Large Language Models (LLMs) are becoming more and more employed in various applications, ranging from natural language processing to predictive analytics.
Considering the resources needed to use LLMs, in this article we’ll discuss how to keep down the costs associated when self-hosting LLMs. In the case of self-hosting, LLM costs, in fact, can be prohibitive, especially for mid-sized companies. So, in this article, we provide practical strategies to help you manage and reduce the costs associated with self-hosting LLMs.
Strategy 1 to Keep Self-hosted LLM Costs Down: Optimize Model Selection
The first step to keep LLM costs down is selecting the right model for your needs. Not all applications, in fact, require the largest, most powerful models available. So, here are some considerations to keep in mind:
- Performance requirements. Determine the level of performance you need. For example, if your application involves basic text classification or sentiment analysis, smaller models like DistilBERT might be sufficient. For more complex tasks, instead, such as generating coherent text or answering detailed questions, larger models like GPT-3 may be necessary.
- Model size and capabilities. Larger models require more computational resources and this increases the costs. So, evaluate models based on their size, number of parameters, and specific capabilities to ensure you are not overpaying for unnecessary features.
- Domain-specific models. Consider models that are fine-tuned for your specific domain. These models often provide better performance with fewer resources compared to general-purpose models. For example, if you work in the biomedical field you might find useful the BioBERT model, which is a pre-trained biomedical language representation model based on BERT, designed to handle various biomedical text mining tasks such as named entity recognition, relation extraction, and question answering. Or, if you work in the financial industry, you may find interesting the FinBERT model, which is a pre-trained language model specifically designed for financial sentiment analysis, particularly suitable for tasks such as sentiment classification, financial text summarization, and risk assessment.
- Open-Source Alternatives: Explore open-source models that can be hosted on-premises. These models often have lower licensing costs and provide more flexibility in terms of deployment and customization. BERT, among the others, is one famous example of open-source LLM.
Strategy 2 to Keep Self-hosted LLM Costs Down: Efficient Resource Allocation
Considering the fact that LLMs use a huge amount of computational resources, proper resource management is essential for reducing the costs of self-hosting these models, considering the cost of the hardware.
Here are some strategies to optimize hardware usage to save costs:
- Leverage GPUs effectively. To self-host LLMs you need machines that use GPUs, but they are expensive. So, to save costs on GPUs the main idea is to utilize GPU resources effectively by ensuring high utilization rates. This might involve implementing techniques and methodologies like batching requests, optimizing the code to reduce idle times, and using GPU-sharing techniques such as multi-GPU environments.
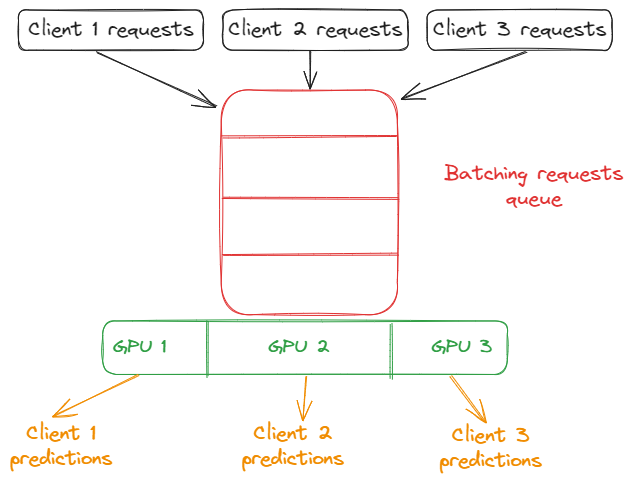
- Dynamic resource management. Use virtualization to dynamically allocate resources to the LLM based on demand. Tools like VMwareor Proxmox allow you to create virtual machines (VMs) that can be scaled up or down depending on current needs.
- Containerization. As containers can be spun up or down dynamically on your self-hosted infrastructure, you can implement a container orchestration strategy with Kubernetes or Docker Swarm to manage resource allocation efficiently. Containers, in fact, allow for better resource allocation and can be easily moved across different environments, ensuring optimal usage of available resources.
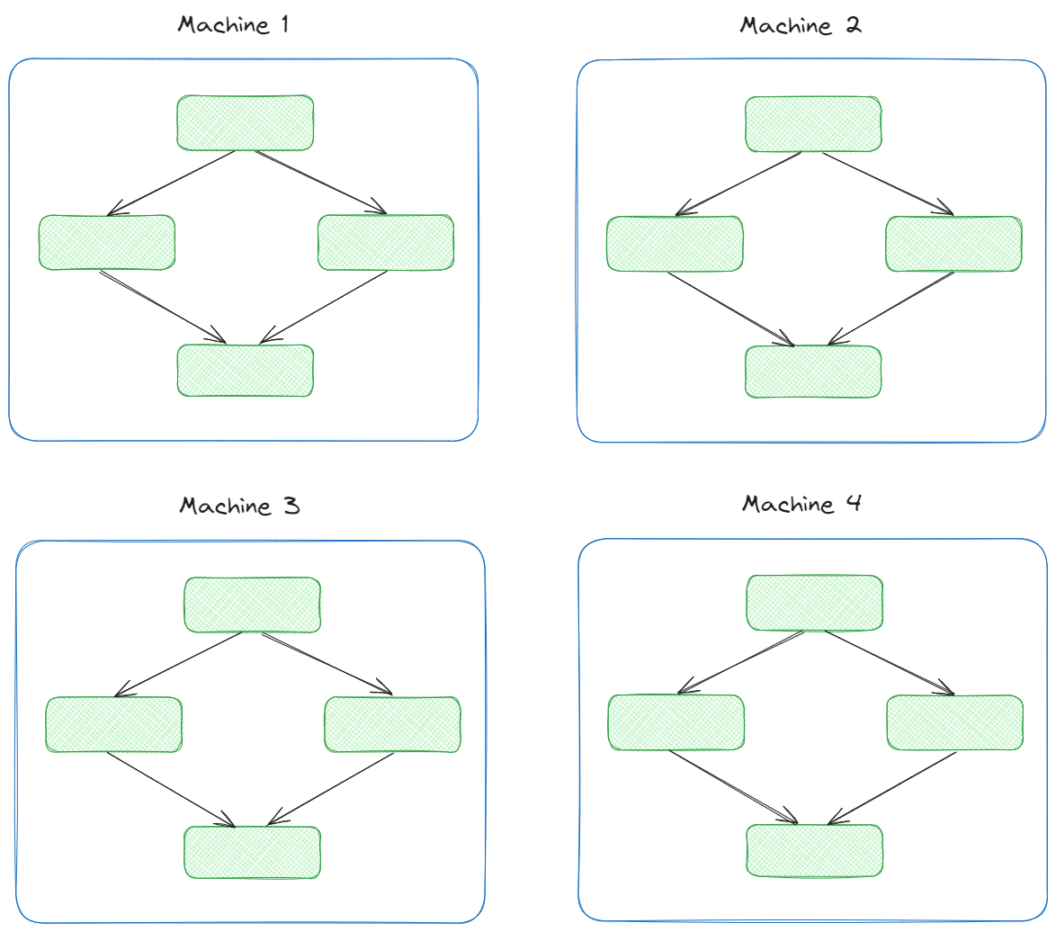
- Implement data parallelism methodologies. Data parallelism involves splitting the data across multiple GPUs or machines, allowing each GPU to process a portion of the data simultaneously. This approach can speed up the training and inference processes, provinding also an efficient use of the available hardware resources. Depending on your hardware setup and the framework you use, to implement data parallelism Pytorch provides the
torch.nn.parallel.DistributedDataParallelclass while Tensorflow provides thetf.distribute.MirroredStrategyclass.
As an example, let’s consider the implementation of data parallelism methodologies with Pytorch.
First of all, you have to discern based on your architecture. The cases are:
- Single-machine with a multi-GPU setup.
- Multi-machine setup.
NOTE: if you haven’t already done so, you need to install Pytorch
Single-machine with a multi-GPU setup: In a single-machine setup with multiple GPUs, you can use frameworks like PyTorch (or TensorFlow) to distribute batches of data across GPUs. Each GPU processes its batch independently, and gradients are aggregated and averaged before updating the model parameters.
The implementation could be something like this:
import torch
from torch.nn.parallel import DataParallel
# Initiate the LLM model
model = YourLLM-Model()
# Parallelize model across GPUs
model = DataParallel(model)
# Move model to GPUs
model.to('cuda')
# Iterate over data loader
for data in dataloader:
inputs, labels = data
inputs, labels = inputs.to('cuda'), labels.to('cuda')
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()The “magic” with the above code happens thanks to:
model = DataParallel(model): the LLM model is wrapped with the methodDataParallel(), parallelizes the model across multiple GPUs. This means that the input data will be split and processed in parallel by different GPUs, speeding up the training process.model.to('cuda'): the LLM model is moved to the GPU by calling the.to('cuda')method. This ensures that the model computations are performed on the GPU (which is faster than the CPU for deep learning tasks).- The iterations over the
dataloader: Thedataloaderis an iterator that provides batches of input data and labels. In each iteration, it yields a new batch.
Multi-machine setup: For multi-machine setups, use torch.distributed in PyTorch or tf.distribute.MultiWorkerMirroredStrategyin TensorFlow. This approach synchronizes data processing across machines, making efficient use of distributed hardware resources.
For example, the implementation could be something like this:
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# Initialize the process group
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Destroy the process group (to clean up resources used for distributed training)
def cleanup():
dist.destroy_process_group()
# Train the LLM model
def train(rank, world_size):
setup(rank, world_size)
model = YourLLM-Model().to(rank)
ddp_model = DDP(model, device_ids=[rank])
optimizer = torch.optim.Adam(ddp_model.parameters())
for data in dataloader:
inputs, labels = data
inputs, labels = inputs.to(rank), labels.to(rank)
outputs = ddp_model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
cleanup()
if __name__ == "__main__":
# Define the number of GPUs or nodes
world_size = 4 # 4 is just a representation
# Handle the parallel execution
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)So, in this case, the code initiates and destroys the processes to save resources and distribute them among different machines. Also, note that, in this case, model = YourLLM-Model().to(rank) moves the model to the appropriate GPU specified by rank, which represents a unique (integer) identifier for each process within a distributed system, that ranges from 0 to “world_size – 1″.
For example, in a machine with 4 GPUs, ranks 0, 1, 2, and 3 would typically map to GPU 0, GPU 1, GPU 2, and GPU 3 respectively.
Strategy 3 to Keep Self-hosted LLM Costs Down: Implementing Model Compression Techniques
Another way to reduce LLM costs when self-hosting is to use model compression techniques.
Here are some of the most used techniques:
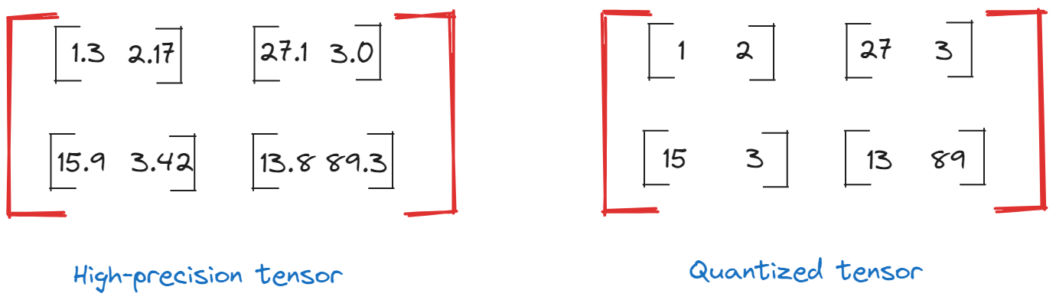
- Quantization. Quantization is a methodology that reduces the precision of the model’s weights from 32-bit floating-point to 16-bit or even 8-bit integers. This decreases the model size and speeds up inference times, leading to lower resource usage. Since, in the case of LLMs, computational models are represented in the memory of GPUs as tensors, to store them we can use different data types like Float64, Float16, or integers. Since the data type you choose impacts the number of digits used in memory, shortening digits passing from floats to integers, for example, reduces memory utilization.
- Pruning. Pruning is a methodology that involves removing less important weights from the model to reduce the model’s size while maintaining performance within acceptable limits. There are different ways to prune LLMs, most of them still at an experimental stage. The LLM-Pruner is one of them; it tackles the compression of LLMs within the bound of two constraints: being task-agnostic and minimizing the reliance on the original training dataset.
- Knowledge distillation. This technique involves training a smaller model (called the student) to replicate the behavior of a larger model (called the teacher). In other words, This technique involves using a smaller model that can achieve comparable performance with a fraction of the computational resources. The main idea behind knowledge distillation is to transfer advanced capabilities from leading proprietary LLMs, such as GPT-4, to their open-source counterparts like LLaMA and Mistral.
- Low-rank factorization. Since LLMs are Neural Networks that contain dense layers performing matrix multiplication, the idea behind low-rank factorization is to decompose the weight matrices of the neural network into products of smaller matrices. This way, we reduce the number of parameters and computations required, leading to faster and more efficient models.
- Sparse representations. Utilizing sparsity with neural networks can reduce the model size and computation time, especially with LLMs. Typical techniques to use can be L1 regularization and using Sparse Transformers.
As an example, let’s consider how to apply the quantization technique to an LLM using Pythorch.
But first, if you haven’t already done so, you need to install the transformers library:
pip install torch transformersNow, let’s see the quantization example:
import torch
from transformers import DistilBertModel, DistilBertTokenizer
# Load the tokenizer and model
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased')
# Tokenize sample input text
input_text = "Quantization can help reduce model size and improve inference speed."
inputs = tokenizer(input_text, return_tensors='pt')
# Apply dynamic quantization to the model
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear}, # Specify the layers to quantize
dtype=torch.qint8 # Specify the target data type
)
# Verify that the model is quantized
print(quantized_model)
# Move the model to the appropriate device (CPU)
device = torch.device('cpu')
quantized_model.to(device)
# Perform inference
with torch.no_grad():
outputs = quantized_model(**inputs)
# Print the output tensor
print(outputs.last_hidden_state)In this example, we applied dynamic quantization to the linear layers of the DistilBERT model with the method torch.quantization.quantize_dynamic(), converting them to 8-bit integers (qint8): this reduces the model size and improves inference speed on supported hardware.
Strategy 4 to Keep Self-hosted LLM Costs Down: Effective Data Management
Efficient data management can minimize storage and processing costs. This is particularly useful when using LLMs, because, since these models require a huge amount of data, effectively managing them can significantly decrease associated costs.
Here are some best practices to do so:
- Data preprocessing. To reduce the amount of data an LLM needs to process – thus, saving on hardware resources – a best practice is to preprocess the data before feeding the model with it. In the case of LLMs, you can generally follow these steps for preprocessing data:
- Data cleaning. Remove noise like special characters, HTML tags, and irrelevant content.
- Handle Missing Data. Address gaps in the dataset through imputation or removal.
- Normalization. Standardize text by converting to lowercase, handling contractions, and standardizing punctuation.
- Tokenization. Split text into meaningful tokens, like words or subwords.
- Stop words removal. Eliminating the common words that add little value to the text (e.g., “the,” “and”).
- Data balancing. Ensure diverse and representative data to prevent model bias.
- Encoding. Convert text into numerical format using techniques like word embeddings or token IDs.
- Caching. Caching temporarily stores copies of data to improve access speed and reduce latency. By keeping frequently accessed data in a high-speed storage layer (usually RAM), caching minimizes the need to repeatedly fetch data from slower storage or remote servers. This boosts performance and efficiency, particularly for repeated read operations. So, in the context of LLMs, to reduce the need to repeatedly process or access the same data, you can implement a caching system for frequently accessed or processed data; this will save on computational resources.
- Data lakes and warehouses. As LLMs need to ingest and process large quantities of data, you should retrieve this data somewhere. Today, data lakes, data warehouses, and data lakehouses (like Snowflake or Databricks, just to name a few) allow you to store and manage large volumes of data efficiently, at low fees. Well, indeed it’s more cost-effective to use them than to store data on your hardware. To get an idea, you can see Snowflake and Databricks pricing models.
Conclusions
In this article, we’ve discussed four methodologies to keep self-hosted LLM costs down.
The important concept to bear in mind is that these methodologies can be combined together to provide even better results in saving costs.
So, for example, given your needs and infrastructure, you can decide to containerize a pruned LLM, while implementing batching techniques and a caching system.
