What is a software product? The business code itself, right? Actually, that’s only a part of it. A software product consists of different elements:
- Business code
- Documentation
- CI/CD pipeline
- Communication rules
- Automation tests
Pure code is not enough anymore. Only if these parts are integrated into a solid system, can it be called a software product.
Tests are crucial in software development. Moreover, there is no separation between “application” and “tests” anymore. Not because the absence of the latter will result in an unmaintainable and non-functional product (though it’s definitely the case), rather due to the fact that tests guide architecture design and assure code testability.
Unit tests are only a fraction of the huge testing philosophy. There are dozens of different kinds of tests. Tests are the foundation of development these days. You can read my article about integration tests on Semaphore’s blog. But now it is time to deep dive into unit testing.
The code examples for this article are in Java, but the given rules are common for any programming language.
Table of contents
- What is unit testing
- Test-driven development
- Unit tests requirements
- The unit testing mindset
- Best practices
- Unit testing tools
What is unit testing
Every developer has experience in writing unit tests. We all know their purpose and what they look like. It can be hard, however, to give a strict definition for a unit test. The problem lies within the understanding of what a unit is. Let’s try to clarify that first.
A unit is an isolated piece of functionality.
Sounds reasonable. According to this definition, every unit test in the suite should cover a single unit.
Take a look at the schema below. The application consists of many modules, and each module has a number of units.
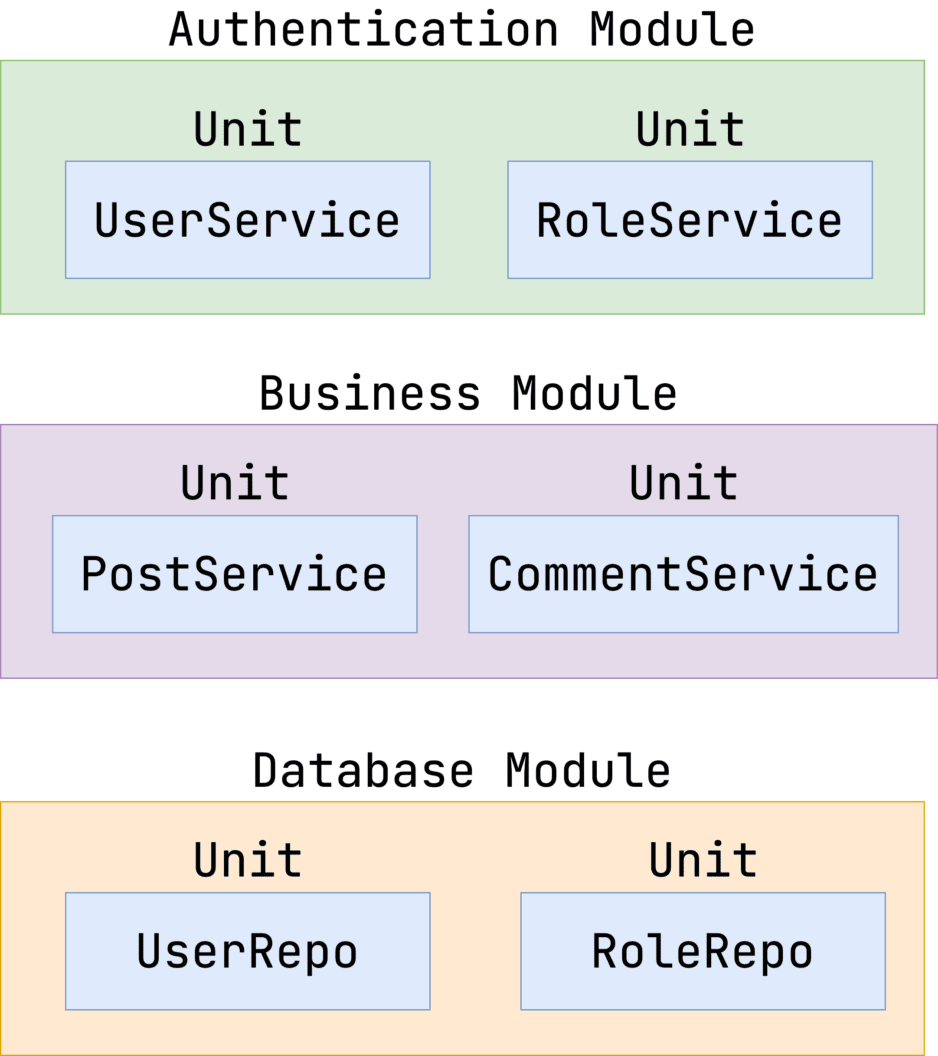
In this case, there are 6 units:
- UserService
- RoleService
- PostService
- CommentService
- UserRepo
- RoleRepo
According to the given schema, the unit can be defined in this way:
A unit is a class that can be tested in isolation from the whole system.
So, we can write tests for each specific unit, right? Well, this statement is both correct and incorrect, because units do not exist independently of one another. They have to interact with each other, or the application won’t work.
Then how can we write unit tests for something that cannot practically be isolated? We’ll get to this soon, but let’s make another point clear first.
Test Driven Development
Test Driven Development is the technical practice of writing tests before the business code. When I heard about it for the first time, I was confused. How can one write tests when there is nothing to test? Let’s see how it works.
TDD declares three steps:
- Write a test for the new functionality. It’s going to fail because you haven’t written the required business code yet.
- Add the minimum code to implement the feature.
- If the test passes, refactor the result and go back to the first step.
This lifecycle is called Red-Green-Refactor.
Some authors have proposed enhancements for the formula. You can find examples with 4 or even 5 steps, but the idea remains the same.
The problem of unit definition
Suppose we’re creating a blog where authors can write posts and users can leave comments. We want to build functionality for adding new comments. The required behaviour consists of the following points:
- User provides post id and comment content.
- If the post is absent, an exception is thrown.
- If comment content is longer than 300 characters, an exception is thrown.
- If all validations pass, the comment should be saved successfully.
Here is the possible Java implementation:
public class CommentService {
private final PostRepository postRepository;
private final CommentRepository commentRepository;
// constructor is omitted for brevity
public void addComment(long postId, String content) {
if (!postRepository.existsByid(postId)) {
throw new CommentAddingException("No post with id = " + postId);
}
if (content.length() > 300) {
throw new CommentAddingException("Too long comment: " + content.length());
}
commentRepository.save(new Comment(postId, content));
}
}It’s not hard to test the content’s length. The problem is that CommentService relies on dependencies passed through the constructor. How should we test the class in this case? I cannot give you a single answer, because there are two schools of TDD. The Detroit School (classicist) and the London School (mockist). Each one declares the unit in a different way.
The Detroit School of TDD
If a classicist wanted to test the addComment method we described earlier, the service instantiation might look like this:
class CommentServiceTest {
@Test
void testWithStubs() {
CommentService service = new CommentService(
new StubPostRepository(),
new StubCommentRepository()
);
}
}In this case, StubPostRepository and StubCommentRepository are implementations of the corresponding interfaces used for test cases. By the way, the Detroit School does not restrict applying to real business classes.
To summarize the idea, take a look at the schema below. The Detroit School declares the unit not as a separate class but a combination of ones. Different units can overlap.
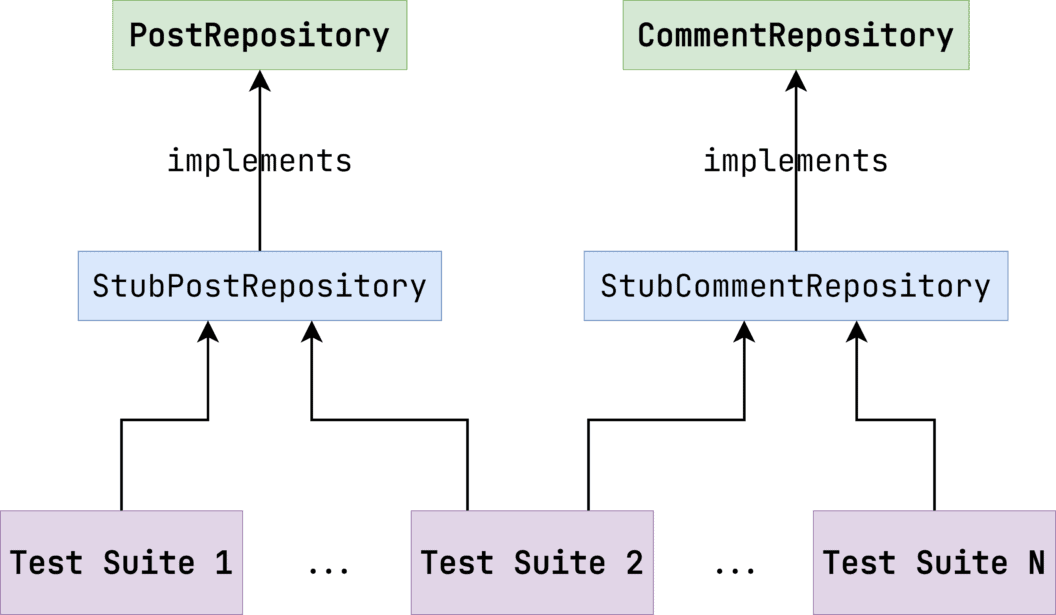
There are many test suites that depend on the same implementations — StubPostRepository и StubCommentRepository.
So, the Detroit school followers would declare the unit in this way:
A unit is a class that can be tested in isolation from the whole system. Any external dependencies should be either replaced with stubs or real business objects.
The London School of TDD
A mockist, on the other hand, would test addComment differently.
class CommentServiceTest {
@Test
void testWithStubs() {
PostRepository postRepository = mock(PostRepository.class);
CommentRepository commentRepository = mock(CommentRepository.class);
CommentService service = new CommentService(
postRepository,
commentRepository
);
}
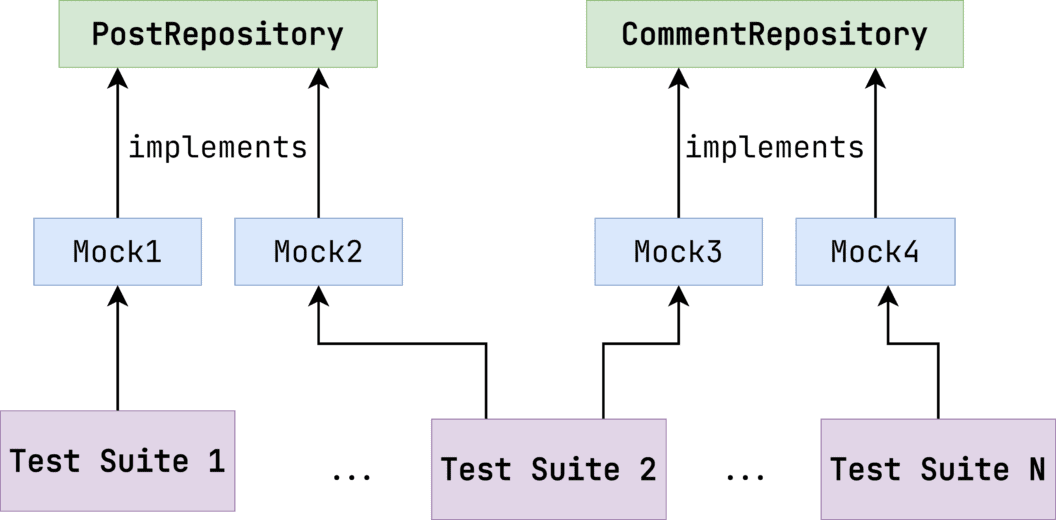
}The London School defines a unit as a strongly isolated piece of code. Each mock is an implementation of the class’s dependency. Mocks should be unique for every test case.
A unit is a class that can be tested in isolation from the whole system. Any external dependencies should be mocked. No stubs are allowed to be reused. Applying real business objects is prohibited.
Take a look at the schema below to clarify the point.
Summary of unit definition
The Detroit School and the London school have arguments behind approaches they propose. These arguments are, however, beyond the scope of this article. For our purposes, I will apply both mocks and stubs.
So, it’s time to settle on our final unit definition. Take a look at the statement below.
A unit is a class that can be tested in isolation from the whole system. All external dependencies should be either mocked or replaced with stubs. No business objects should be involved in the process of testing.
We’re not involving external business objects in the single unit. Though the Detroit School of TDD allows for it, I consider this approach unstable. This is because business objects’ behaviour can evolve as the system grows. As they change, they might affect other parts of the code. There is, however, one exception from the rule: Value objects. These are data structures that encapsulate isolated pieces. For example, the Money value object consists of the amount and the currency. The FullName object can have the first name, the last name, and the patronymic. Those classes are plain data holders with no specific behaviour, so it’s OK to apply them directly in tests.
Now that we have a working definition of a unit, let’s move on to establishing how a unit test should be constructed. Each unit test has to follow a set of defined requirements. Take a look at the list below:
- Classes should not break the DI (dependency inversion) principle.
- Unit tests should not affect each other.
- Unit tests should be deterministic.
- Unit tests should not depend on any external state.
- Unit tests should run fast.
- All Tests Should Run in the CI Environment
Let’s clarify each point step by step.
Unit test requirements
Classes should not break the DI Principle
This one is the most obvious, but it’s worth mentioning because breaking this rule renders unit testing meaningless.
Take a look at the code snippet below:
public class CommentService {
private final PostRepository postRepository = new PostRepositoryImpl();
private final CommentRepository commentRepository = new CommentRepositoryImpl();
...
}Even though CommentService declares external dependencies, they are bonded to PostRepositoryImpl and CommentRepositoryImpl. This makes it impossible to pass stubs/doubles/mocks to verify the class’s behaviour in isolation. This is why you should pass all dependencies through the constructor.
Unit tests should not affect each other
The philosophy of unit testing can be summed up in the following statement:
A user can run all unit tests either sequentially or in parallel. This should not affect the result of their execution. Why is that important? Suppose that you ran tests A and B and everything worked just fine. But the CI node ran test B and then test A. If the result of test B influences test A, it can lead to false negative behaviour. Such cases are tough to track and fix.
Suppose that we have the StubCommentRepository for testing purposes.
public class StubCommentRepository implements CommentRepository {
private final List<Comment> comments = new ArrayList<>();
@Override
public void save(Comment comment) {
comments.add(comment);
}
public List<Comment> getSaved() {
return comments;
}
public void deleteSaved() {
comments.clear();
}
}If we passed the same instance of StubCommentRepository, would it guarantee that unit tests are not affecting each other? The answer is no. You see, StubCommentRepository is not thread-safe. It is probable that parallel tests won’t give the same results as sequential ones.
There are two ways to solve this issue:
- Make sure that each stub is thread-safe.
- Create a new stub/mock for every test case.
Unit tests should be deterministic
A unit test should depend only on input parameters but not on outer states (system time, number of CPUs, default encoding, etc.). Because there is no guarantee that every developer in the team has the same hardware setup. Suppose that you have 8 CPUs on your machine and a test makes an assumption regarding this. Your colleague with 16 CPUs will probably be irritated that the test is failing on their machine every time.
Let’s take a look at an example. Imagine that we want to test a util method that tells whether a provided date-time is morning or not. This is how our test might look:
class DateUtilTest {
@Test
void shouldBeMorning() {
OffsetDateTime now = OffsetDateTime.now();
assertTrue(DateUtil.isMorning(now));
}
}This test is not deterministic by design. It will succeed only if the current system time is classified as morning.
The best practice here is to avoid declaring test data by calling non-pure functions. These include:
- Current date time.
- System timezone.
- Hardware parameters.
- Random numbers.
It should be mentioned that property-based testing provides similar data generation, although it works a bit differently. We’ll discuss it at the end of the article.
Unit tests should not depend on any external state
This means that every test run guarantees the same result within any environment. Trivial? Perhaps it is. Though the reality might be trickier. Let’s see what happens if your test relies on an external HTTP service always being available and returns the expected result each time.
Suppose we’re creating a service that provides a weather status. It accepts a URL where HTTP API calls are transmitted. Take a look at the code snippet below. It’s a simple test that checks that current weather status is always present.
class WeatherTest {
@Test
void shouldGetCurrentWeatherStatus() {
String apiRoot = "https://api.openweathermap.org";
Weather weather = new Weather(apiRoot);
WeatherStatus weatherStatus = weather.getCurrentStatus();
assertNotNull(weatherStatus);
}
}The problem is that the external API might be unstable. We cannot guarantee that the outer service will always respond. Even if we did, there is still the possibility that the CI server running the build forbids HTTP requests. For example, there could be some firewall restrictions.
It is important that a unit test is a solid piece of code that doesn’t require any external services to run successfully.
All tests should run in the CI environment
Tests act preventatively. They should reject any code that does not pass the stated specifications. This means that code that does not pass its unit test should not be merged to the main branch.
Why is this important? Suppose that we merge branches with broken code. When release time comes we need to compile the main branch, build the artefacts, and proceed with the deployment pipeline, right? But remember that code is potentially broken. The production might go down. We could run tests manually before the release, but what if they fail? We would have to fix those bugs on the fly. This could result in a delayed release and customer dissatisfaction. Being sure that the main branch has been thoroughly tested means that we can deploy without fear.
The best way to achieve this is to integrate tests run in the CI environment. Semaphore does it brilliantly. The tool can also show each failed test run, so you don’t have to crawl into CI build logs to track down problems.
It should be stated here that all kinds of tests should be run in the CI environment, i.e. integration and E2E tests also.
Summary of unit test requirements
As you can see, unit tests are not as straightforward as they seem to be. This is because unit testing is not about assertions and error messages. Unit tests validate behaviour, not the fact that the mocks have been invoked with particular parameters.
How much effort should you put into tests? There is no universal answer, but when you write tests you should remember these points:
- A test is excellent code documentation. If you’re unaware of the system’s behaviour, the test can help you to understand the class’s purpose and API.
- There is a high chance that you’ll come back to the test later. If it’s poorly written, you’ll have to spend too much time figuring out what it actually does.
There is an even simpler formula for the stated points. Every time you’re writing a test, keep this quote in mind:
Tests are parts of code that do not have tests.
The unit testing mindset
What is the philosophy behind unit testing? I’ve mentioned the word behaviour several times throughout the article. In a nutshell, that is the answer. A unit test checks behaviour, but not direct function calls. This may sound a bit complicated, so let’s deconstruct the statement.
Refactoring stability
Imagine that you have done some minor code refactoring, and a bunch of your tests suddenly start failing. This is a maddening scenario. If there are no business logic changes, we don’t want to break our tests. Let’s clarify the point with a concrete example.
Let’s assume that a user can delete all the posts they have archived. Here is the possible Java implementation.
public class PostDeleteService {
private final UserService userService;
private final PostRepository postRepository;
public void deleteAllArchivedPosts() {
User currentUser = userService.getCurrentUser();
List<Post> posts = postRepository.findByPredicate(
PostPredicate.create()
.archived(true).and()
.createdBy(oneOf(currentUser))
);
postRepository.deleteAll(posts);
}
}PostRepository is an interface that represents external storage. For example, it could be PostgreSQL or MySQL. PostPredicate is a custom predicate builder.
How can we test the method’s correctness? We could provide mocks for UserService and PostRepository and check the input parameters’ equity. Take a look at the example below:
public class PostDeleteServiceTest {
// initialization
@Test
void shouldDeletePostsSuccessfully() {
User mockUser = mock(User.class);
List<Post> mockPosts = mock(List.class);
when(userService.getCurrentUser()).thenReturn(mockUser);
when(postRepository.findByPredicate(
eq(PostPredicate.create()
.archived(true).and()
.createdBy(oneOf(mockUser)))
)).thenReturn(mockPosts);
postDeleteService.deleteAllArchivedPosts();
verify(postRepository, times(1)).deleteAll(mockPosts);
}
}The when, thenReturn, and eq methods are part of the Mockito Java library. We’ll talk more about various testing libraries at the end of the article.
Do we test behaviour here? Actually, we don’t. There is no testing, rather we are verifying the order of methods called. The problem is that the unit test does not tolerate refactoring of the code it is testing.
Imagine that we decided to replace oneOf(user) with is(user) predicate usage. An example could look like this:
public class PostDeleteService {
private final UserService userService;
private final PostRepository postRepository;
public void deleteAllArchivedPosts() {
User currentUser = userService.getCurrentUser();
List<Post> posts = postRepository.findByPredicate(
PostPredicate.create()
.archived(true).and()
// replaced 'oneOf' with 'is'
.createdBy(is(currentUser))
);
postRepository.deleteAll(posts);
}
}This should not make any difference, right? The refactoring hasn’t changed the business logic at all. But the test is going to fail now, because of this mocking setup.
public class PostDeleteServiceTest {
// initialization
@Test
void shouldDeletePostsSuccessfully() {
// setup
when(postRepository.findByPredicate(
eq(PostPredicate.create()
.archived(true).and()
// 'oneOf' but not 'is'
.createdBy(oneOf(mockUser)))
)).thenReturn(mockPosts);
// action
}
}Every time we do even a slight refactoring, the test fails. That makes maintenance a big burden. Imagine what might go wrong if we made major changes. For example, if we added the postRepository.deleteAllByPredicate method, it would break the whole test setup.
This is happening because the previous examples are focusing on the wrong thing. We want to test behaviour. Let’s see how we can make a new test that will do that. First, we need to declare a custom PostRepository implementation for test purposes. It’s OK to store data in RAM, what’s important is PostPredicate recognition. Therefore, the calling method relies on the fact that predicates are treated correctly.
Here’s the refactored version of the test:
public class PostDeleteServiceTest {
// initialization
@Test
void shouldDeletePostsSuccessfully() {
User currentUser = aUser().name("n1");
User anotherUser = aUser().name("n2");
when(userService.getCurrentUser()).thenReturn(currentUser);
testPostRepository.store(
aPost().withUser(currentUser).archived(true),
aPost().withUser(currentUser).archived(true),
aPost().withUser(anotherUser).archived(true)
);
postDeleteService.deleteAllArchivedPosts();
assertEquals(1, testPostRepository.count());
}
}Here is what changed:
- There is no PostRepository mocking. We introduced a custom implementation: TestPostRepository. It encapsulates the stored posts and guarantees the correct PostPredicate processing.
- Instead of declaring PostRepository returning a list of posts, we put the real objects within TestPostRepository.
- We don’t care about which functions have been called. We want to validate the delete operation itself. We know that the storage consists of 2 archived posts of the current user and 1 post of another user. The successful operation process should leave 1 post. That’s why we put assertEquals on posts count.
Now the test is isolated from the specific method invocations checks. We care only about the correctness of the TestPostRepository implementation itself. It doesn’t matter exactly how PostDeleteService implements the business case. It’s not about “how”, it’s about “what” a unit does. Furthermore, this refactoring won’t break the test.
You might also notice that UserService is still a regular mock. That’s fine because the probability of the getCurrentUser() method substitution is not significant. Besides, the method has no parameters. This means that we don’t have to deal with a possible input parameter mismatch. Mocks aren’t good or bad, just keep in mind that different tasks require different tools.
A few words about MVC frameworks
The vast majority of applications and services are developed using an MVC framework. Spring Boot is the most popular one for Java. Even though many authors claim that your design architecture should not depend on a framework (e.g. Robert Martin), the reality is not so simple. Nowadays, many projects are “framework-oriented”. It’s hard or even impossible to replace one framework with another. This, of course, influences test design as well.
I do not fully agree with the notion that your code should be “totally isolated from frameworks”. In my opinion, depending on a framework’s features to reduce boilerplate and focus on business logic is not a big deal. But that is an extensive debate that is outside of the scope of this article.
What is important to remember is that your business code should be abstracted from the framework’s architecture. This means that any class should be unaware of the environment in which the developer has installed it. Otherwise, your tests become too coupled in unnecessary details. If you decide to switch from one framework to another at some point, it would be a Herculean task. The required time and effort to do it would be unacceptable for any company.
Let’s move on to an example. Assume we have an XML generator. Each element has a unique integer ID and we have a service that generates those IDs. But what if the number of generated XMLs is huge? If every element in every XML document had a unique integer id, it could lead to integer overflow. Let’s imagine that we are using Spring in our project. To overcome this issue we decided to declare IDService with the prototype scope. So, XMLService should receive a new instance of IDService every time a generator is triggered. Take a look at the example below:
@Service
public class XMLGenerator {
@Autowired
private IDService idService;
public XML generateXML(String rawData) {
// split raw data and traverse each element
for (Element element : splittedElements) {
element.setId(idService.generateId());
}
// processing
return xml;
}
}The problem here is that XMLGenerator is a singleton (the default Spring bean scope). Therefore, it instantiated 1s and IDService is not refreshed.
We could fix that by injecting ApplicationContext and requesting the bean directly.
@Service
public class XMLGenerator {
@Autowired
private ApplicationContext context;
public XML generateXML(String rawData) {
// Creates new IDService instance
IDService idService = context.getBean(IDService.class);
// split raw data and traverse each element
for (Element element : splittedElements) {
element.setId(idService.generateId());
}
// processing
return xml;
}
}But here is the thing: now the class is bound to the Spring ecosystem. XMLGenerator understands that there is a DI-container, and it’s possible to retrieve a class instance from it. In this case, unit testing becomes harder. Because you cannot test XMLGenerator outside of the Spring context.
The better approach is to declare an IDServiceFactory, as shown below:
@Service
public class XMLGenerator {
@Autowired
private IDServiceFactory factory;
public XML generateXML(String rawData) {
IDService idService = factory.getInstance();
// split raw data and traverse each element
for (Element element : splittedElements) {
element.setId(idService.generateId());
}
// processing
return xml;
}
}That’s better. IDServiceFactory encapsulates the logic of retrieving the IDService instance. IDServiceFactory is injected into the class field directly. Spring can do it. But what if there is no Spring? Could you do this with the plain unit test? Well, technically it’s possible. The Java Reflection API allows you to modify private fields’ values. I’m not going to discuss this at length, but I’ll just say: never use Reflection API in your tests! It’s an absolute anti-pattern.
There is one exception. If your business code does work with Reflection API, then it’s OK to apply reflection in tests as well.
Let’s get back to DI. There are 3 approaches to implement dependency injection:
- Field injection
- Setter injection
- Constructor injection
The second and the third approach do not share the problems of the first one. We can apply either of them. Both will work. Take a look at the code example below:
@Service
public class XMLGenerator {
private final IDServiceFactory factory;
public XMLGenerator(IDServiceFactory factory) {
this.factory = factory;
}
public XML generateXML(String rawData) {
IDService idService = factory.getInstance();
// split raw data and traverse each element
for (Element element : splittedElements) {
element.setId(idService.generateId());
}
// processing
return xml;
}
}Now the XMLGenerator is completely isolated from the framework details.
Unit testing mindset summary
- Test what the code does but not how it does it.
- Code refactoring should not break tests.
- Isolate the code from the frameworks’ details.
Best practices
Now we can discuss some best practices to help you increase the quality of your unit tests.
Naming
Most IDEs generate a test suite name by adding the Test suffix to the class name. PostServiceTest, WeatherTest, CommentControllerTest, etc. Sometimes this might be sufficient, but I think that there are some issues with this approach:
- The type of test is not self-describing (unit, integration, e2e).
- You cannot tell which methods are tested.
In my opinion, the better way is to enhance the simple Test suffix:
- Specify the particular type of test. This will help us to clarify the test borders. For example, you might have multiple test suites for the same class (PostServiceUnitTest , PostServiceIntegrationTest , PostServiceE2ETest).
- Add the name of the method that is being tested. For example, WeatherUnitTest_getCurrentStatus. Or CommentControllerE2ETest_createComment.
The second point is debatable. Some developers claim that every class should be as solid as possible, and distinguishing tests by the method name can lead to treating classes as dummy data structures.
These arguments do make sense, but I think that putting the method name also provides advantages:
- Not all classes are solid. Even if you’re the biggest fan of Domain-Driven Design, it is impossible to build every class this way.
- Some methods are more complicated than others. You might have 10 test methods just to verify the behaviour of a single class method. If you put all tests inside one test suite, you will make it huge and difficult to maintain.
You could also apply different naming strategies according to specific context. There is no single right way to go about this, but remember that naming is an important maintainability feature. It’s a good practice to choose one strategy to share within your team.
Assertions
I’ve heard it stated that each test should have a single assertion. If you have more, then it’s better to split it into multiple suites.
I’m not generally fond of edge opinions. This one does make sense, but I would rephrase it a bit.
Each test case should assert a single business case.
It’s OK to have multiple assertions, but make sure that they clarify a solid operation. For example, look at the code example below:
public class PersonServiceTest {
// initialization
@Test
void shouldCreatePersonSuccessfully() {
Person person = personService.createNew("firstName", "lastName");
assertEquals("firstName", person.getFirstName());
assertEquals("lastName", person.getLastName());
}
}Even though there are two assertions, they are bound to the same business context (i.e. creating a new Person).
Now check out this code snippet:
class WeatherTest {
// initialization
@Test
void shouldGetCurrentWeatherStatus() {
LocalDate date = LocalDate.of(2012, 5, 25);
WeatherStatus testWeatherStatus = generateStatus();
tuneWeather(date, testWeatherStatus);
WeatherStatus result = weather.getStatusForDate(date);
assertEquals(
testWeatherStatus,
result,
"Unexpected weather status for date " + date
);
assertEquals(
result,
weather.getStatusForDate(date),
"Weather service is not idempotent for date " + date
);
}
}These two assertions do not build a solid piece of code. We’re testing the result of getStatusForDate and the fact that the function call is idempotent. It’s better to split this suite into two tests because the two things being tested aren’t directly linked.
Error messages
Tests can fail. That’s the whole idea of testing. If your suite is red, what should you do? Fix the code? But how should you do it? What’s the source of the problem? If an assertion fails, we get an error log that tells us what went wrong, right? Indeed, it’s true. Sadly, those messages aren’t always useful. How you write your tests can determine what kind of feedback you get in the error log.
Take a look at the code example below:
class WeatherTest {
// initialization
@ParameterizedTest
@MethodSource("weatherDates")
void shouldGetCurrentWeatherStatus(LocalDate date) {
WeatherStatus testWeatherStatus = generateStatus();
tuneWeather(date, testWeatherStatus);
WeatherStatus result = weather.getStatusForDate(date);
assertEquals(testWeatherStatus, result);
}
}Suppose that weatherDates provide 20 different date values. As a matter of fact, there are 20 tests. One test failed and here is what you got as the error message.
expected: <SHINY> but was: <CLOUDY>
Expected :SHINY
Actual :CLOUDYNot so descriptive, is it? 19/20 tests have succeeded. There must be some problem with a date, but the error message didn’t give much detail. Can we rewrite the test so that we get more feedback on failure? Of course! Take a look at the code snippet below:
class WeatherTest {
// initialization
@ParameterizedTest
@MethodSource("weatherDates")
void shouldGetCurrentWeatherStatus(LocalDate date) {
WeatherStatus testWeatherStatus = generateStatus();
tuneWeather(date, testWeatherStatus);
WeatherStatus result = weather.getStatusForDate(date);
assertEquals(
testWeatherStatus,
result,
"Unexpected weather status for date " + date
);
}
}Now the error message is much clearer.
Unexpected weather status for date 2022-03-12 ==> expected: <SHINY> but was: <CLOUDY>
Expected :SHINY
Actual :CLOUDYIt’s obvious that something is wrong with the date: 2022-03-12. This error log gives us a clue as to where we should start our investigation.
Also, pay attention to the toString implementation. When you pass an object to assertEquals, the library transforms it into a string using this method.
Test data initialization
When we test anything, we probably need some data to test against it (e.g. rows in the database, objects, variables, etc.). There are 3 known ways to initialise data in a test:
- Direct Declaration.
- Object Mother Pattern.
- Test Data Builder Pattern .
Direct Declaration
Suppose that we have the Post class. Take a look at the code snippet below:
public class Post {
private Long id;
private String name;
private User userWhoCreated;
private List<Comment> comments;
// constructor, getters, setters
}We can create new instances with constructors:
public class PostTest {
@Test
void someTest() {
Post post = new Post(
1,
"Java for beginners",
new User("Jack", "Brown"),
List.of(new Comment(1, "Some comment"))
);
// action...
}
}There are, however, some problems with this approach:
- Parameter names are not descriptive. You have to check the constructor’s declaration to tell the meaning of each provided value.
- Class attributes are not static. What if another field were added? You would have to fix every constructor invocation in every test.
What about setters? Let’s see how that would look:
public class PostTest {
@Test
void someTest() {
Post post = new Post();
post.setId(1);
post.setName("Java for beginners");
User user = new User();
user.setFirstName("Jack");
user.setLastName("Brown");
post.setUser(user);
Comment comment = new Comment();
comment.setId(1);
comment.setTitle("Some comment");
post.setComments(List.of(comment));
// action...
}
}Now the parameter names are transparent, but other issues have appeared.
- The declaration is too verbose. At first glance, it’s hard to tell what’s going on.
- Some parameters might be obligatory. If we added another field to the Post class, it could lead to runtime exceptions due to the object’s inconsistency.
We need a different approach to solve these problems.
Object Mother Pattern
In reality, it’s just a simple static factory that hides the instantiation complexity behind a nice facade. Take a look at the code example below:
public class PostFactory {
public static Post createSimplePost() {
// simple post logic
}
public static Post createPostWithUser(User user) {
// simple post logic
}
}This works for simple cases. But the Post class has many invariants (e.g. post with comment, post with comment and user, post with user, post with user and multiple comments, etc.). If we tried to declare a separate method for every possible situation, it would quickly turn into a mess. Enter Test Data Builder.
Test Data Builder Pattern
The name defines its purpose. It’s a builder created specifically to test data declarations. Let’s see what it looks like in the form of a test:
public class PostTest {
@Test
void someTest() {
Post post = aPost()
.id(1)
.name("Java for beginners")
.user(aUser().firstName("Jack").lastName("Brown"))
.comments(List.of(
aComment().id(1).title("Some comment")
))
.build();
// action...
}
}aPost(), aUser(), and aComment() are static methods that create builders for the corresponding classes. They encapsulate the default values for all attributes. Calling id, name, and other methods overrides the values. You can also enhance the default builder-pattern approach and make them immutable, making every attribute change return a new builder instance. It’s also helpful to declare templates to reduce boilerplate.
public class PostTest {
private PostBuilder defaultPost =
aPost().name("post1").comments(List.of(aComment()));
@Test
void someTest() {
Post postWithNoComments = defaultPost.comments(emptyList()).build();
Post postWithDifferentName = defaultPost.name("another name").build();
// action...
}
}If you want to really dive into this, I wrote a whole article about declaring test data in a clean way. You can read it here.
Best practices summary
- Naming is important. Test suite names should be declarative enough to understand their purpose.
- Do not group assertions that have nothing in common.
- Specific error messages are the key to quick bug spotting.
- Test data initialization is important. Do not neglect this.
But the main thing you should remember about testing is:
Tests should help to write code, but not increase the burden of maintenance.
Tools
There are dozens of testing libraries and frameworks on the market. I’m going to list the most popular ones for the Java language.
JUnit
The de facto standard for Java. Used in most projects. It provides a test running engine and assertion library combined in one artefact.
Mockito
The most popular mocking library for Java. It provides a friendly fluent API to set testing mocks. Take a look at the example below:
public class SomeSuite {
@Test
void someTest() {
// creates a mock for CommentService
CommentService mockService = mock(CommentService.class);
// when mockService.getCommentById(1) is called, new Comment instance is returned
when(mockService.getCommentById(eq(1)))
.thenReturn(new Comment());
// when mockService.getCommentById(2) is called, NoSuchElementException is thrown
when(mockService.getCommentById(eq(2)))
.thenThrow(new NoSuchElementException());
}
}Spock
As the documentation says, this is an enterprise-ready specification framework. In a nutshell, it has a test runner, and assertion and mocking utils. You write Spock tests in Groovy instead of Java. Here is a simple case validating that 2 + 2 = 4:
def "two plus two should equal four"() {
given:
int left = 2
int right = 2
when:
int result = left + right
then:
result == 4
}Vavr Test
Vavr Test requires special attention. This one is a property testing library. It differs from regular assertion-based tools. Vavr Test provides an input value generator. For each generated value it checks the invariant result. If this is false, the amount of test data is reduced until only the failures remain. Take a look at the example below that checks that whether the isEven function is working correctly:
public class SomeSuite {
@Test
void someTest() {
Arbitrary<Integer> evenNumbers = Arbitrary.integer()
.filter(i -> i > 0)
.filter(i -> i % 2 == 0);
CheckedFunction1<Integer, Boolean> alwaysEven =
i -> isEven(i);
CheckResult result = Property
.def("All numbers must be treated as even ones")
.forAll(evenNumbers)
.suchThat(alwaysEven)
.check();
result.assertIsSatisfied();
}
}Conclusion
Testing is a significant part of software development, and unit tests are fundamental. They represent the basis for all kinds of automation tests, so it’s crucial to write unit tests to the highest standard of quality.
The biggest advantage of tests is that they can run without manual interactions. Be sure that you run tests in the CI environment on each change in a pull request. If you don’t do this, the quality of your project will suffer. Semaphore CI is a brilliant CI/CD tool for automating and running tests and deployments, so give it a try.
That’s that! If you have any questions or suggestions, you can text me or leave your comments here. Thanks for reading!

Great! Good and Informative blog about software testing.