Introduction
Checking assumptions is important both when it comes to working with code and with finances. To build reliable software, we need to set, and then double-check our assumptions through tests. When dealing with finances, it is also important to verify assumptions and analyze transactions.
Most banks offer the possibility to export data about transactions in several formats. The most commonly supported one is called Open Financial Exchange (OFX). The specification for version 2.2 is 685 pages long, so reading it would require a significant time investment. Test-driven development (TDD) helps us avoid that cost, since all we need to know to handle OFX data is what our desired outcome should look like.
In this tutorial, we will use a TDD approach to build a tool for parsing OFX banking data in Java.
A TDD Approach at Parsing OFX Files
Instead of going through the specifications for the OFX format, we’re going to build a parser for it by using TDD. You can read the transactions which happened in your bank account online. Let’s suppose you go online and see the following transactions:
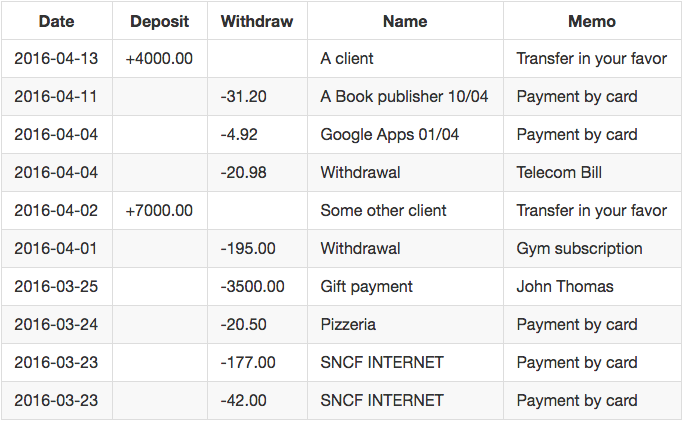
Then, you can download the corresponding OFX file.
You can find an OFX file describing these transactions in the GitHub repository here.
We know that we should find exactly the same transactions when parsing the file. We can now start by writing our first test.
package me.tomassetti.ofx;
import org.junit.Test;
import java.io.InputStream;
import static org.junit.Assert.*;
/**
* @author Federico Tomassetti (http://tomassetti.me)
*/
public class OfxParserTest {
@Test
public void testNumberOfTransactions() {
InputStream is = this.getClass().getResourceAsStream("/example.ofx");
assertEquals(10, new OfxParser().parse(is).size());
}
}
At this stage our parser looks like this:
package me.tomassetti.ofx;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.util.List;
/**
* @author Federico Tomassetti (http://tomassetti.me)
*/
public class OfxParser {
public List<Transaction> parse(File file) throws FileNotFoundException {
return parse(new FileInputStream(file));
}
public List<Transaction> parse(InputStream is) {
throw new UnsupportedOperationException(
"Perhaps you should implement me");
}
}
The tests will, of course, fail at this point. We will start by finding out how many transactions are described in the file.
Building an Event Driven Parser for SGML
When we opened the file and looked at it, we saw that it’s an SGML file instead of being a simple XML. That means that some tags are not explicitly closed — some of them can be implicitly closed, according to the rules of the specific format. The easiest way to parse these kinds of formats is to use an event-driven parser. Basically, we will read the file and do something when we get an open tag, a closed tag or some text.
To simplify, we will read the whole file in a string. Of course, you may want to adopt a different strategy if you are working with large OFX files.
public List<Transaction> parse(InputStream is) throws IOException {
String content = readAll(is);
Collector collector = new Collector();
processInput(content, 0, collector);
return collector.transactions;
}
private String readAll(InputStream is) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
String line = null;
StringBuilder stringBuilder = new StringBuilder();
String ls = System.getProperty("line.separator");
try{
while((line=reader.readLine())!=null){
stringBuilder.append(line);
stringBuilder.append(ls);
}
return stringBuilder.toString();
}finally{
reader.close();
}
}
We will use an instance of Collector to keep track of the information we get by parsing, eg. the tag that was last open. We will process the input starting from the 0 position, and then move on to recognizing the different elements:
private void processInput(String content, int position, Collector collector) {
// we reached the end, time to to stop
if (content.length() == position) {
collector.end();
// we have a closed tag in front of us
} else if (startsWith(content, position, "</")) {
int close = content.indexOf(">", position);
collector.closeTag(content.substring(position + 2, close));
processInput(content, close + 1, collector);
// we have an open tag in front of us
} else if (startsWith(content, position, "<")) {
int close = content.indexOf(">", position);
collector.openTag(content.substring(position + 1, close));
processInput(content, close + 1, collector);
// we have text, eat it until we get a tag or the end of the file
} else {
int next = content.indexOf("<",position);
// no more tag, read until the end of the file
if(next==-1){
next=content.length();
}
// get the text and pass it to the collector
String text=content.substring(position,next).trim();
if (!text.isEmpty()){
collector.text(text);
}
// keep parsing after the text
processInput(content, next, collector);
}
}
ProcessInput translates the initial input in a set of events for Collector. In Collector we will process those events and instantiate the transitions.
If we look a little further at the example file, we will and notice that basically each transition has a structure similar to the following:
<STMTTRN>
<TRNTYPE>OTHER
<DTPOSTED>20160413
<TRNAMT>+4000.00
<FITID>4347030000068
<NAME>A client
<MEMO>Transfer in your favor</STMTTRN>
Each time we run into the <STMTTRN> token, we will know that we are about to read a new transition. Let’s consider that in our Collector implementation:
private class Collector {
private List<Transaction> transactions = new LinkedList<>();
public void end() {
}
public void openTag(String tag) {
if (tag.equals("STMTTRN")) {
transactions.add(new Transaction());
}
}
public void closeTag(String tag) {
}
public void text(String text) {
}
}
With this change, our test is now passing!
Recognizing the Data in Each Transaction
The next step is to recognize the type of each transaction, i.e. whether we’ve received money or paid for something.
By looking at the table, we can see what data we should get. Let’s write a test to ensure that our parser returns the expected data.
@Test
public void testTransactionsTypes() throws IOException {
InputStream is = this.getClass().getResourceAsStream("/example.ofx");
assertEquals(Arrays.asList(
Transaction.Type.DEPOSIT,
Transaction.Type.WITHDRAWAL,
Transaction.Type.WITHDRAWAL,
Transaction.Type.WITHDRAWAL,
Transaction.Type.DEPOSIT,
Transaction.Type.WITHDRAWAL,
Transaction.Type.WITHDRAWAL,
Transaction.Type.WITHDRAWAL,
Transaction.Type.WITHDRAWAL,
Transaction.Type.WITHDRAWAL),
new OfxParser().parse(is).stream().map(t -> t.getType())
.collect(Collectors.toList()));
}
Our parser should read the text coming after the tag TRNAMT and look at the sign before the amount. If the sign is a plus, then the transaction represents a deposit, otherwise it is a withdrawal. To implement that logic, we have to remember which was the last open tag. This means that we had to track the tags which are opened or closed.
private class Collector {
private List<String> openTags = new LinkedList<>();
private List<Transaction> transactions = new LinkedList<>();
public void end() {
}
public void openTag(String tag) {
openTags.add(tag);
if (tag.equals("STMTTRN")) {
transactions.add(new Transaction());
}
}
public void closeTag(String tag) {
// when we close a tag we could implicitly close a bunch of
// tags in between.
// For example consider: <a><b><c><d></a>
// when I encounter "</a>", it tells me that all the tags
// inside "a" should be considered to be closed
while(!lastOpenTag().equals(tag)){
closeTag(lastOpenTag());
}
// remove the last one
openTags.remove(openTags.size() - 1);
}
public void text(String text) {
if (lastOpenTag().equals("TRNAMT")) {
if (text.startsWith("-")) {
lastTransaction().setType(Transaction.Type.WITHDRAWAL);
} else if (text.startsWith("+")){
lastTransaction().setType(Transaction.Type.DEPOSIT);
} else {
throw new UnsupportedOperationException();
}
}
}
private String lastOpenTag() {
if (openTags.size() == 0) {
return "";
} else {
return openTags.get(openTags.size() - 1);
}
}
private Transaction lastTransaction() {
if (transactions.size() == 0) {
return null;
} else {
return transactions.get(transactions.size() - 1);
}
}
}
The type is represented by an enum defined inside Transaction:
public class Transaction {
enum Type {
WITHDRAWAL,
DEPOSIT
}
...
}
Parsing the Remaining Fields
By using the same approach, we can also find the amount, the date, the name, and the description. We should also save the FITID code. It is a transaction identifier, and it can be used to distinguish the transactions. This will be particularly important if we decide to import new OFX files regularly in the future, since we’ll need to distinguish new transactions from the ones we had already imported.
Let’s test whether the amounts are correct:
@Test
public void testTransactionAmounts() throws IOException {
InputStream is = this.getClass().getResourceAsStream("/example.ofx");
assertEquals(Arrays.asList(
new BigDecimal("4000.00"),
new BigDecimal("31.20"),
new BigDecimal("4.92"),
new BigDecimal("20.98"),
new BigDecimal("7000.00"),
new BigDecimal("195.00"),
new BigDecimal("3500.00"),
new BigDecimal("20.50"),
new BigDecimal("177.00"),
new BigDecimal("42.00")),
new OfxParser().parse(is).stream().map(t -> t.getAmount())
.collect(Collectors.toList()));
}
Next, we need to test if the dates are correct:
@Test
public void testTransactionDates() throws IOException {
InputStream is = this.getClass().getResourceAsStream("/example.ofx");
assertEquals(Arrays.asList(
LocalDate.of(2016, 4, 13),
LocalDate.of(2016, 4, 11),
LocalDate.of(2016, 4, 4),
LocalDate.of(2016, 4, 4),
LocalDate.of(2016, 4, 2),
LocalDate.of(2016, 4, 1),
LocalDate.of(2016, 3, 25),
LocalDate.of(2016, 3, 24),
LocalDate.of(2016, 3, 23),
LocalDate.of(2016, 3, 23)),
new OfxParser().parse(is).stream().map(t -> t.getDate())
.collect(Collectors.toList()));
}
Now, let’s test if the name and the description of each transaction are correct:
@Test
public void testTransactionNames() throws IOException {
InputStream is = this.getClass().getResourceAsStream("/example.ofx");
assertEquals(Arrays.asList(
"A client",
"A Book publisher 10/04",
"GOOGLE Apps 01/04",
"Withdrawal",
"Some other client",
"Withdrawal",
"Gift money",
"Pizzeria",
"SNCF INTERNET",
"SNCF INTERNET"),
new OfxParser().parse(is).stream().map(t -> t.getName())
.collect(Collectors.toList()));
}
@Test
public void testTransactionDescriptions() throws IOException {
InputStream is = this.getClass().getResourceAsStream("/example.ofx");
assertEquals(Arrays.asList(
"Transfer in your favor",
"Payment by card",
"Payment by card",
"Telecom Bill",
"Transfer in your favor",
"Gym subscription",
"John Thomas",
"Payment by card",
"Payment by card",
"Payment by card"),
new OfxParser().parse(is).stream().map(t -> t.getMemo())
.collect(Collectors.toList()));
}
Finally, let’s check for the FITID code. In most banks, those IDs are usually long numbers, and they can also be alphanumeric sequences. This is why we’ll parse them as strings.
The FITID identifier can, but doesn’t have to be visible in the interface of your home-banking web application.
@Test
public void testTransactionFitids() throws IOException {
InputStream is = this.getClass().getResourceAsStream("/example.ofx");
assertEquals(Arrays.asList(
"9947030000068",
"9944290089129",
"9936170085272",
"9936230090261",
"9947030000068",
"9934320105735",
"9904660684216",
"9926100027461",
"9924570028048",
"9924570028049"),
new OfxParser().parse(is).stream().map(t -> t.getFitid())
.collect(Collectors.toList()));
}
To make these tests pass we just need to update Collector.text:
public void text(String text) {
if (lastOpenTag().equals("TRNAMT")) {
if (text.startsWith("-")) {
lastTransaction().setType(Transaction.Type.WITHDRAW);
lastTransaction().setAmount(new BigDecimal(text.substring(1)));
} else if (text.startsWith("+")){
lastTransaction().setType(Transaction.Type.DEPOSIT);
lastTransaction().setAmount(new BigDecimal(text.substring(1)));
} else {
throw new UnsupportedOperationException();
}
} else if (lastOpenTag().equals("NAME")) {
lastTransaction().setName(text);
} else if (lastOpenTag().equals("MEMO")) {
lastTransaction().setMemo(text);
} else if (lastOpenTag().equals("DTPOSTED")) {
lastTransaction().setDate(LocalDate.parse(text,
DateTimeFormatter.BASIC_ISO_DATE));
} else if (lastOpenTag().equals("FITID")) {
lastTransaction().setFitid(text);
}
}
Our tests have passed, and we have now sucessfully written a parser.
Conclusion
In this tutorial, we managed to write a parser for OFX files without having to read almost 700 pages of documentation. We knew what data we needed to extract, because we had access to that data on the bank’s website. This was a perfect scenario for applying TDD. We started from the expected result and were lead by our tests to reach the final result, while also learning a useful technique for analyzing complex formats using an event-driven parser.
