Introduction
This tutorial is the third in our series on container orchestration with Docker Swarm. The first tutorial covered how to bootstrap a Docker Swarm Mode cluster, and the second tutorial covered how to schedule workloads across a Swarm cluster. This tutorial explores the topic of service consumption, both from within and externally to a Swarm cluster.
When we deploy microservices as containers across a compute cluster such as a Docker Swarm cluster, it’s critical that we have a means of service discovery to call upon. It’s central to our ability to consume services effectively.
As we learnt in the previous article in this series, we entrust the platform’s scheduling capability to distribute our services across the cluster’s nodes. If a service needs to consume another service running within the cluster, how does it know where to find it? Services can be scaled, so how does a consumer service know which of the containers, that make up the providing service, to address in order to consume the service? If we’ve scaled a service, how do we ensure that service requests are balanced optimally across the service’s containers? Containers are ephemeral, coming and going all the time. How does a consumer service keep track of where to address its service requests?
All of these questions regarding internal service provision and consumption apply equally well to external consumers of a service running on a cluster.
These issues pertain to, and are addressed by, service discovery techniques. Container orchestration platforms such as Docker Swarm and Kubernetes provide in-built service discovery for the container-based service abstraction.

Prerequisites
In order to follow the tutorial, the following items are required:
- a four-node Swarm Mode cluster, as detailed in the first tutorial of this series,
- a single manager node (
node-01), with three worker nodes (node-02,node-03,node-04), and - a direct, command-line access to each node, or, access to a local Docker client configured to communicate with the Docker Engine on each node.
The most straightforward configuration can be achieved by following the first tutorial. All commands are executed against the manager node, node-01, unless explicitly stated otherwise.
Internal Service Consumption
Networking
When a service with a single replica is created in a Swarm Mode cluster, a task in the form of a container is scheduled on one of the cluster’s nodes. Let’s do this using a service based on the Nginx web server:
$ docker service create --detach=false --name nginx nbrown/nginxhello
i070sg1etczdksllevc47slpg
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Waiting 1 seconds to verify that tasks are stable...
The container started for the single task associated with the service, and will be connected to the local bridge network of the Docker host running on the node in question. We can see this by establishing which cluster node the single service replica has been scheduled on, and then inspecting the container. First, let’s see where the container has been scheduled (the --format config option and argument de-clutters the output):
$ docker service ps --format 'table {{.ID}}\t{{.Name}}\t{{.Node}}\t{{.CurrentState}}' nginx
ID NAME NODE CURRENT STATE
qa2qrwdxqjt3 nginx.1 node-02 Running 40 seconds ago
Having established which node the service task is running on (node-02 in this case), we can inspect the associated container, using the docker container inspect command. The JSON returned by the API call, can be pretty printed using the jq JSON processor, or Python’s json.tool. On the relevant node (node-02 in this case):
$ docker container inspect --format '{{json .NetworkSettings.Networks}}' $(docker container ls -lq) | jq '.'
{
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "83875bad2921abd87b45370f653d1a02c8085f4bb675bf688d3c5cdc8cb05602",
"EndpointID": "a34adc8b547ab58e8bff71a9dd96c8d32042f64667cc70fd301613c2b06e298d",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:02"
}
}
It would be possible for us to expose this service to the external world, but having the task’s container attached to Docker’s default bridge network does not help with intra-cluster service communication. The scope of the bridge network is limited to the local cluster node, and services running on other nodes will be unable to consume our nginx service. We can list the bridge networks on the relevant node, in this case node-02:
$ docker network ls --filter type=builtin --filter driver=bridge
NETWORK ID NAME DRIVER SCOPE
83875bad2921 bridge bridge local
Notice the ‘scope’ field and its value. We’ve finished with the nginx service, so let’s remove it:
$ docker service rm nginx
nginx
Docker has advanced networking features built in to the Docker Engine, which cater for standalone Docker hosts, as well as clustered Docker hosts. It provides the means to create overlay networks, based on VXLAN capabilities, which enable virtual networks to span multiple Docker hosts. This allows containers, and therefore services, to communicate with each other, even though they are running on different Docker hosts.
Creating an overlay network for use in a Docker Swarm cluster is a straightforward exercise. The CLI command, docker network create needs to be executed on a manager node, as network state is maintained as part of the cluster state in the Raft log (see the first tutorial in the series for an explanation of the Raft log). We need to specify which driver to use, which defines the network type:
$ docker network create --driver overlay --attachable --subnet 192.168.35.0/24 nginx
4pnw0biwjbns0bjg4ey6cepri
$ docker network ls --filter 'name=nginx'
NETWORK ID NAME DRIVER SCOPE
4pnw0biwjbns nginx overlay swarm
The --subnet config option allows us to specify a subnet range for this ‘network segment’, whilst the --attachable config option allows us to connect non-service containers (those started using docker container run) to the network. We’ll make use of the latter to demonstrate some characteristics of Swarm’s service discovery features.
Note that the scope of the network is ‘swarm’, which means that the network spans the Swarm cluster. However, worker nodes won’t have access to the nginx network until a task from a service which is attached to the network, is scheduled on the node. Manager nodes, by virtue of their role in the cluster, have visibility of the created network.
Let’s re-create the nginx service, and specify that the service’s tasks are to be attached to the nginx network, and then constrain its deployment to node-04:
$ docker service create --detach=false --name nginx --network nginx --constraint 'node.hostname==node-04' nbrown/nginxhello
n2tm0nqf6gjbjxf0qf0q6fhe4
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Waiting 1 seconds to verify that tasks are stable...
First, let’s check if the service was deployed to node-04 by listing the tasks running on node-04:
$ docker node ps --format 'table {{.ID}}\t{{.Name}}\t{{.Node}}\t{{.CurrentState}}' node-04
ID NAME NODE CURRENT STATE
r3yuxnq1n3ap nginx.1 node-04 Running 3 minutes ago
With the service’s task running on node-04, we should be able to see the nginx network in the output of the docker network ls command. On node-04:
$ docker network ls --filter 'name=nginx'
NETWORK ID NAME DRIVER SCOPE
4pnw0biwjbns nginx overlay swarm
Executing the same command on one of the other worker nodes, however, renders an empty list. Try it.
Virtual IP
To see how it might be possible to consume a service on a Swarm Mode cluster, we’ll scale our service to run four replicas. Before we scale the service, however, we’ll need to remove the constraint, otherwise all of the tasks will be deployed to node-04:
$ docker service update --detach=false --constraint-rm 'node.hostname==node-04' nginx
nginx
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Waiting 1 seconds to verify that tasks are stable...
A service update may result in the single task running on a different node to the original node-04, but if we scale our service to four tasks, we should have a service task running on each of our four nodes:
$ docker service scale nginx=4
nginx scaled to 4
$ docker service ps --format 'table {{.ID}}\t{{.Name}}\t{{.Node}}\t{{.CurrentState}}' nginx
ID NAME NODE CURRENT STATE
d288f1uot8v2 nginx.1 node-01 Running 4 minutes ago
k5cfgpw4wkqv \_ nginx.1 node-04 Shutdown 4 minutes ago
xu4rxofr1zuz nginx.2 node-02 Running about a minute ago
yj7b9pxgkarm nginx.3 node-03 Running about a minute ago
swn3gsvz31vn nginx.4 node-04 Running about a minute ago
Now, if another service or discrete container wanted to consume the nginx service, how will it address the service? We could put in the work to determine each of the IP addresses for each of the service’s tasks on the nginx network, but we’ve seen how a simple service update creates a new task, which may be running on a different node with a different IP address. Trying to manage this manually would introduce such an overhead, as to render it practicably prohibitive.
Swarm has this covered, and allocates each service that gets created a virtual IP address through which it can be addressed. If we inspect the nginx service, we can see the virtual IP address:
$ docker service inspect --format '{{json .Endpoint.VirtualIPs}}' nginx | jq '.'
[
{
"NetworkID": "4pnw0biwjbns0bjg4ey6cepri",
"Addr": "192.168.35.2/24"
}
]
We can demonstrate the consumption of the nginx service via another deployed service. We’ll deploy a service that will enable us to retrieve the static content served by the nginx service from within the cluster. We’ll use the text-based browser, Lynx. We can’t run an interactive service on a Swarm Mode cluster, as services are intended to be long running applications that serve and consume using TCP/UDP sockets. We can work around this by deploying a service running a command that never exits. Once deployed, we need to find out where the service has been deployed in the cluster:
$ docker service create --detach=false --name lynx --network nginx nbrown/lynx tail -f /dev/null
mw10y3fu7h7uhlzzs6zgvizuo
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Waiting 1 seconds to verify that tasks are stable...
$ docker service ps --format 'table {{.ID}}\t{{.Name}}\t{{.Node}}\t{{.CurrentState}}' lynx
ID NAME NODE CURRENT STATE
a2yya9zev5vj lynx.1 node-03 Running 50 seconds ago
This tells us that the task is running on node-03, so we need to gain access to node-03 (or whichever node your lynx service is running on), so that we can execute lynx from within the task’s container. Next, we need to find the ID of the container for the task, and then start an interactive shell inside the container. We can correctly identify the container by applying a filter, based on a label which is attributed to the container, when the task is scheduled by Swarm’s scheduler. On the relevant node (node-03 in this case):
$ docker container ls --filter 'label=com.docker.swarm.service.name=lynx' -q
f729bcf88bd2
Using the ID of the container as an argument to the docker container exec command, we can use the lynx browser to access the nginx service, specifying the virtual IP address we retrieved earlier. Again, on the relevant node (node-03 in this case):
$ docker container exec f729bcf88bd2 lynx -dump 192.168.35.2
[O4WNJNd5l8wAAAAASUVORK5CYII=]
Hello!
Hostname: c6c9cdcc6611
IP Address: 192.168.35.6:80
Nginx Version: 1.12.1
The content of the static page is dumped to the terminal, which includes the hostname and IP address of the container that served the request. We’ve consumed the service via the virtual IP address (192.168.35.2), and been served by one of the service’s tasks (192.168.35.6).
Embedded DNS Server
Making use of the virtual IP of a service makes life significantly easier when consuming a scaled service, but we may not know this address in advance. Docker’s networking provides a great solution to this problem, through the use of an embedded DNS server. This is not a Swarm feature in itself, but is made available to Swarm, through the use of Docker’s inherent networking capabilities.
Each Docker engine runs an embedded DNS server, which can be queried by processes running in containers on a specific Docker host, provided that the containers are attached to user-defined networks (i.e. Note: not the default bridge network, called bridge). Container and Swarm service names can be resolved using the embedded DNS server, provided the query comes from a container attached to the same network as the container or service being looked up. In other words, name resolution is network scoped, and generally speaking, networks are isolated from each other. However,this does not preclude containers or services being attached to more than one network at a time.
Let’s make an explicit query of the embedded DNS server associated with the Docker daemon that is hosting the lynx task. We’ll execute a container that provides the dig utility, connected to the nginx network, to query the DNS server for the nginx service. If we hadn’t used the --attachable config option when we created the nginx network, this command would fail. On the relevant node (node-03 in this case):
$ docker container run --rm --network nginx nbrown/nwutils dig nginx
; <<>> DiG 9.10.4-P8 <<>> nginx
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 34060
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;nginx. IN A
;; ANSWER SECTION:
nginx. 600 IN A 192.168.35.2
;; Query time: 0 msec
;; SERVER: 127.0.0.11#53(127.0.0.11)
;; WHEN: Fri Jun 09 14:41:43 UTC 2017
;; MSG SIZE rcvd: 44
Notice the address of the server, 127.0.0.11, which is the address that Docker uses to trap lookup requests from within containers, before passing the request on to the daemon’s DNS server. The query returns the DNS A record for the nginx service.
In our scenario, we can use the service name, nginx, instead of the virtual IP address, to consume the service. The name will be resolved to the virtual IP address, and the service request will be routed to one of the task containers running in the cluster. Again, on the relevant node (node-03 in this case):
$ docker container exec f729bcf88bd2 lynx -dump nginx
[O4WNJNd5l8wAAAAASUVORK5CYII=]
Hello!
Hostname: 711b18465d8f
IP Address: 192.168.35.3:80
Nginx Version: 1.12.1
Let’s leave these services running for the time being.
Load Balancing
We’ve seen that Swarm routes requests from one service to another via a virtual IP address, resolvable by the service’s name. If we have multiple replicas for the service, how does it determine which replica to use in order to service a request? The final piece in the internal service discovery jigsaw is load balancing, which provides the answer to this question.
Swarm uses layer 4 (transport layer) load balancing, by making use of the IP Virtual Server (IPVS), an in-built feature of the Linux kernel. Initially, packets destined for the virtual IP address of a Swarm service, are ‘marked’ using a rule defined in the mangle table of the kernel’s netfilter packet filtering framework. IPVS then uses round robin load balancing to forward traffic to each of the containers that constitute the service’s tasks.
We can see the IPVS load balancing in action by making multiple queries to our nginx service, using the container associated with the task for the lynx service. Once more, on the relevant node (node-03 in this case):
$ for i in {1..8}; do docker container exec f729bcf88bd2 lynx -dump nginx | grep 'IP Address'; done
IP Address: 192.168.35.3:80
IP Address: 192.168.35.6:80
IP Address: 192.168.35.4:80
IP Address: 192.168.35.5:80
IP Address: 192.168.35.3:80
IP Address: 192.168.35.6:80
IP Address: 192.168.35.4:80
IP Address: 192.168.35.5:80
Notice how the requests are distributed by IPVS in round robin manner, to each of the nginx service’s tasks. Let’s remove the services:
$ docker service rm nginx lynx
nginx
lynx
We’ve looked at how Swarm services can be consumed from within a cluster, and we’ll now move on to see how services are consumed from outside the cluster.
External Service Consumption
Routing Mesh
A microservice running in a Swarm Mode cluster makes itself available to consumers external to the cluster through the publication of a port. Similar to the way that an individual container publishes its service using a runtime config option to the docker container run command, a service can be created specifying a port to publish, using the --publish config option. A shortened version, -p, can also be used.
The syntax for defining a port also has a short and long form. The following definitions are equivalent: -p 80:80 and --publish published=80,target=80,protocol=tcp,mode=ingress.
Whichever syntax form we use, when a service’s port is published, it’s published on every node in the cluster. Swarm then makes use of its ‘routing mesh’ in order to route external service requests to the tasks that constitute the service. The diagram below depicts the relationship between the various components:
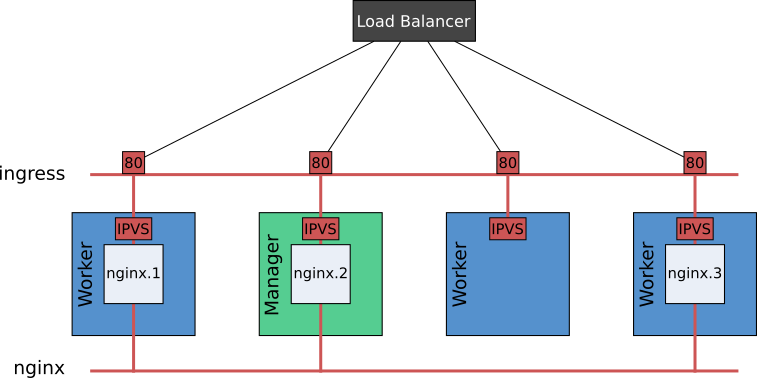
The routing mesh comprises an overlay network, called ingress, netfilter rules and IPVS. Traffic destined for a service can arrive at any cluster node, on the published port, and may originate from an external load balancer. Through a combination of the netfilter rules and IPVS load balancing via the service’s virtual IP, traffic is routed through the ingress network to a service task. This applies, even if the service request arrives on a node which is not running a service task.
Let’s re-create our nginx service, but this time we’ll publish a service port, and then consume the service from outside the cluster. We’ll publish the port, and mount the /etc/hostname file from each cluster node into the container of a corresponding scheduled task, which will appear in the served content. This will help us to see which task is serving each request. We’ll also limit the number of replicas to three, so that we can demonstrate that the cluster node without a task can still receive and service our request:
$ docker service create --detach=false --name nginx --network nginx \
--publish published=8080,target=80 \
--mount type=bind,src=/etc/hostname,dst=/etc/docker-hostname,ro \
--replicas 3 nbrown/nginxhello
eg3wfh346mpo4hyu5wtxutykz
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Waiting 1 seconds to verify that tasks are stable...
Let’s determine which of our cluster nodes is running service tasks:
$ docker service ps --format 'table {{.ID}}\t{{.Name}}\t{{.Node}}\t{{.CurrentState}}' nginx
ID NAME NODE CURRENT STATE
hdgwo2xzmscx nginx.1 node-03 Running 21 minutes ago
ufs80r1lrihe nginx.2 node-04 Running 21 minutes ago
de08mumqc9vh nginx.3 node-02 Running 21 minutes ago
In this case, it’s node-01 that does not have a task for the service.
If you’re following this tutorial using Amazon Web Services, then you’ll need to ensure that the security group you’re using for this exercise, allows ingress through port 8080 from the IP address you are using. If you’re not familiar with how to do this, the first article in this series showed how to do this. We can then point a web browser at the public IP address of any of our cluster nodes, to consume our nginx service. If you’ve created your cluster using Docker Machine, as detailed in the first article, we can easily retrieve the required public IP address for each node:
$ for i in {1..4}; do echo -n "node-0$i: "; docker-machine ip node-0$i; done
node-01: 35.176.22.179
node-02: 52.56.216.120
node-03: 35.176.40.60
node-04: 35.176.7.56
In turn, point your web browser at each node (e.g. 35.176.40.60:8080), and notice how IPVS load balances requests across the tasks for the service. You’ll also notice that the IP address of the serving container is no longer from the nginx network; it’s associated with the ingress network. Be sure to try addressing the node without an nginx service task, and you should have your request served from a task running on one of the other nodes.
Host Mode
Sometimes, there may be a need to bypass Swarm’s routing mesh, and this is possible by specifying mode=host as part of the --publish config option. In this scenario, a task’s port is mapped directly to the node’s port, and service requests directed to that node will be served by the associated task. This is particularly useful if a home-grown routing mesh is required, in place of the one provided by Swarm.
Load Balancing
A final thought should be given over to the load balancing capabilities used by Swarm Mode clusters. IPVS load balancing is based on layer 4 (transport layer) of the OSI model, and routes traffic based on IP addresses, ports and protocols. Whilst IPVS is very fast, as it’s implemented in the Linux kernel, it may not suit all scenarios. Layer 7 (application layer) load balancing is inherently more flexible, but is not provided as part of the Swarm implementation in the Docker Community Edition. Layer 7 load balancing can be implemented as a Swarm service, however, and numerous solutions abound: Docker’s HTTP Routing Mesh, and Traefik, to name just a couple.
Deploying Dockerized Applications with Semaphore
To continuously deploy your project to Docker Swarm, you can use Semaphore’s hosted continuous integration and deployment service. Semaphore’s native Docker platform comes with the complete Docker CLI preinstalled and has full layer caching for tagged Docker images. Take a look at our other Docker tutorials for more information on deploying with Semaphore.
Conclusion
This tutorial has provided an overview of how Docker Swarm makes services available for consumption, both internally and externally. Networking, in general, as well as service discovery techniques, make an enormous topic. We haven’t covered every fine-grained detail, but this tutorial has provided some insight into:
- Docker’s networking capabilities,
- Swarm’s service discovery techniques, using embedded DNS,
- Layer 4 load balancing in Swarm, using netfilter rules and IPVS, and
- Service publishing, and routing with the Swarm Mode routing mesh.
In the next tutorial, we’ll explore how services running in a Swarm cluster can be updated in flight.
If you have any questions and/or comments, feel free to leave them in the section below.
Read next:
