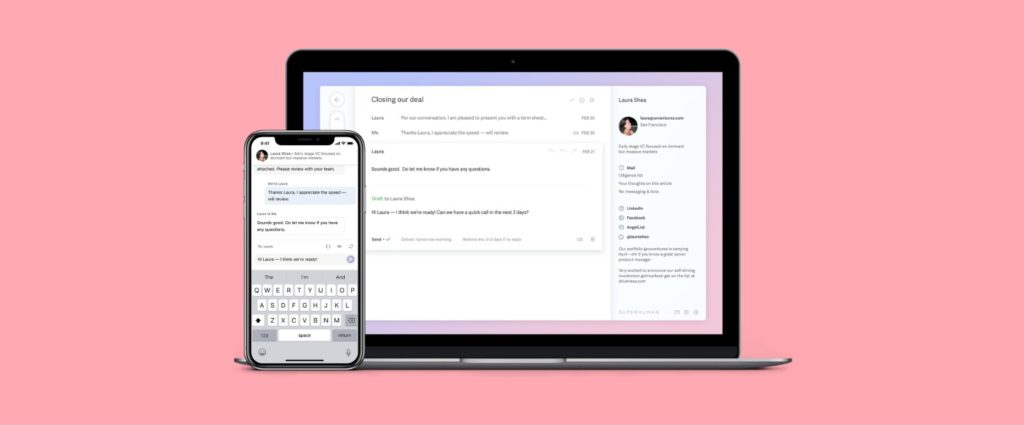
Superhuman is not just another email client. They rebuilt the inbox from the ground up to make people brilliant at what they do. Superhuman is blazingly fast, and visually gorgeous. It comes with advanced features to make people feel Superhuman: A.I. triage, undo send, insights from social networks, follow-up reminders, scheduled messages, and read statuses.

The Challenge
Superhuman prides itself on being the fastest email client in the world, and wants to live the value of speed for all of their internal tooling. Before Semaphore, running the tests and deploying was too slow. The team behind Superhuman used Wercker for the backend (which was acquired by Oracle a few years ago). Their frontend CI service used the “old-school model” of charging for peak parallelism, and they also had yet another CI service to run the builds for the desktop client.
Superhuman needed a service that:
- Was built from the ground up to be fast.
- Could support macOS code-signing.
- Charged for actual time used, not peak parallelism.
- Has a high level of peak parallelism.
- Who’d reply to them when they emailed.
The Solution
The Superhuman backend is written in Go. When code is pushed to any branch, Semaphore builds and runs the tests. When the tests pass on 'master' or on 'staging', Semaphore builds Docker images, uploads those to Google Container Registry, and then gradually rolls them out to our Google Container Engine cluster.
The frontend is written in JavaScript. When code is pushed to any branch, Semaphore runs Zen (a test runner built by one of their engineers) to run all the tests. Zen compiles the code, uploads it to S3 and boots up 600 AWS Lambda instances to run the tests in parallel (the Semaphore worker co-ordinates this). When the tests pass on the 'staging', or 'production' branches, Semaphore automatically builds a bundle and uploads it to Google Cloud Storage.
The Results
Semaphore has significantly better performance, the machines are not overloaded and you can run many builds in parallel. It is also way cheaper than the old model reserving capacity and resources for 10 parallel jobs (which is a waste 80% of the time, and not enough 10% of the time).
- Better performance
- The machines are not overloaded
- Run many builds in parallel
- Cheaper than the old model

