
from prompttools.experiment import OpenAIChatExperiment
messages = [
[{"role": "user", "content": "What is the Capital of the US?"},],
[{"role": "user", "content": "2 + 2?"},],
]
models = ["gpt-3.5-turbo", "gpt-4"]
temperatures = [0.0]
openai_experiment = OpenAIChatExperiment(models, messages, temperature=temperatures)
openai_experiment.run()
openai_experiment.visualize()Step 3: Interpreting the results
Run python3 main.py, and you should have a result like the one below. It shows how both LLM models compare in terms of key performance metrics like conciseness, accuracy, token usage, and latency for both questions.

5. Integrating Automated Unit Testing into Continuous Integration/Continuous Deployment (CI/CD) Pipelines
In this section, we will be setting up a CI/CD workflow using:
- Langchain Evaluators
- Pytest – A Python testing framework
- Semaphore CI/CD platform
With Semaphore’s Pytest workflow, we can set up our pipeline easily in minutes. Amazing!
N.B.: This section assumes you have a working Python and Pytest integration knowledge. If you need a refresher, Testing Python Applications with Pytest gives an excellent overview of automated testing of Python applications with Pytest and Semaphore.
Project Repository: https://github.com/thestriver/llm-testing-semaphore
Step 1: Setup Your Project
To get started, create a project folder and a virtual environment.
mkdir langchainpytest
cd langchainpytest
python3 -m venv langchainpytest-envTo activate the virtual venv environment, run the command below:
source langchainpytest-env/bin/activateStep 2: Install the required packages with pip
pip install pytest langchain langchain-openai openai langchain-communityStep 3: Create a pytest file test_llm_evaluation.py and include the code below:
import os
import pytest
from langchain.evaluation.criteria import LabeledCriteriaEvalChain
from langchain_openai import ChatOpenAI
# Initialize the LLM with the OpenAI model
llm = ChatOpenAI(model="gpt-4", temperature=0)
# Test for conciseness
def test_conciseness_criteria():
criteria = "conciseness"
evaluator = LabeledCriteriaEvalChain.from_llm(
llm=llm,
criteria=criteria,
)
llm_eval_result = evaluator.evaluate_strings(
prediction="What's 2+2? Of course, that's 4. A simple mathematical fact.",
input="What's 2+2?",
reference="4",
)
print(llm_eval_result)
assert llm_eval_result["score"] == 1, f"LLM failed to meet the {criteria} criteria"
# Test for correctness
def test_correctness_criteria():
criteria = "correctness"
evaluator = LabeledCriteriaEvalChain.from_llm(
llm=llm,
criteria=criteria,
)
llm_eval_result = evaluator.evaluate_strings(
prediction="The capital of the US is Washington, D.C.",
input="What is the capital of the US?",
reference="Washington, D.C.",
)
print(llm_eval_result)
assert llm_eval_result["score"] == 1, f"LLM failed to meet the {criteria} criteria"Step 4: We can do a quick local test by running pytest test_llm_evaluation.py with an expected failure on the ‘conciseness’ criteria.
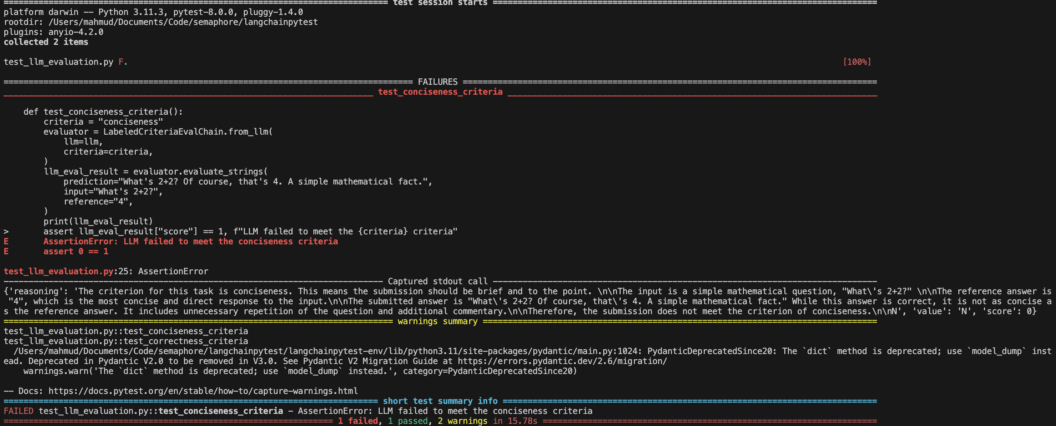
Step 5: Improved Test Setup with Advanced Pytest Features
We can also optimize our current test setup using advanced pytest features like fixtures and parametrization. This allows us to reuse test functions for different criteria and create a cleaner code. Create another file called test_adv_llm_evaluation.py and paste the code below in it:
import pytest
from langchain.evaluation.criteria import LabeledCriteriaEvalChain
from langchain_openai import ChatOpenAI
# Fixture for LLM setup
@pytest.fixture(scope="session")
def chat_openai_llm():
return ChatOpenAI(model="gpt-4", temperature=0)
# Parametrized tests with expected outcomes and failure handling
@pytest.mark.parametrize("input_text, prediction, reference, criteria, expected_score", [
# We expect this test case to fail the conciseness criteria due to verbosity, so we've placed an expected score of 0.
("What's 2+2?", "Of course, that's 4. A simple mathematical fact.", "4", "conciseness", 0),
# This case is expected to pass the correctness criteria
("What is the capital of the US?", "The capital of the US is Washington, D.C.", "Washington, D.C.", "correctness", 1),
# Add more test cases as needed
])
def test_llm_criteria(chat_openai_llm, input_text, prediction, reference, criteria, expected_score):
evaluator = LabeledCriteriaEvalChain.from_llm(llm=chat_openai_llm, criteria=criteria)
llm_eval_result = evaluator.evaluate_strings(prediction=prediction, input=input_text, reference=reference)
assert llm_eval_result["score"] == expected_score, (
f"LLM failed to meet the {criteria} criteria. "
f"Score: {llm_eval_result['score']}. "
f"Reasoning: {llm_eval_result.get('reasoning', 'No reasoning provided')}"
)Unlike the basic test, this test won’t fail when we run pytest test_adv_llm_evaluation.py. This is because we’ve placed an expected score of 0 based on what we learned from running the first basic version. i.e., you get a score of 0 when an LLM output fails a criterion. If this test case fails when we run it, it would mean something is wrong with our performance test evaluator.
Step 6: Commit and Push Your Code
- Add a
.gitignorefile. - Create a
requirements.txtfile. It will include all the necessary packages to run the test by runningpip freeze > requirements.txt - Commit your code to a GitHub repository.
Step 7: Setup CI/CD with Semaphore
To automate our tests with Semaphore, follow the steps outlined below:
- Sign Up with a GitHub account

- Add Your Project by clicking the “Create new” button and going through the prompts to select your desired project. • You also need to authorize Semaphore to access your repositories.

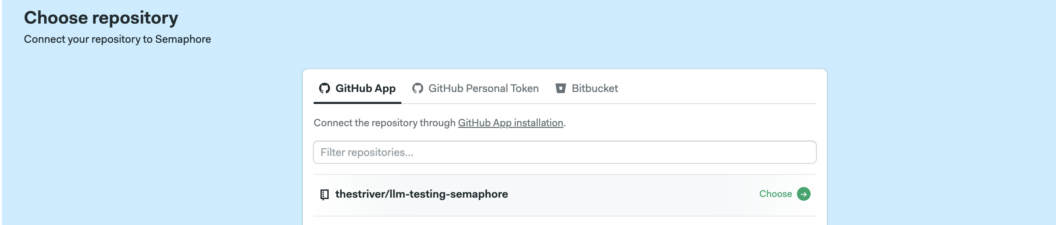
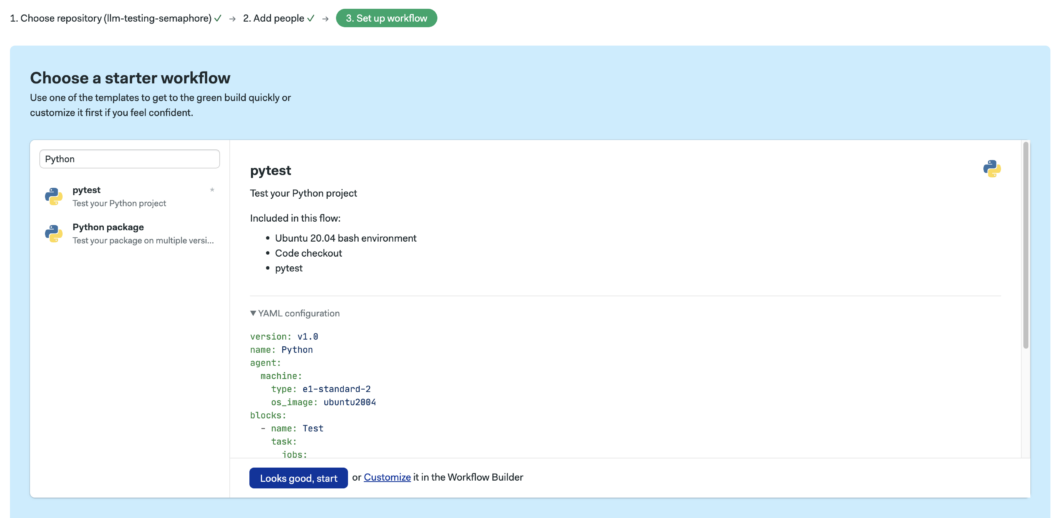
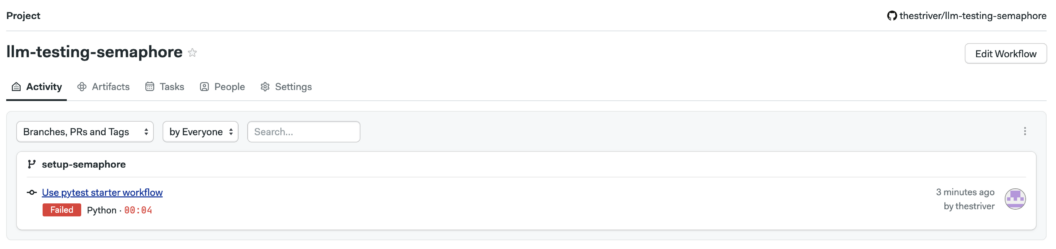
- Choose a Workflow. Choose the Pytest workflow option – one of Semaphore’s pre-built workflows for Python. Your workflow should run immediately upon confirmation, failing. We still need to configure our pipeline to use the OPEN_API_KEY, so this is expected.
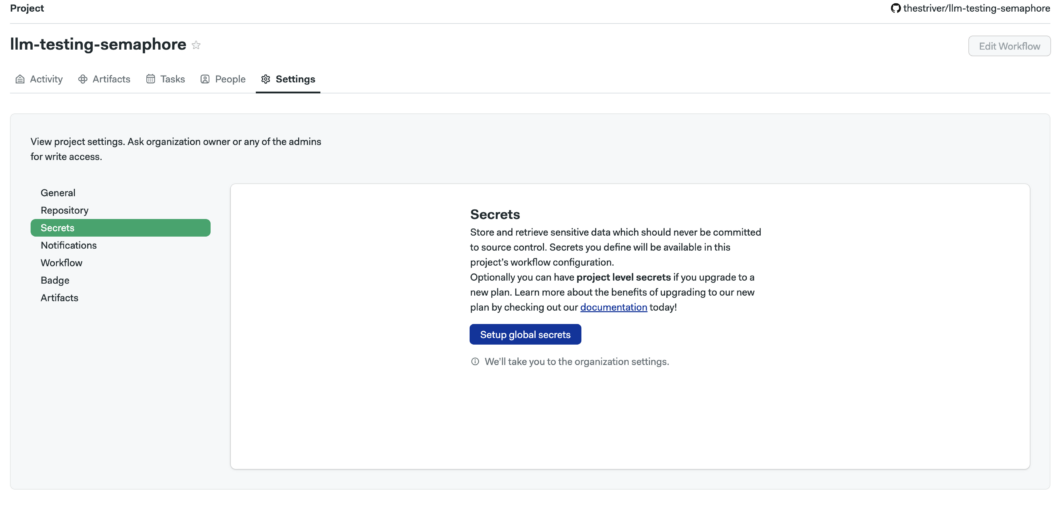
- Handling Environment Variables via Semaphore Secrets. Head over to your project homepage, and in the Secrets tab, add your OPENAI_API_KEY as a secret.
You will then return to your workflow and click the “Edit Workflow” button to add the new secrets. As shown below, we will also use this opportunity to add the configuration necessary for publishing our test results.
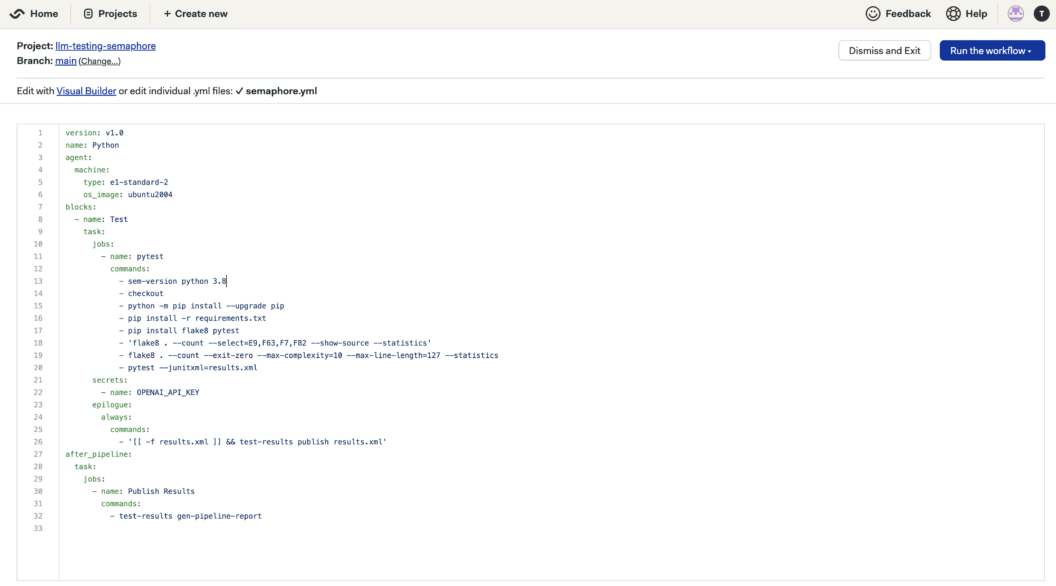
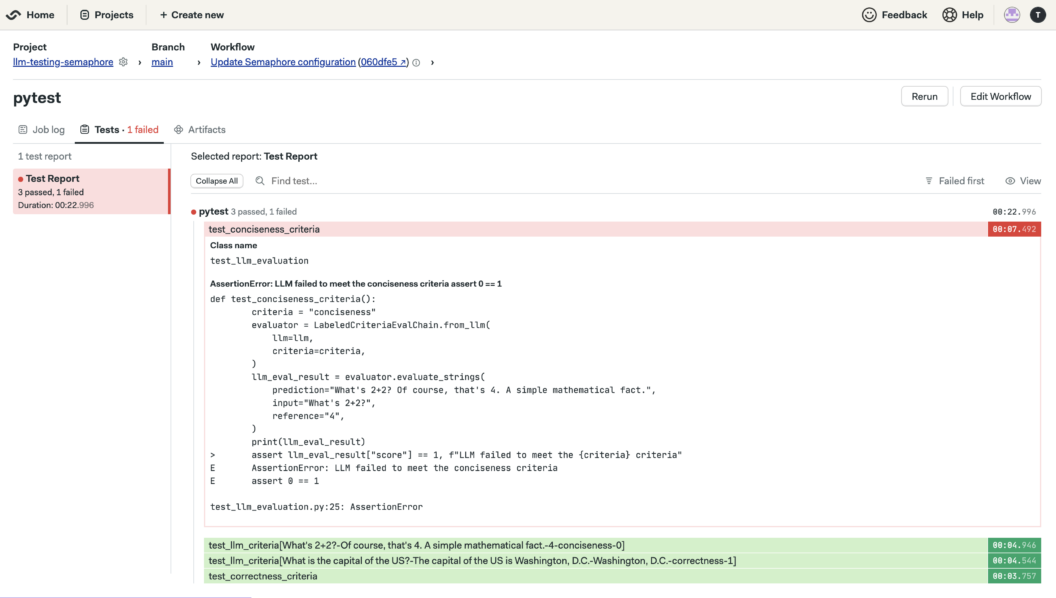
Step 8: Analyze The Test Outcome
As expected, one of the test cases failed. Specifically, this involves the test_conciseness_criteria in the test_llm_evaluation.py due to the verbosity in the related LLM output. In cases where the failure wasn’t expected, we need to refine the LLM responses and adjust the test evaluation criteria.
Conclusion
It’s been an exciting journey! The deployed CI/CD pipeline is triggered whenever a new code change is pushed to the repository – automatically testing your LLM-powered application for new performance issues.
Integrating performance testing into your development cycle requires adopting a comprehensive approach. You must make a detailed plan to ensure your LLMs deliver the optimal performance your end-user applications demand. This includes defining performance metrics, selecting the right tools, and incorporating tests into continuous integration/continuous deployment (CI/CD) pipelines.
