Introduction
Elixir is a recent language built on top of the battle-tested BEAM virtual machine, which is steadily gaining traction among companies and developers. It brings a modern and fresh perspective to the Erlang world, and with it we can easily build reliable and fault-tolerant applications. Other than that, one of Elixir’s main strengths is productivity.
Goals of This Tutorial
We will bootstrap csv, a generic and reusable library to parse and import CSV files. You will learn about:
- Using Agents to fulfill testing needs,
- Testing file IO,
- How to leverage Streams and how they work internally, and
- Parallelizing work on a pipeline.
Let’s get started!
Prerequisites
For this article, you will need:
- Basic knowledge about Elixir and ExUnit and
- Elixir 1.5 installed on your computer.
To get acquainted with ExUnit and the mechanics of Test-Driven Development, I recommend you to check out our Introduction to Testing Elixir Applications with ExUnit.
Creating the CSV Application
We will start with creating our project. Let’s call it admin:
mix new admin
Mix helpfully gives some hints on what to do next:
* creating README.md
* creating .gitignore
* creating mix.exs
* creating config
* creating config/config.exs
* creating lib
* creating lib/test.ex
* creating test
* creating test/test_helper.exs
Your Mix project was created successfully.
You can use "mix" to compile it, test it, and more:
cd test
mix test
Run "mix help" for more commands.
As a sanity measure, let’s run the tests generated by Mix and make sure they pass:
$ mix test
..
Finished in 0.03 seconds
2 tests, 0 failures
Randomized with seed 464454
Before advancing, do delete those tests because we won’t need them:
rm -f test/csv_test.exs
Test-driving the Import Module
As top-down TDD suggests, let’s start with a high-level test describing the outcome we expect. An outline may be helpful:
- Receive a path to the CSV file,
- Parse rows and insert them into a repository, and
- Retrieve rows back from the repository and assert whether they match the CSV’s.
Since this code is meant to work on any CSV definition, we will give it three arguments – a file path, a struct atom, and a list of expected headers. The struct will be used as a schema on each CSV row, and the headers will be used to make sure the file conforms to an expected structure.
Using any schema is possible for this test, so let’s stick with something simple: a Site struct with two fields: name and url. As for the repository, its role will be to insert rows into a persistence layer, but let’s not worry about that for now.
Given our plan, TDD leans toward picturing client code before it even exists:
options = [schema: Csv.Schemas.Site, headers: [:name, :url]]
Csv.Import.call("test/fixtures/sites.csv", options)
Great, now we’re off to a good start with an integration test:
# test/csv/import_test.exs
defmodule Csv.ImportTest do
use ExUnit.Case
alias Csv.Schemas.Site
alias Csv.Repo
test "imports records of a csv file" do
options = [schema: Site, headers: [:name, :url]]
"test/fixtures/sites.csv" |> Csv.Import.call(options)
assert [
%Site{name: "Elixir Language", url: "https://elixir-lang.org"},
%Site{name: "Semaphore Blog", url: "https://semaphore.io/blog"}
] = Repo.all
end
end
After running it with mix test, a compile error will say Site module cannot expand to a struct. To fix it, create a struct with name and url fields:
# test/support.exs
defmodule Csv.Schemas.Site do
defstruct name: '', url: ''
end
Next, require support.exs in test_helper.exs:
# test/test_helper.exs
ExUnit.start()
Code.require_file "test/support.exs"
Running our tests at this point should fail with the following error:
1) test imports records of a csv file (Csv.ImportTest)
test/csv/import_test.exs:6
** (UndefinedFunctionError) function Csv.Import.call/2 is undefined (module Csv.Import is not available)
Creating the Main Module
The error message hints at defining a Csv.Import.call/2 function. Let’s do the bare minimum to keep the flow coming:
# lib/csv/import.ex
defmodule Csv.Import do
def call(_input_path, _options) do
end
end
As expected, we hit another error when rerunning our tests: we don’t have a repository.
1) test imports records of a csv file (Csv.ImportTest)
test/csv/import_test.exs:6
** (UndefinedFunctionError) function Csv.Repo.all/0 is undefined (module Csv.Repo is not available)
Creating an In-memory Repository with Agent
Agents are simple wrappers around state. Among other utilities, they are perfect to simulate external boundaries such as databases, especially when all you need to do is set and retrieve some data. Most importantly, we want to avoid setting up a database because our library will delegate that responsibility away.
In Elixir and Erlang, processes are commonly used to maintain state by running a recursive loop where data is repeatedly passed to the same function. Agents are abstractions over exactly that definition.
Our Agent will run in a separate process and remember any state we pass in:
# test/support.exs
defmodule Csv.Repo do
@me __MODULE__
def start_link do
Agent.start_link(fn -> [] end, name: @me)
end
def insert(record) do
Agent.update @me, fn(collection) -> collection ++ [record] end
{:ok, record}
end
def all do
Agent.get(@me, fn(collection) -> collection end)
end
end
Let’s go over each function: Csv.Repo.start_link/0 uses Agent.start_link/2 to spawn a process named after the current module, Csv.Repo, which in turn is assigned to the @me module attribute as to have a central spot of reference. Moreover, the anonymous function passed to Agent.start_link/2 returns an empty list, which the Agent sets as its initial state.
As for Csv.Repo.insert/1, it calls Agent.update/2 with two arguments: the process’ name and an anonymous function, which appends the record to the Agent’s state. Although that function comes from the client, its lexical environment is carried over and it runs in the Agent process.
Finally, Csv.Repo.all/0 is set to fetch the entire state back.
Using our Agent is very simple, let’s try it out in iex:
$ iex -S mix
Interactive Elixir (1.5.0) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> Code.require_file "test/support.exs"
[{Csv.Schemas.Site,
<<70, 79, 82, 49, 0, 0, 13, 12, 66, 69, 65, 77, 65, 116, 85, 56, 0, 0, 1, 204,
0, 0, 0, 46, 30, 69, 108, 105, 120, 105, 114, 46, 67, 115, 118, 46, 70, 105,
120, 116, 117, 114, 101, 115, 46, 83, 105, 116, ...>>}]
iex(2)> Csv.Repo.start_link
{:ok, #PID<0.178.0>}
iex(3)> Csv.Repo.insert %Csv.Schemas.Site{name: "Semaphore Blog"}
{:ok, %Csv.Schemas.Site{id: nil, name: "Semaphore Blog", url: nil}}
iex(4)> Csv.Repo.insert %Csv.Schemas.Site{name: "Elixir Language"}
{:ok, %Csv.Schemas.Site{id: nil, name: "Elixir Language", url: nil}}
Since Mix does not compile exs files, we had to explicitly require support.exs to reach our Csv.Schemas.Site struct. Then we started an agent process with Csv.Repo.start_link/0 and performed some Site insertions with Csv.Repo.insert/1. Now, we can fetch all of our structs back with Csv.Repo.all/0:
ex(5)> Csv.Repo.all
[%Csv.Schemas.Site{id: nil, name: "Semaphore Blog", url: nil},
%Csv.Schemas.Site{id: nil, name: "Elixir Language", url: nil}]
Making Our Test Pass
We should have a new error at this time:
1) test imports records of a csv file (Csv.ImportTest)
test/csv/import_test.exs:6
** (exit) exited in: GenServer.call(Csv.Repo, {:get, #Function<0.78900424/1 in Csv.Repo.all/0>}, 5000)
** (EXIT) no process: the process is not alive or there's no process currently associated with the given name, possibly because its application isn't started
Don’t get fooled by the seemingly strange GenServer reference. Under the covers, that’s what Agent uses. That message means that we didn’t start Csv.Repo before running our code, so change import_test.exs to look like this:
# test/csv/import_test.exs
defmodule Csv.ImportTest do
use ExUnit.Case
alias Csv.FixtureSchemas.Site
alias Csv.Repo
test "imports records of a csv file" do
Repo.start_link # This line starts our agent
options = [schema: Site, headers: [:name, :url]]
"test/fixtures/sites.csv" |> Csv.Import.call(options)
assert [
%Site{name: "Elixir Language", url: "https://elixir-lang.org"},
%Site{name: "Semaphore Blog", url: "https://semaphore.io/blog"}
] = Repo.all
end
end
Now we have our first actual failure:
1) test imports records of a csv file (Csv.ImportTest)
test/csv/import_test.exs:6
match (=) failed
code: assert [%Site{name: "Elixir Language", url: "https://elixir-lang.org"}, %Site{name: "Semaphore Blog", url: "https://semaphore.io/blog"}] = Repo.all()
right: []
stacktrace:
test/csv/import_test.exs:12: (test)
This makes sense. Since we have not inserted any records, Repo.all/0 returns the initial state: an empty list. Adding to that, Csv.Import.call/2 is not doing anything. Let’s outline the required steps to make our test pass:
defmodule Csv.Import do
def call(_input_path, _options) do
# 1. Read the CSV line by line
# 2. Parse lines from strings into structs
# 3. Insert each struct into the repository
end
end
To fulfill step 1, retrieve raw lines out of the file:
lines = "test/fixtures/sites.csv"
|> File.read!()
|> String.split("\n")
|> Enum.drop(1)
|> Enum.reject(&(String.trim(&1) == ""))
It’s worth explaining each step of this pipeline:
File.read!/1reads file contents into a string.String.split/2splits the string by newline and returns a list.Enum.drop/2discards the first item off the list, which corresponds to the headers.- Rejecting any empty lines with
Enum.reject/2.
Next, we will split each row by comma and use pattern matching to extract name and url fields, putting all data in structs after that:
structs = lines
|> Enum.map(&String.split(&1, ","))
|> Enum.map(fn([name, url]) ->
%Csv.Schemas.Site{name: name, url: url}
end)
Finally, we will pass each struct onto the repository, so that it takes care of persistence. The side-effectful Enum.each/2 instead of Enum.map/2 fits the bill just right, since we don’t need to pipe return values onward.
structs
|> Enum.each(&Csv.Repo.insert/1)
To wire up the above code correctly in our function, we will use input_path as the CSV path and use options[:schema] to create a struct on-the-fly with Kernel.struct/2. We can’t use struct shorthands because they merely support static atom references:
# lib/csv/import.ex
defmodule Csv.Import do
def call(input_path, options) do
input_path
|> File.read!
|> String.split("\n")
|> Enum.drop(1)
|> Enum.reject(&(String.trim(&1) == ""))
|> Enum.map(&String.split(&1, ","))
|> Enum.map(fn([name, url]) ->
struct(options[:schema], %{name: name, url: url})
end)
|> Enum.each(&Csv.Repo.insert/1)
end
end
And don’t forget to create sites.csv file under test/fixtures:
name,url
Elixir Language,https://elixir-lang.org
Semaphore Blog,https://semaphore.io/blog
Tests should now be green:
$ mix test
==> csv
.
Finished in 0.02 seconds
1 test, 0 failures
Test-driving a Record Stream
Our code is working kind of naively. First of all, parsing rows is not generic as we want, and we can’t use a schema other than Site. These requirements must be flexible, otherwise we won’t make good use out of our library. Secondly, we have lots of logic in a single spot. It’s time to start thinking in terms of new abstractions, splitting up concerns, and making room for growth!
More importantly, we will likely parse thousands of rows, which makes putting a big file into a single string a waste of memory. Furthermore, each map call iterates through the whole collection, thus making our pipeline slower for large inputs.
Streams
What if we could have Elixir read our file line by line, and they flowed through our pipeline in one fell swoop? Turns out we can, by using streams. Streams are composable, lazy enumerables. Suppose we have the following pipeline, where we double and add one to each number of a list:
iex(1)> [1, 2] |> Enum.map(fn(x) -> x * 2 end) |> Enum.map(fn(x) -> x + 1 end)
[3, 5]
Both Enum.map/2 calls iterate over the entire list, summing up a total of two iterations. That may be negligible for small lists, but what about big ones? Streams allow performing a single iteration, and refactoring from eager to lazy is easy:
iex(2)> [1, 2] |> Stream.map(fn(x) -> x * 2 end) |> Stream.map(fn(x) -> x + 1 end) |> Enum.to_list
[3, 5]
Renaming Enum.map to Stream.map and appending Enum.to_list/1 to the pipeline affords a single iteration through the enumerable. Enum.to_list/1 is necessary to trigger the iteration, as any Enum function similarly would.
But how does this work? Elixir being a functional language, functions are first-class citizens and we can compose them. Under the hood, Stream keeps track of an enumerable and functions of the current stream pipeline. For instance:
iex(3)> stream_1 = Stream.map([1, 2], fn(x) -> x * 2 end)
#Stream<[enum: [1, 2], funs: [#Function<47.117392430/1 in Stream.map/2>]]>
iex(4)> stream_2 = stream_1 |> Stream.map(fn(x) -> x + 1 end)
#Stream<[enum: [1, 2],
funs: [#Function<47.117392430/1 in Stream.map/2>,
#Function<47.117392430/1 in Stream.map/2>]]>
The first call to Stream.map/2 creates a %Stream{} struct with two keys: enum, which is the [1, 2] enumerable; and funs, a list holding the anonymous function “multiply number by two” with some mapping logic applied. The second call appends another function, “map each number to plus one”, to the funs list. Thus, no work on enum happens when calling functions on Stream – instead, data is registered in a struct!
However, magic happens when we pipe %Stream{} onto Enum.to_list/1:
iex(5)> stream_2 |> Enum.to_list
[3, 5]
This is possible due to streams implementing the Enumerable protocol. The underlying implementation glues our funs together and runs enum through them. The resulting effect is a single, lazy iteration. Let’s do this work manually, so that you get the idea:
iex(7)> double_number = fn(x) -> x * 2 end
iex(8)> add_one = fn(x) -> x + 1 end
iex(9)> funcs = [double, add_one]
[#Function<6.99386804/1 in :erl_eval.expr/5>,
#Function<6.99386804/1 in :erl_eval.expr/5>]
iex(10)> initial_value = fn(x) -> x end
#Function<6.99386804/1 in :erl_eval.expr/5>
iex(11)> composed = Enum.reduce funcs, initial_value, fn(acc, func) ->
...(12)> fn(x) -> x |> func.() |> acc.() end
...(13)> end
#Function<6.99386804/1 in :erl_eval.expr/5>
iex(14)> composed.(2)
5
iex(15)> [1, 2] |> Enum.map(composed)
[3, 5]
Similarly to what happens on an actual stream, we reduced our functions into a single one (hence Enum.reduce) and ran our enumerable through it. The actual implementation is more complex than that because Stream has a multitude of functions other than Stream.map, but the idea is the same.
Record Streams
It might have become clear to you that our code can benefit from streams. Let’s create a RecordStream module to replace some of our pipeline. It will bundle up the following steps as efficiently as it can:
1. Read the CSV line by line
2. Parse lines from strings into structs
Since this will be a lower-level component, we will step down the abstraction ladder and work with a device instead of a file path. In Elixir and Erlang, we call file handlers devices. After “grabbing” a device, we can use the IO module to perform read and write operations on it:
iex(1)> {:ok, device} = File.open("test/fixtures/sites.csv")
{:ok, #PID<0.195.0>}
iex(2)> IO.read(device, :all)
"name,url\nElixir Language,https://elixir-lang.org\nSemaphore Blog,https://semaphore.io/blog\n"
Surprisingly, devices are implemented as processes:
File.openspawns a new process and returns a pid back to the caller.IOfunctions use the pid to request file operations, to which the process may send a response back depending on the request. Helpfully, these functions abstract away the hurdle of sending and receiving messages.- It’s possible to have any kind of IO device, as long as it implements the required messaging interface.
Elixir provides an in-memory IO interface called StringIO, which can also be controlled by IO functions. Instead of a file path, however, StringIO.open/1 asks for the file contents directly:
iex(1)> {:ok, device} = StringIO.open("name,url\nElixir Language,https://elixir-lang.org")
{:ok, #PID<0.87.0>}
iex(2)> IO.read(device, :all)
"name,url\nElixir Language,https://elixir-lang.org"
Implementing a Record Stream Module
Our record stream needs three arguments: a device, a schema, and the expected headers. Let’s start with the most trivial case – when the file has only headers and thus no rows, it should stream an empty list:
# test/csv/record_stream_test.exs
defmodule RecordStreamTest do
use ExUnit.Case
test "streams an empty list when csv has no rows" do
{:ok, device} = StringIO.open("name,url\n")
{:ok, stream} = Csv.RecordStream.new(device, headers: [:name, :url], schema: Site)
assert [] == Enum.to_list(stream)
end
end
An error will say we haven’t defined RecordStream.new/2. To solve it, introduce that function and make it return a stream which returns an empty list when piped onward:
# lib/csv/record_stream.ex
defmodule Csv.RecordStream do
def new(_device, headers: _headers, schema: _schema) do
stream = Stream.map([], fn(_) -> nil end)
{:ok, stream}
end
end
Our next case will exercise when the CSV has a few rows:
# test/csv/record_stream_test.exs
defmodule RecordStreamTest do
use ExUnit.Case
alias Csv.Schemas.Site
test "streams an empty list when csv has no rows" do
# Imagine the previous test here...
end
test "streams csv rows as structs" do
{:ok, device} = StringIO.open """
name,url
Elixir Language,https://elixir-lang.org
Semaphore Blog,https://semaphore.io/blog
"""
{:ok, stream} = Csv.RecordStream.new(device, headers: [:name, :url], schema: Site)
assert [
%Site{name: "Elixir Language", url: "https://elixir-lang.org"},
%Site{name: "Semaphore Blog", url: "https://semaphore.io/blog"}
] = Enum.to_list(stream)
end
end
It fails because we are still returning an empty list:
1) test streams csv rows as structs (RecordStreamTest)
test/csv/record_stream_test.exs:12
match (=) failed
code: assert [%Site{name: "Elixir Language", url: "https://elixir-lang.org"}, %Site{name: "Semaphore Blog", url: "https://semaphore.io/blog"}] = Enum.to_list(stream)
right: []
We will use IO.stream/2 to lazily read the lines of our file and pipe further by the stream, while stripping newline characters using String.trim/1 and splitting rows by comma:
# lib/csv/record_stream.ex
defmodule Csv.RecordStream do
def new(device, headers: _headers, schema: _schema) do
stream = device
|> IO.stream(:line)
|> Stream.map(&String.trim/1)
|> Stream.map(&String.split(&1, ","))
{:ok, stream}
end
end
Our test fails with an interesting error. We are getting back headers when we shouldn’t:
2) test streams csv rows as structs (RecordStreamTest)
test/csv/record_stream_test.exs:12
match (=) failed
code: assert [%Site{name: "Elixir Language", url: "https://elixir-lang.org"}, %Site{name: "Semaphore Blog", url: "https://semaphore.io/blog"}] = Enum.to_list(stream)
right: [["name", "url"], ["Elixir Language", "https://elixir-lang.org"],
["Semaphore Blog", "https://semaphore.io/blog"]]
Now we need to separate out the headers without unwrapping the stream into a list, for that would defeat using streams in the first place. Streams are enumerables, hence we can use Enum.fetch!/2:
# lib/csv/record_stream.ex
defmodule Csv.RecordStream do
def new(device, headers: _headers, schema: _schema) do
stream = device
|> IO.stream(:line)
|> Stream.map(&String.trim/1)
|> Stream.map(&String.split(&1, ","))
# This variable name starts with an underline because
# we are not using it
_headers = stream |> Enum.fetch!(0)
{:ok, stream}
end
end
A keen reader will find it strange that headers are no longer showing up on the right hand side of the assertion:
1) test streams csv rows as structs (RecordStreamTest)
test/csv/record_stream_test.exs:12
match (=) failed
code: assert [%Site{name: "Elixir Language", url: "https://elixir-lang.org"}, %Site{name: "Semaphore Blog", url: "https://semaphore.io/blog"}] = Enum.to_list(stream)
right: [["Elixir Language", "https://elixir-lang.org"],
["Semaphore Blog", "https://semaphore.io/blog"]]
We dropped the first element off the enumerable, and that inadvertently mutated our stream and returned the remaining rows. Isn’t Elixir immutable? Before answering that question, let’s try the same thing out with a plain list:
iex(1)> list = [1, 2, 3, 4]
[1, 2, 3, 4]
iex(2)> list |> Enum.fetch!(0)
1
iex(3)> list
[1, 2, 3, 4]
As you can see, our list remained the same after calling Enum.fetch!/2 on it. But with devices it is different – remember they are processes? The side-effect of enumerating over an IO stream is that, while reading or writing to a file, the device updates an internal pointer to keep track of the current position. This is much like IO works in Ruby, which may be unexpected for newcomers. But it was an Erlang design decision.
Next, let’s use the headers function argument to assist with mapping rows into structs. We can build a keyword list out of headers and rows using Enum.zip:
iex(1)> keys = [:name, :url]
[:name, :url]
iex(2)> values = ["Elixir Language", "https://elixir-lang.org"]
["Elixir Language", "https://elixir-lang.org"]
iex(3)> kwlist = Enum.zip(keys, values)
[name: "Elixir Language", url: "https://elixir-lang.org"]
Now we need to transform the keyword list into a map and then into a struct. We can do that with Enum.into/2 and Kernel.struct/2:
iex(5)> Enum.into(kwlist, %{})
%{name: "Elixir Language", url: "https://elixir-lang.org"}
iex(6)> struct(Csv.Schemas.Site, kwlist)
%Csv.Schemas.Site{name: "Elixir Language", url: "https://elixir-lang.org"}
Now we have all the puzzle pieces to get our tests passing:
# lib/csv/record_stream.ex
defmodule Csv.RecordStream do
def new(device, headers: headers, schema: schema) do
stream = device
|> IO.stream(:line)
|> Stream.map(&String.trim/1)
|> Stream.map(&String.split(&1, ","))
|> Stream.map(fn(row) ->
contents = headers
|> Enum.zip(row)
|> Enum.into(%{})
struct(schema, contents)
end)
_headers = stream |> Enum.fetch!(0)
{:ok, stream}
end
end
And sure enough they do:
...
Finished in 0.03 seconds
3 tests, 0 failures
Validating the Headers
We are missing out two important cases. First, our code must still work with shuffled headers. Secondly, we need to ensure the file has the right columns. Here are the tests:
# test/csv/record_stream_test.exs
test "streams correctly when headers are shuffled" do
{:ok, device} = StringIO.open """
url,name
https://elixir-lang.org,Elixir Language
"""
{:ok, stream} = Csv.RecordStream.new(device, headers: [:name, :url], schema: Site)
assert [
%Site{name: "Elixir Language", url: "https://elixir-lang.org"},
] = Enum.to_list(stream)
end
test "returns :invalid_csv when missing required columns" do
{:ok, device} = StringIO.open """
name
Elixir Language
"""
assert :invalid_csv == Csv.RecordStream.new(device, headers: [:name, :url], schema: Site)
end
Let’s make the first one pass. Instead of creating structs using the headers function argument, we can use headers from the file instead, since they dictate column order. Furthermore, converting all headers into atoms is necessary, due to keys of keyword lists being atoms:
headers = stream
|> Enum.fetch!(0)
|> Enum.map(&String.to_atom/1)
structs = stream
|> Stream.map(fn(row) ->
# Uses headers from the file to build up structs
contents = headers
|> Enum.zip(row)
|> Enum.into(%{})
struct(schema, contents)
end)
The second one is also simple, and requires conditional logic to determine whether the headers we are dealing with are the ones we expect. If so, we return {:ok, structs}, otherwise :invalid_csv:
if Enum.sort(headers) == Enum.sort(expected_headers) do
# ... Code to figure out the structs comes here
{:ok, structs}
else
:invalid_csv
end
Combined, these cases make headers unbreakable! After putting it all together, here’s the resulting code:
# lib/csv/record_stream.ex
defmodule Csv.RecordStream do
def new(device, headers: expected_headers, schema: schema) do
stream = device
|> IO.stream(:line)
|> Stream.map(&String.trim/1)
|> Stream.map(&String.split(&1, ","))
headers = stream
|> Enum.fetch!(0)
|> Enum.map(&String.to_atom/1)
if Enum.sort(headers) == Enum.sort(expected_headers) do
structs = stream
|> Stream.map(fn(row) ->
contents = headers
|> Enum.zip(row)
|> Enum.into(%{})
struct(schema, contents)
end)
{:ok, structs}
else
:invalid_csv
end
end
end
Refactoring
Our code works, but there is too much complexity in a single function. To solve that issue, we recommend extracting logical chunks onto private functions. Good tests make refactoring easy, so you should take small steps and run them constantly during the process. Here’s an idea of how you might reorganize the module:
# lib/csv/record_stream.ex
defmodule Csv.RecordStream do
def new(device, headers: expected_headers, schema: schema) do
stream = device |> to_stream
headers = stream |> extract_headers
if valid_headers?(headers, expected_headers) do
{:ok, Stream.map(stream, &to_struct(&1, schema, headers))}
else
:invalid_csv
end
end
def valid_headers?(headers, valid_headers) do
Enum.sort(headers) == Enum.sort(valid_headers)
end
defp to_stream(device) do
device
|> IO.stream(:line)
|> Stream.map(&String.trim/1)
|> Stream.map(&String.split(&1, ","))
end
defp extract_headers(stream) do
stream
|> Enum.fetch!(0)
|> Enum.map(&String.to_atom/1)
end
defp to_struct(row, schema, headers) do
headers
|> Enum.zip(row)
|> Enum.into(%{})
|> (fn(contents) -> struct(schema, contents) end).()
end
end
And all tests should still be passing.
Parsing the CSV Properly
Our in-house CSV parser is fragile and bound to break upon certain scenarios. What if the CSV has commas in between contents? Let’s just use a good library: We recommend NimbleCSV from Plataformatec. It is simple and relies on binary pattern matching for efficiency, having no dependencies other than itself. Include it in mix.exs:
# mix.exs
defp deps do
[
{:nimble_csv, "~> 0.1.0"}
]
end
And install dependencies:
mix deps.get
By default, this library ships with NimbleCSV.RFC4180, which is the most common implementation of CSV parsing/dumping available using comma as separators and double-quote as escape. Thankfully, it works with streams out of the box. Just change this function:
# lib/csv/record_stream.ex
defp to_stream(device) do
device
|> IO.stream(:line)
|> Stream.map(&String.trim/1)
|> Stream.map(&String.split(&1, ","))
end
Into this:
# lib/csv/record_stream.ex
defp to_stream(device) do
device
|> IO.stream(:line)
|> NimbleCSV.RFC4180.parse_stream(headers: false)
end
Because we are handling the headers elsewhere, we pass headers: false to NimbleCSV.RFC4180.parse_stream/2.
And all tests will still be green.
Plugging Record Stream into Import
It’s time to plug our rock-solid Csv.RecordStream into Csv.Import – and we expect tests to still pass after that! We will replace most of the pipeline in Csv.Import, except for the repository part:
# lib/csv/import.ex
defmodule Csv.Import do
alias Csv.RecordStream
def call(input_path, schema: schema, headers: headers) do
{:ok, device} = File.open(input_path)
{:ok, stream} = RecordStream.new(device, headers: headers, schema: schema)
stream |> Enum.each(&Csv.Repo.insert/1)
end
end
Parallelizing Insertions
We are not leveraging any of Elixir’s concurrency features to make things faster. The bulk of our processing regards interacting with a repository, which happens sequentially in our code:
stream |> Enum.each(&Csv.Repo.insert/1)
It’s possible to use Task.async_stream/4 to run a given function concurrently on each item of an enumerable. But there is a catch: database connections are bound to a certain pool size, therefore we must limit the amount of simultaneous connections to avoid errors. Even though we aren’t dealing with a database yet, we want to provide sane defaults, and Task.async_stream/4 accepts a max_concurrency option for just that. This kind of rate control is usually called back-pressure.
Task.async_stream/4 asks for an MFA, which stands for module/function/arguments. For us, that will be Csv.Repo, :insert, and an empty list because there are no arguments other than the struct, which is already passed as the first argument.
Replacing Enum.each/2 with Task.async_stream and setting max_concurrency to 10 (for now) shall do what we want:
# lib/csv/import.ex
defmodule Csv.Import do
alias Csv.RecordStream
def call(input_path, schema: schema, headers: headers) do
{:ok, device} = File.open(input_path)
{:ok, stream} = RecordStream.new(device, headers: headers, schema: schema)
stream
|> Task.async_stream(Csv.Repo, :insert, [], max_concurrency: 10)
|> Enum.to_list
end
end
Tests still pass after that change. Our import routine became lightning fast.
Setting up Testing on Semaphore CI
To complete the first part of our tutorial, let’s setup our project on Semaphore CI. If you don’t have a Semaphore account, you can create one for free.
First, add the source files to git and push them to GitHub or BitBucket.
After logging into Semaphore, select “Create new” -> “Project”:
Semaphore will ask you to configure either GitHub or BitBucket, so just follow the authorization steps.
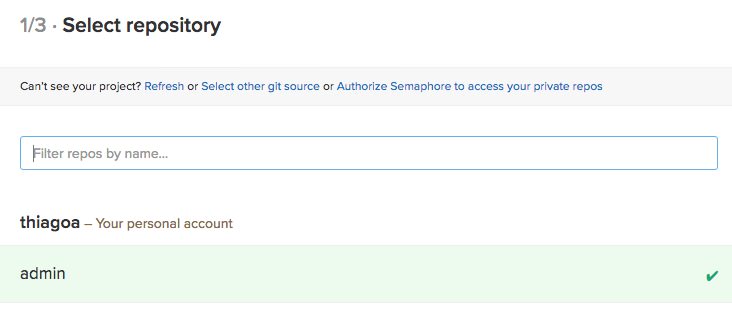
Next, choose the correct repository:
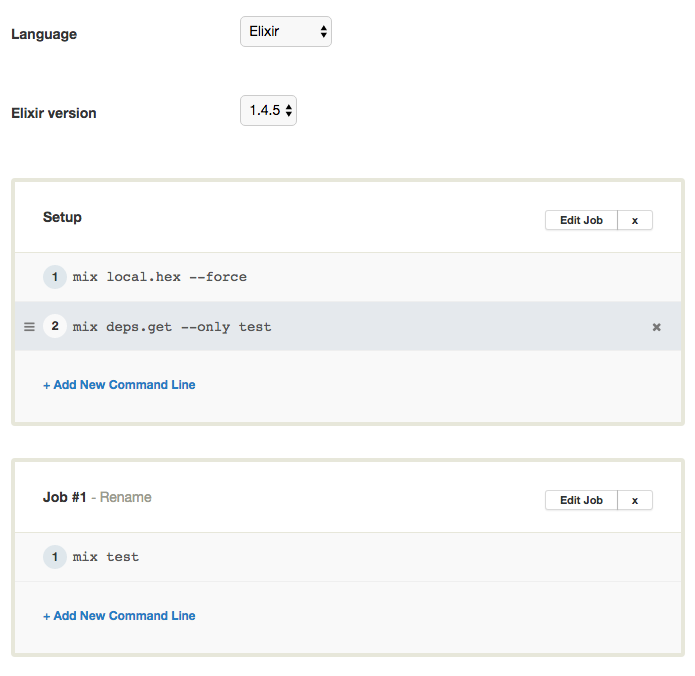
Choose Elixir version 1.4.5 (1.5 is not available at the time of this writing) and setup build steps to look like this:
Click on the “Build With These Settings” button and wait for the build to complete and the tests to pass:
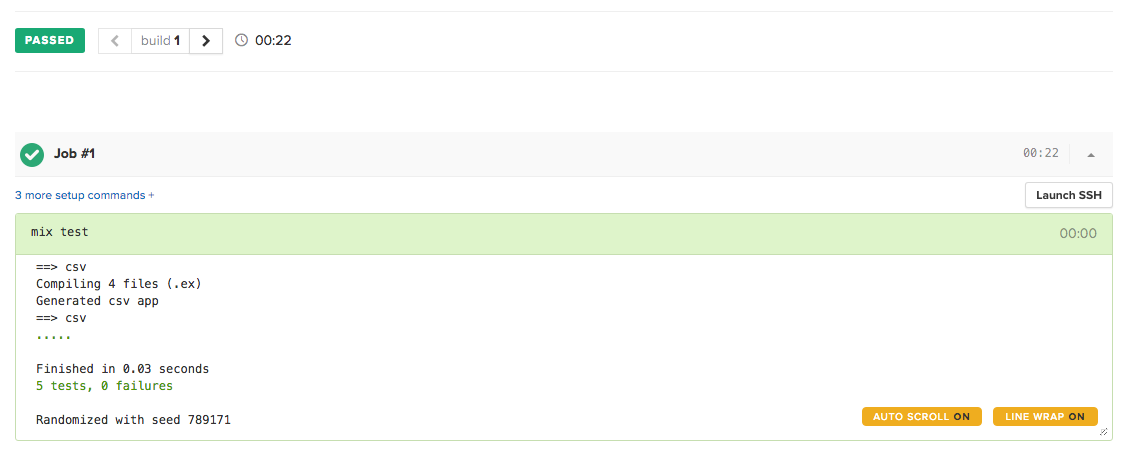
Congratulations! Now you have rock solid continuous integration at your fingertips.
Conclusion
Hopefully, this article has shown you how powerful and flexible streams and pipelines can be together. Toward the end, adding concurrency and robust CSV parsing required minimal changes to the code. You can check out all of the code in this git repository.
In the next article, we will take a tour around mocking and stubbing techniques and explore scenarios where this practice makes sense. See you there!
