Large language models (LLMs) are positively changing how we build applications because of their ability to process natural languages efficiently as both text and media data. The capabilities of LLMs include text generation, media generation, complex text summary, data processing and code generation, etc. Applications today are integrating LLMs for increased efficiency and productivity. For example, some applications use LLMs to automate repetitive tasks like content creation. Apps that rely heavily on LLMs are called LLM-based applications. While the benefits of LLMs are enormous, it is important to understand the potential risks and drawbacks associated with their use to continuously monitor, safeguard, and optimize their performance.
Because LLMs are constantly evolving, LLM-based apps must continuously validate their models to prevent deviation and anomalies. Large language models may sometimes deviate significantly from prompt instructions and generate factually inaccurate and context-inconsistent outputs – this is known as model hallucination and can negatively impact the performance of your application in production if not prevented.
An LLM evaluation solution can help you identify pitfalls in your model by continuously validating it throughout the lifecycle of your application – from testing to production. Continuous validation and evaluation of LLMs help to optimize their performance, catch deviations on time, prevent hallucination, and protect users from toxic output and privacy leaks.
This article delves into the details of optimizing the performance of LLMs using an LLM evaluation solution. We will explore the benefits of continuous LLM evaluation for LLM-based applications, discuss the available tools for LLM evaluation & their features, and do a demo evaluating real-world data to detect deviation, weakness, toxicity, and bias in model outputs and remediate them using one of the LLM evaluation solutions.
Benefits of Continuous LLM Evaluation
Continuous evaluation of LLMs has enormous benefits for both developers and end users. LLM evaluation helps developers and product owners understand how their model responds to user inputs, identify weak segments, and optimize performance. It can also help prevent toxicity, improve the accuracy of outputs, and prevent personally identifiable information (PII) leaks.
The following are some of the benefits of LLM evaluation in detail:
- Identify the model’s strengths and weaknesses: Evaluation helps you understand the strengths of your model – the topics they generate the most accurate output for, the inputs with the most coherent outputs, etc. It also identifies the weak areas in your model’s output that need optimizing. LLM evaluation can help improve the overall performance of your LLM.
- Reduce bias and ensure safety: Continuous evaluation ensures model safety and fairness for users of all demographic groups by identifying and mitigating biases in LLMs’ training data and output. LLM evaluation can help you detect stereotypes and discriminatory behaviors in LLM outputs and ensure safety, fairness, and inclusivity for your users.
- Improve accuracy: You can improve the accuracy of output generated by your LLM if you can measure how well it understands user inputs. LLM evaluation validates your model and provides a calculated metric for accuracy.
- Toxicity detection: Evaluating your LLMs can help detect toxicity. LLM evaluation engines have toxicity detection models that measure the model’s ability to distinguish between harmful and benign languages.
- Prevent hallucination: LLMs may generate contextually inconsistent and factually inaccurate texts for reasons like language ambiguity, insufficient training data, and biases in training data. Evaluation can help identify and mitigate hallucinations.
- Prevent privacy leaks: LLMs may leak personally identifiable information (PII) from engineered prompts. PII is sensitive data, such as social security numbers, phone numbers, and a social media handle, that can be used to identify a person. Continuous LLM evaluation can help identify leakage vulnerabilities and mitigate risks.
- Early detection of deviations: Evaluation can detect deviations and anomalies in model output.
- Benchmarking: Evaluated LLMs can be compared with others, allowing for an objective assessment of their relative strengths and weaknesses.
Tools for LLM Evaluation and Their Features
While building your own LLM Evaluation solution in-house might seem appealing, it is however difficult to build a solution that is robust, comprehensive, and efficient to do a thorough analysis and validation of LLMs. Leveraging existing LLMOps tools for LLM evaluation offers significant advantages. The evaluation tools in this section are all open-source and can be self-hosted on your environment.
Let’s look at some tools for LLM evaluation and their features.
FiddlerAI
FiddlerAI specializes in AI observability, providing ML engineers the platform to monitor, explain, analyze, and evaluate machine learning models and generative AI models. As an open-source model performance management (MPM) platform, FiddlerAI monitors model performance using specific key performance indicators, detects bias, and provides actionable insights to improve performance & model safety.
LLM-based applications can leverage FiddlerAI to optimize the performance of their model, build trust in their AI pipeline, and identify weaknesses in their model before reaching production and in real time.
Key features of FiddlerAI:
- LLM Performance Monitoring: FiddlerAI tracks the performance of deployed LLMs in real-time, providing real-time insights and assessment of the model’s performance – identify and fix degradation.
- Model Explainability: FiddlerAI provides explainability for large language models, helping you understand how your models arrive at their outputs and identify biases.
- Model Analytics: Understand the impact of ineffective models on your business through insightful analytics provided by FiddlerAI. Track down the point of failure within your model, compare model performance metrics, and take corrective actions using data from model analytics.
- MLOps Integration: FiddlerAI is seamlessly integrable with other MLOps tools. It supports integration with LangChain and allows custom evaluation metrics.
- Responsible AI: FiddlerAI provides resources to help develop and deploy responsible and ethical models.
Deepchecks LLM Evaluation
Deepchecks LLM Evaluation is an open-source tool for validating AI & ML models throughout their lifecycles. Deepchecks LLM Evaluation engine continuously monitors and evaluates your LLM pipeline to ensure your models perform optimally. It measures the quality of each model interaction using properties like coherence, toxicity, fluency, correctness, etc. It also supports custom properties and allows you to customize the configuration file of the LLM evaluation engine.
Deepchecks evaluate both accuracy and model safety from experimentation to production. The engine continuously evaluates your LLM and provides real-time monitoring using measurable metrics to ensure that your models perform well at all times.
Key features of Deepchecks LLM Evaluation:
- Flexible Testing: Deepchecks LLM Evaluation allows you to test your LLM by providing a Golden Set data as the base for evaluating your LLM pipeline.
- Performance Monitoring: It also monitors your model’s performance in production and alerts you for deviations, drifts, or anomalies.
- Annotation Insights: Deepchecks LLM Evaluation engine analyzes LLM interactions and annotates them as good, bad, or unknown based on the quality of the interaction.
- Properties Scoring: Deepchecks evaluate properties such as coherence, fluency, relevance, grounded in context, avoided answer, etc., and provide a calculated score for each.
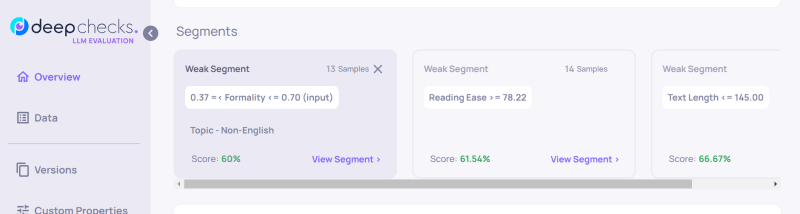
- Segment Analysis: Deepchecks helps identify weak segments in your LLM pipeline, allowing you to know where your model underperforms.
- Version Comparison: Version comparison is useful for root cause analysis and regression testing.
EvidentlyAI
EvidentlyAI is an open-source Python library for evaluating, testing, and monitoring machine learning models throughout their lifecycle – experimentation to production. It helps to ensure that your model is reliable, effective, and free from bias. EvidentlyAI works with text data, vector embeddings, and tabular data.
Key features of EvidentlyAI:
- Test Suites: Create automated test suites to assess data drifts and regression performance. EvidentlyAI performs model and data checks, and returns an explicit pass or fail.
- Performance Visualization: EvidentlyAI renders rich visualizations of ML metrics, making it easy to understand your model’s performance. Alternatively, you can retrieve performance reports as HTML, JSON, Python dictionary, or EvidentlyAI JSON snapshot.
- Model Monitoring Dashboard: EvidentlyAI provides a centralized dashboard that you can self-host for monitoring model performance and detecting changes in real time.
Giskard
Like EvidentlyAI, Giskard is a Python library for detecting performance degradation, privacy leaks, hallucination, security issues, and other vulnerabilities in AI models. It is easy to use, requiring only a few lines of code to set up. However, Giskard is limited in features compared to Fiddler AI and Deepchecks LLM Evaluation. It is not a robust solution.
Key features of Giskard:
- Advanced Test Suite Generation: Giskard can automatically generate test suites based on the vulnerability detected in your model. You can also debug your models and diagnose failed tests.
- Model Comparison: Compare the performance of your models and make data-driven decisions.
- Test Hub: Giskard fosters effective team collaboration by providing a place to gather tests and collaborate.
- LLM Monitoring: Giskards prevents hallucination, toxicity, and harmful responses by continuously monitoring your models. It also provides insights to optimize model performance.
Demo: Evaluating Real World Data With an LLM Evaluation Tool
Next, we will evaluate sample data using Deepchecks LLM Evaluation – one of the LLM evaluation tools discussed earlier.
Set up
- Create an account on Deepchecks. Deepchecks LLM Evaluation is invite-only at the time of writing this article. On the homepage, click Try LLM Evaluation and fill in your details. Deepchecks will send you a system invite after reviewing your details. Alternatively, you can request an organizational invite from any deepchecks user organization you’re familiar with.
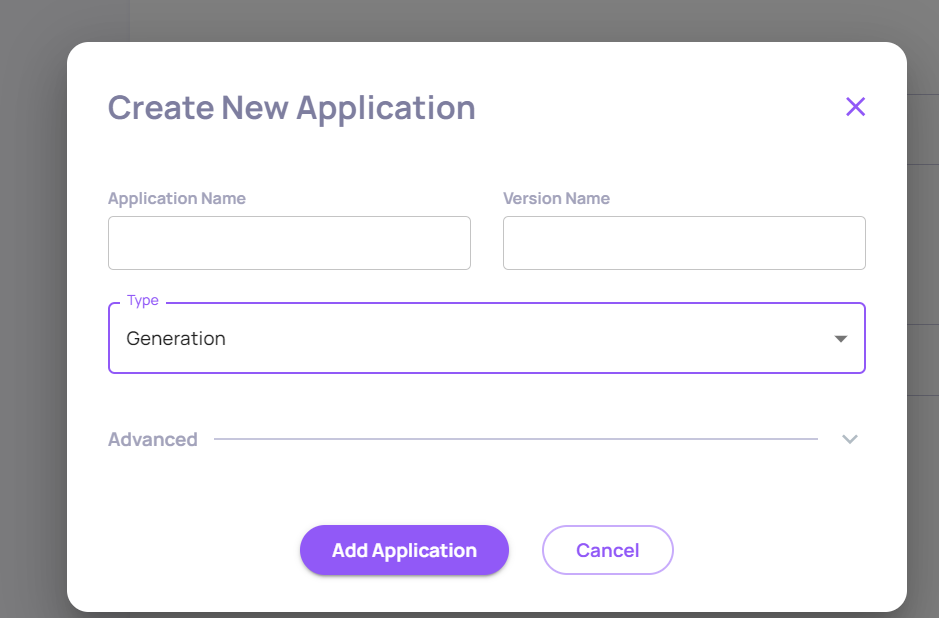
- Set up your project information – name, version, and type.
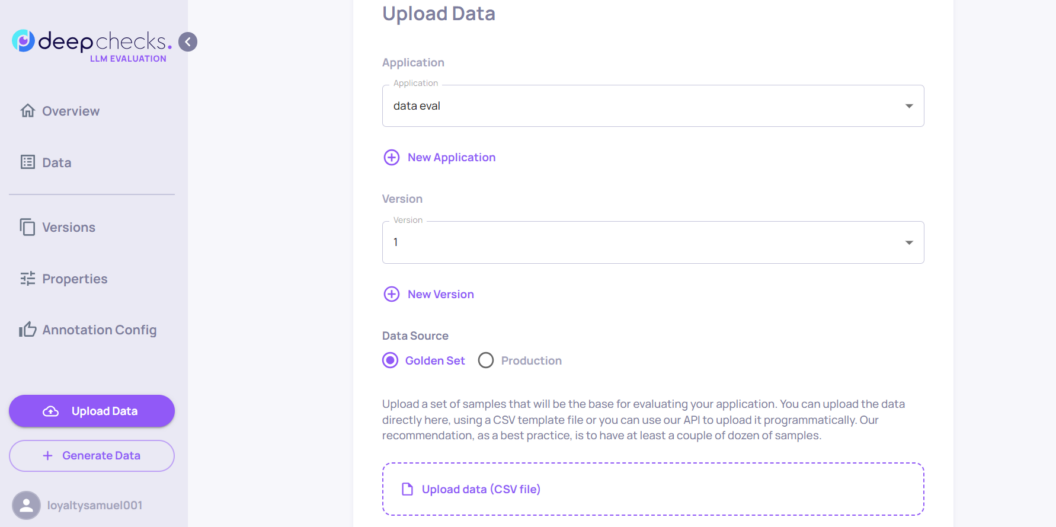
We set the Data Source to Golden Set because we want to evaluate a pre-production sample. For LLM evaluation in production, upload production samples. Alternatively, you can upload your data programmatically using Deepchecks API.
Data Upload
For this demo, the sample data we want Deepchecks to evaluate is our interaction data with the GPT-3.5 LLM. To download your ChatGPT interaction data, go to Settings > Data controls > and click Export data.
After downloading your ChatGPT conversation data, configure the data inside conversation.json to meet the file structure for Deepchecks. The Deepchecks engine expects your data in CSV format with input and output as mandatory columns. The former represents user inputs or prompts, while the latter represents the model’s response to user inputs. Data.Page and Code beautify are great tools for converting JSON files to CSV.
Other columns that you can include in your file (although not mandatory) are user_interaction_id for identifying individual interactions across different versions, information_retrieval representing the context for the current request, full_promptand annotation representing a human rating of the model’s response – good, bad, or unknown.
You can format your data to use just the user_interaction_id, input, and output columns (we will use this option for our sample data).
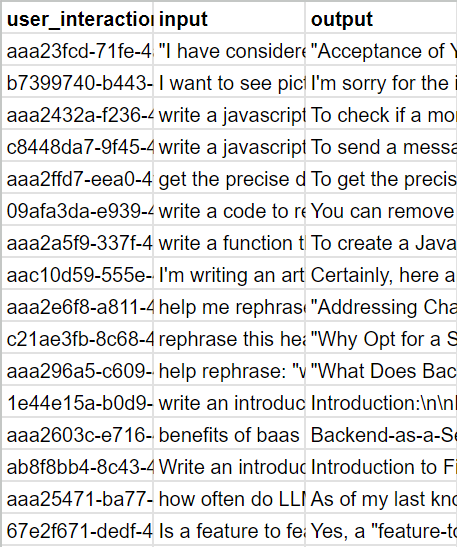
After formatting your data with the appropriate columns, upload it as a CSV file for Deepchecks to evaluate it.
Evaluation
Upon data upload, Deepchecks LLM Evaluation engine automatically evaluates your data, measures its performance, annotates each interaction, flags deviation, etc.
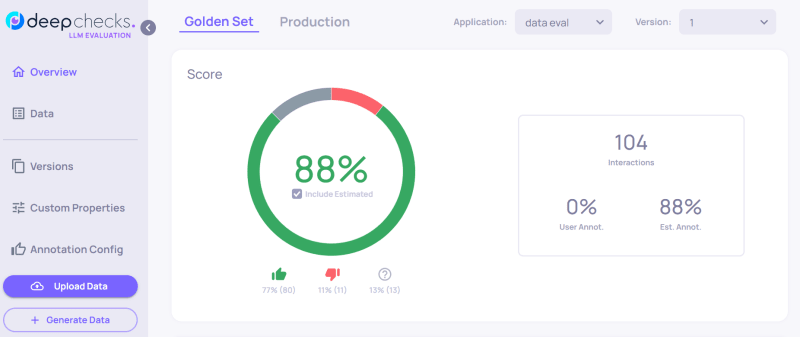
Here is a quick breakdown of our evaluated LLM sample data.
- Deepchecks evaluate each interaction and calculate the average score for the sample data. Our sample data of 104 interactions has 77% good annotation, 11% bad, 13% unknown, and an overall quality score of 88%.
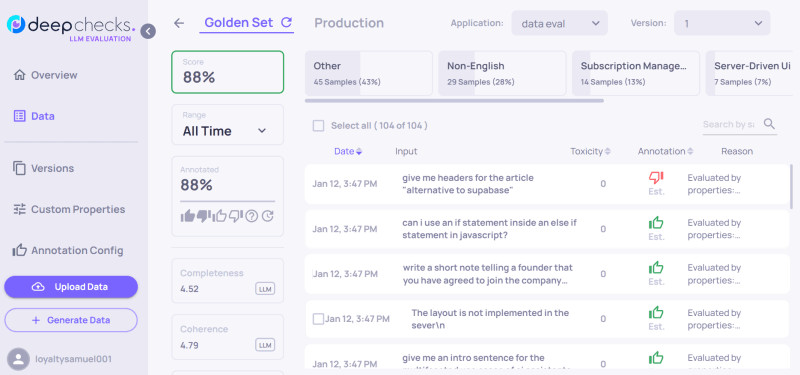
- Deepchecks engine measures for Completeness, Coherence, Relevance, Grounded in Context, Toxicity, and other properties. We can see what areas our model underperforms.
- The engine also identified weak segments in our model.
Conclusion
It is necessary to ensure that your large language models perform optimally. Ineffective models can negatively impact your business if they continue to deliver inaccurate, misleading, or harmful output. Continuously validate your LLMs to understand their performance and flag deviations on time.
Continuous validation and evaluation of LLMs help to optimize their performance, catch deviations on time, prevent hallucination, and protect users from toxic output and privacy leaks. In the article, you learned what continuous LLM evaluation is, why it is necessary to evaluate LLMs, and how to use one of the LLM evaluation tools (Deepchecks LLM Evaluation) to continuously validate your model throughout its lifecycle to ensure good performance.
