Machine learning is the world of data preparation and model building: it consists of complex steps that may become hectic sometimes. Compared to software development, it is harder to get ML into production. So much so that developer teams find it difficult to build and deploy Machine Learning (ML) models at scale. This is because companies haven’t been able to bring DevOps practices to machine learning.
According to a recent study, around 65% of their time was spent on engineering heavy, non-data science tasks such as tracking, monitoring, configuration, compute resource management, serving infrastructure, feature extraction, and model deployment rather than exploring new concepts of ML. This wasted time is a common bottleneck for machine learning teams. The initial requirements and design become obsolete because the journey from experimentation to production is too long. To solve this issue, MLOps comes to the rescue.
In this post, we will discuss:
- DevOps fundamentals
- how is it different from Non-DevOps SDLC
- how DevOps is used in ML
- the model-centric and data-centric approaches
- why there is a need to shift from model-centric to data-centric
What is DevOps?
DevOps is one of the buzzwords created from two words, “Development” and “Operations.” One must not think of DevOps as a technology, tool, or programming language. It is a working practice to produce models from the development to the production stage. The development and the operations team remain in sync to deliver the end product efficiently to the user. Small-scale applications pose little problems because few people manage the software. Things get changed when it comes to large-scale applications like Swiggy, Zomato, or YouTube. Different teams handle different parts of the website, and they collaboratively put it all into a mid-sized or large-sized application.
Typically, the development team is responsible for writing code, designing new features, and testing them. On the other hand, the operations team is responsible for issues like scaling the server, maintaining the bandwidth, and managing the security and backups.
In DevOps practice, both groups sit together to discuss everything side by side. If needed, they exchange roles and responsibilities so that everyone in the team is at the same level of the development cycle. There is no wall of confusion between both teams with the DevOps approach.
The infinity symbol of DevOps signifies that it is a continuous process of improving efficiency and constant activities. There are various phases in DevOps; let’s have a look.

- Planning phase: The development team creates a plan keeping in mind the objectives of the application to be delivered.
- Coding phase: The team works on the coding part of the new feature and keeps the different versions of the code using tools like git and merges it when required.
- Build: Code is made executable with tools like Maven and Gradle.
- Testing phase: Now, the code is tested for any errors and bugs. Selenium is a popular tool for automation testing.
- Deployment phase: Once the code passes several test cases, it is now ready to be deployed and sent to the operation team. They deploy the code to the working environment. Docker and Kubernetes are some of the popular tools to automate this process.
- Monitoring phase: The product is continuously monitored, and the feedback provided is sent back to the planning phase. It creates an infinite cycle.
- Integration phase: This is the core of DevOps. After passing through several tests, the code is sent for deployment; this is called continuous integration.
Non-DevOps workflow vs. DevOps Workflow
There are two popular approaches to proceeding with the development; these are Non-DevOps workflow and DevOps workflow. According to the Gitlab study, 84% of IT people believe that code releases and delivery have accelerated significantly in the last few years due to DevOps practices. Let’s compare both approaches.
| Non-DevOps Workflow | DevOps Workflow |
|---|---|
| Lack of communication between development teams and operation teams. | Smooth interdepartmental collaboration. |
| The goals of the development team and operation teams vary. The former focuses on completing the development part, and the latter ensures that the IT and infra parts are functional. | Both teams support each other and have a common goal to achieve. They both focus on delivering value to customers with continuous and fast delivery. |
| Software releases often get postponed. | Well-organized scheduled and on-demand releases. |
| A significant amount of time is required to fix any post-release defects. | It is possible to roll back the latest updates automatically, so users are not affected. |
| There is a lack of testing. | Most testing operations are automated as a part of the release procedure. |
| Teams have a risk-averse mindset. | Teams have a risk-aware mindset; they are prepared to fail and recover early with pre-planned strategies. |
| The non-devOps way of working does not increase the productivity of businesses and IT teams. | DevOps way of working increases the productivity of businesses and IT teams. |
| Maintenance and upgrade cost is higher. | Maintenance and upgrade cost is less. |
| Merge conflicts are more likely to appear after deployment to production which causes irregularities and higher chances of post-production defects. | Software changes are automatically merged, tested, and deployed with less effort. |
| Non-DevOps workflows are biased towards planning big projects that involve a lot of code with bundled releases and jammed production. | DevOps workflow believes in taking smaller steps because large batch sizes might become complex and risky. With small projects, releases are frequent and more responsive to the customers. |
Benefits of DevOps
Here are some of the benefits we get with DevOps:
- DevOps accelerates the Innovation: A 2023 Accelerate State of DevOps Report published by the DevOps Research and Assessment DORA team at Google Cloud found teams with generative cultures composed of people who felt included on their team have 30% higher organizational performance than organizations without a generative culture. Because of this, they spend more time on new work and innovations, upscale themselves in markets, and provide better products to their customers.
- DevOps accelerates the business: Implementing DevOps accelerates the expansion of your company in several domains. DevOps may enhance customer satisfaction, employee satisfaction, corporate efficiency, and teamwork with cohesive communication and a collaborative atmosphere.
- Transparency: DevOps allows transparency in work, which helps easy communication between the teams and lets them be more focused in their specialized fields. This leads to an upsurge in production and competence among employees of the company.
- Balanced work environment: DevOps practice helps to stabilize the work environment. It reduces the tension involved in new releases or fixes that affect overall productivity.
- Improved product quality: A good collaboration between the data scientist and operation team and continuous user feedback leads to improved product quality. A better product not only helps in business growth but also improves customer satisfaction levels.
- Automated tasks: Unlike the non-devOps model, DevOps helps in detecting and fixing the problem more efficiently. The defects are repeatedly tested automatically, and teams get the bandwidth to frame more new ideas.
- Minimal cost: A suitable collaborative work environment of DevOps helps to cut down the management and production costs of the departments as the process of maintenance and working on new updates is brought under a single broader umbrella.
- Sufficient test and probability of fewer errors: Non-DevOps models lack continuous testing in the development phase. If the product is functionally complex, the tests conducted in the non-DevOps model are not sufficient to properly detect flaws that affect the product’s quality. But in DevOps, there is continuous testing of the product after every stage to avoid post-release bugs.
MLOps: What is DevOps for the ML World?
MLOps is one of the hot concepts in the world of Artificial Intelligence. It stands for Machine Learning Operation s and involves data scientists and operations teams working parallel to produce efficient models.
MLOps is DevOps in the context of machine learning. The idea of MLOps has added value to the business by making it faster and more reliable than ever before. Previously, the projects used to get stuck in the experiment phase; they could not make it into production, thus making it difficult for companies to deliver their ML product on time.
MLOps has automated the lifecycle of ML algorithms in production, i.e., from initial training to deployment to re-training the model with new data. Teams can combine their skills, tools, and techniques in machine learning, data engineering, and DevOps. In this way, firms are using the power of MLOps to optimize the performance and stretch of ML models.
How to implement MLOps
There are three ways to implement MLOps. The choice among them depends on the organization’s size and the number of ML algorithms to run. They are as follows:
1. Manual process (MLOps level 0): As the name suggests, ML workflows are entirely manual here. This practice is typical for companies that have just started using machine learning. This way of implementing MLOps is adequate for non-technical companies like insurance agencies and banks who upgrade their models once a year or in any financial crisis.
Below are some characteristics of level 0 MLOps:
- As discussed above, each step is executed manually. These steps include data preparation, data analysis, model training, and model validation. Even the transition from one phase to another is also manual.
- There is a disconnection between machine learning and the operations team. The ML team does all the work from the initial data extraction step to the final stage of the model registry and hands over the model to the engineering team. They deploy the model to their API infrastructure.
- It isn’t easy to have velocity in model training because of the manual process, which leads to infrequent releases.
- Due to a lack of changes and frequent model version deployments, continuous integration and delivery are less considered.
- It is difficult to determine when to re-train the model since there is no tracking of model performance.
2. ML pipeline automation (MLOps level 1): Machine learning pipelines are automated at this level, as the aim is to achieve continuous training of the ML models. This process includes automating training with new data, modelling re-training in production, automating data validation and model validation, introducing triggers to initiate pipelines, and storing machine learning model metadata.
Below are some of the characteristics of level 1 MLOps:
- ML steps are planned and done automatically.
- The training of models into production is automatically done using new data.
- There is modularized code for components and pipelines so that the components are reusable and shareable across ML pipelines.
- Unlike level 0 MLOps, the whole training pipeline is deployed in production and is trained on a fresh set of data present in the production.
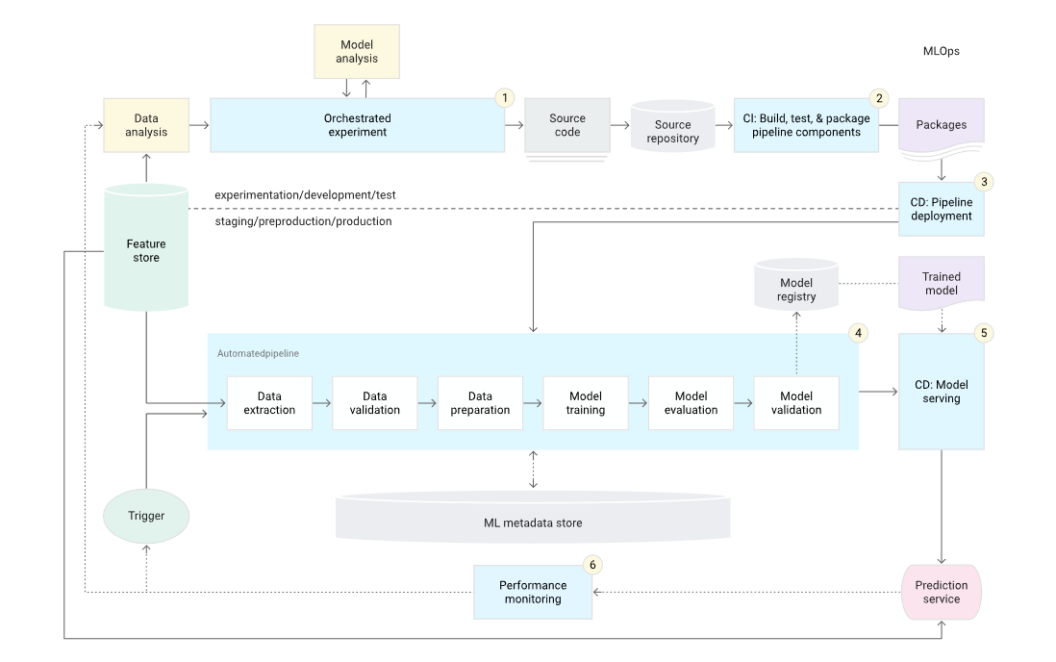
3. CI/CD pipeline automation (MLOps level 2): For quick and reliable updates on the ML pipeline, we need a robust automated CI/CD pipeline that allows data scientists to explore new ideas related to hyperparameter tuning, feature engineering, and model architecture.
This level is suitable for companies who re-train their model daily and re-deploy on several servers simultaneously. It will be difficult for these kinds of companies to survive without the practice of MLOps. The components included in the setup are a feature store, model registry, source control, test and build services, deployment services, metadata store, and pipeline orchestrator.
Below are some of the characteristics of level 2 MLOps:
- Experimentation and development: You repeatedly try out new ML algorithms and models where experimentation steps are planned.
- CI pipeline: You build source code and perform various tests, and the output of this step is pipeline components (executable, packages, and artefacts) that need to be deployed later.
- CD pipeline: The artefacts produced in the CI stage are deployed to the target environment. The result of this step is a deployed pipeline with the new implementation of the model.
- Automated triggering: The ML pipeline executes automatically in the production based on the schedule or in response to the trigger.
- Monitoring: Stats are prepared based on the model performance on live data. The output of this step sets off to execute a new experiment cycle.
MLOps is becoming an upcoming trend in the world of Artificial Intelligence. Let’s look into some of its benefits:
- Fast innovation through efficient machine learning lifecycle: MLOps solution makes collaboration possible for data processing teams, ML professionals, and IT engineers. It increases the speed of model development and its deployment with the help of monitoring, validation, and management systems for machine learning models.
- Optimize team’s productivity: MLOps allows integration with ongoing workflows to provide intelligible roles and reduce time wastage and obstacles between the groups. It permits constant access to monitor and report on existing projects to make timely decisions.
- Create reproducible workflows and models: MLOps use the concept of dataset registries and advanced model registries for tracking the resource. It provides improved traceability by tracking code, data, and metrics in the execution log. It also helps in creating machine learning pipelines to design, deploy, and administer reproducible model workflows for consistent model delivery.
- Easy model deployment: MLOps allows for the deployment of high-precision models with speed and confidence. It uses automatic scaling and manages clusters of CPUs and GPUs with distributed learning in the cloud. Additionally, it packs models quickly, ensuring high quality at every step through the use of profiling and model validation.
Conclusion
The integration of DevOps practices in the realm of machine learning data is not just a necessity but a crucial catalyst for innovation and efficiency. The complexities of managing vast datasets, continuous model training, and seamless deployment demand a collaborative and automated approach that DevOps methodologies provide. DevOps ensures a streamlined workflow, enabling faster iterations, better collaboration, and ultimately, the delivery of more reliable and accurate machine learning models. The combination of DevOps and ML data not only accelerates the development process but also enhances the overall quality of machine learning applications, making it an indispensable partnership in the rapidly evolving landscape of technology and data science.
