In this tutorial, we will take a look at how Kafka can help us with handling distributed messaging, by using the Event Sourcing pattern that is inherently atomic. Then, by using a pattern called Command-Query Responsibility Segregation (CQRS), we can have a materialized view acting as the gate for data retrieval. Finally, we’ll learn how to make our consumer redundant by using consumer group. The whole application is delivered in Go.
Why We Need Microservices
The most common argument that calls for microservices is scalability first and foremost. As an application grows, it can be hard to maintain all the code and make changes to it easily.
This is why people turn to microservices. By decomposing a big system and creating various microservices for handling specific functions (e.g. a microservice to handle user management, a microservice to handle purchase, etc.), we can easily add new features to our application.
The Challenges of Building Microservices
However, building a microservice can be challenging. One of the challenges is atomicity — a way of dealing with distributed data, inherent to microservice architecture.
Querying is also a challenge. It can be quite difficult to do a query like this when a customer and an order are two different services:
select * from order o, customer c
where o.customer_id = c.id
and o.gross_amount > 50000
and o.status = 'PAID'
and c.country = 'INDONESIA';
The two architectural patterns are that are key for creating a microservice-based solution are Command-Query Responsibility Segregation, and Event Sourcing, when it makes sense.
Not all systems require event sourcing. Event sourcing is good for a system that needs audit trail and time travel. If the system in question needs only basic decoupling from a larger system, event-driven design is probably a better option.
Kafka in a Nutshell
If we compare Kafka to a database, a table in a database is a topic in Kafka. Each table can have data expressed as a row, while in Kafka, data is simply expressed as a commit log, which is a string. Each of the commit logs has an index, aka an offset. In Kafka, the order of commit logs is important, so each one of them has an ever-increasing index number used as an offset.
However, unlike a table in a SQL database, a topic should normally have more than one partition. As Kafka performance is guaranteed to be constant at O(1), each partition can hold thousands, millions, or even more commit logs, and still do a fine job. Each partition then holds different logs.
Partitioning is the the process through which Kafka allows us to do parallel processing. Thanks to partitioning, each consumer in a consumer group can be assigned to a process in an entirely different partition. In other words, this is how Kafka handles load balancing.
Each message is produced somewhere outside of Kafka. The system responsible for sending a commit log to a Kafka broker is called a producer. The commit log is then received by a unique Kafka broker, acting as the leader of the partition to which the message is sent. Upon writing the data, each leader then replicates the same message to a different Kafka broker, either synchronously or asynchronously, as desired by the producer. This Producer-Broker orchestration is handled by an instance of Apache ZooKeeper, outside of Kafka.
Kafka is usually compared to a queuing system such as RabbitMQ. What makes the difference is that after consuming the log, Kafka doesn’t delete it. In that way, messages stay in Kafka longer, and they can be replayed.
Setting Up Kafka
In this section, we will see how to create a topic in Kafka.
Kafka can be downloaded from either Confluent’s or Apache’s website. The version that you need to download is in the 0.10 family. We’ll be using 0.10.1.0 in this tutorial.
First, start ZooKeeper:
$ cd ~/Downloads/kafka
$ bin/zookeeper-server-start.sh config/zookeeper.properties
We will run a single Kafka broker for the time being:
$ bin/kafka-server-start.sh config/server.properties
Then, we will create our first topic:
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partition 1 --topic xbanku-transactions-t1
Running multiple Kafka instances is very easy, just cp the server.properties file and make the necessary changes:
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
To start the brokers, we must specify the file properly, as follows:
$ bin/kafka-server-start.sh config/server-1.properties
$ bin/kafka-server-start.sh config/server-2.properties
That way, we have two running Kafka brokers inside our machine.
Writing a Producer
Our Banku Corp, a top banking corporation had an increase in clients and transactions. The systems were interconnected, and massive. We want to separate them somehow.
First, we want the balance calculation logic to stay out of the gigantic, monolithic application running on a mainframe developed in 1987. We decided that Kafka is good match for the job.
We analyzed some contracts, and agreed that the events that need to be handled by microservices are the following:
- CreateEvent — when opening a new bank account,
- DepositEvent — when someone deposits money to their account,
- WithdrawEvent — when someone withdraws money from their account, and
- TransferEvent — when someone transfers their money to someone else’s account.
An event does not contain all of the data for an account, e.g. the account holder’s name, balance, registration date, and so on. An event contains only the name of the event, and the necessary fields such as the ID and the changing attribute.
The whole snapshot exists only as a mere reflection of past events. That way, by using events, we can recreate the data up to the point we desire.
Let’s start with creating a new folder, banku, and then use govendor to initiate the directory and serve for the project’s dependency management (yes, Go has a lot of them, and no de facto standard yet).
$ govendor init
$ govendor add +external
We will be using govendor fetch instead of go getto add a vendor or dependency for Banku. However, we need togo get` ginkgo and gomega for a BDD-style testing.
$ go get github.com/onsi/ginkgo/ginkgo
$ go get github.com/onsi/gomega
$ ginkgo bootstrap
Let’s begin coding. First, let’s define our collection of Events in an events.go. We want to do it the TDD-way this time, therefore, let’s define our test file events_test.go:
package main_test
import (
. "banku"
. "github.com/onsi/ginkgo"
. "github.com/onsi/gomega"
)
var _ = Describe("Event", func() {
Describe("NewCreateAccountEvent", func() {
It("can create a create account event", func() {
name := "John Smith"
event := NewCreateAccountEvent(name)
Expect(event.AccName).To(Equal(name))
Expect(event.AccId).NotTo(BeNil())
Expect(event.Type).To(Equal("CreateEvent"))
})
})
})
To run that, type in ginkgo, and we should see this error:
go build banku: no buildable Go source files in /Users/adampahlevi/Go/src/banku
This is because our app is packaged with main — it expects an executable main() function. Let’s create a simple main.go file:
package main
func main() {
}
Let’s re-run the ginkgo, and we should see the following errors:
Failed to compile banku:
# banku_test
./events_test.go:4: imported and not used: "banku"
./events_test.go:19: undefined: NewCreateAccountEvent
Ginkgo ran 1 suite in 1.442472804s
Test Suite Failed
By following TDD guidelines, we can go from red to green with as little code as possible.
To make it green, we first define an Event struct at our events_test.go:
type Event struct {
AccId string
Type string
}
Each corresponding Event should “inherit” the Event struct:
type CreateEvent struct {
Event
AccName string
}
After that, we define a function which will help us create a new CreateEvent:
func NewCreateAccountEvent(name string) CreateEvent {
event := new(CreateEvent)
event.Type = "CreateEvent"
event.AccId = uuid.NewV4().String()
event.AccName = name
return *event
}
If we run ginkgo again, we will see our test passing:
Running Suite: Banku Suite
==========================
Random Seed: 1490709758
Will run 1 of 1 specs
•
Ran 1 of 1 Specs in 0.000 seconds
SUCCESS! -- 1 Passed | 0 Failed | 0 Pending | 0 Skipped PASS
Ginkgo ran 1 suite in 905.68195ms
Test Suite Passed
Note that we need to install and import the go.uuid library since we are using uuid in the NewCreateAccountEvent, which is an imported package. We may also use another package/technique for generating the ID.
We need to define 3 other structs and functions for the deposit, withdrawal, and transfer events. You may write them yourself, or look up the implementation here.
Next, let’s define the BankAccount model inside a bank_account.go file.
package main
type BankAccount struct {
Id string
Name string
Balance int
}
In this file, we will also define the following functions:
- If an account can be found inside Redis,
FetchAccount(id)returns a*BankAccount(pointer to aBankAccountinstance). updateAccount(id, data)updates some datadatafor a given account with an ID typeid.ToAccount(map)converts map/hash into a proper*BankAccountobject.
To materialize the state, we will be using Redis using go-redis library. It will materialize the view in this example to keep things downright simple.
// main.go
import (
...
"github.com/go-redis/redis"
)
var (
Redis = initRedis()
)
func initRedis() *redis.Client {
redisUrl := os.Getenv("REDIS_URL")
if redisUrl == "" {
redisUrl = "127.0.0.1:6379"
}
return redis.NewClient(&redis.Options{
Addr: redisUrl,
Password: "",
DB: 0,
})
}
Next, we define a kafka.go to deal with our Kafka things through Sarama, one of the principal libraries which helps us to communicate with Kafka.
package main
import (
"encoding/json"
"fmt"
"github.com/Shopify/sarama"
"os"
)
var (
brokers = []string{"127.0.0.1:9092"}
topic = "banku-transactions"
topics = []string{topic}
)
Let’s define a function to create the Kafka configuration needed to instantiate both Sarama’s SyncProducer and Consumer:
func newKafkaConfiguration() *sarama.Config {
conf := sarama.NewConfig()
conf.Producer.RequiredAcks = sarama.WaitForAll
conf.Producer.Return.Successes = true
conf.ChannelBufferSize = 1
conf.Version = sarama.V0_10_1_0
return conf
}
The producer itself is as follows:
func newKafkaSyncProducer() sarama.SyncProducer {
kafka, err := sarama.NewSyncProducer(brokers, newKafkaConfiguration())
if err != nil {
fmt.Printf("Kafka error: %s\n", err)
os.Exit(-1)
}
return kafka
}
Then, let’s create a producer.go, which our main() function will call when the application performs as a producer. We will basically define a mainProducer() function:
import (
"bufio"
"fmt"
"os"
"strconv"
"strings"
)
func mainProducer() {
var err error
reader := bufio.NewReader(os.Stdin)
kafka := newKafkaSyncProducer()
for {
fmt.Print("-> ")
text, _ := reader.ReadString('\n')
text = strings.Replace(text, "\n", "", -1)
args := strings.Split(text, "###")
cmd := args[0]
switch cmd {
case "create":
if len(args) == 2 {
accName := args[1]
event := NewCreateAccountEvent(accName)
sendMsg(kafka, event)
} else {
fmt.Println("Only specify create###Account Name")
}
default:
fmt.Printf("Unknown command %s, only: create, deposit, withdraw, transfer\n", cmd)
}
if err != nil {
fmt.Printf("Error: %s\n", err)
err = nil
}
}
}
Last, we define sendMsg inside kafka.go:
// kafka.go
func sendMsg(kafka sarama.SyncProducer, event interface{}) error {
json, err := json.Marshal(event)
if err != nil {
return err
}
msgLog := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.StringEncoder(string(json)),
}
partition, offset, err := kafka.SendMessage(msgLog)
if err != nil {
fmt.Printf("Kafka error: %s\n", err)
}
fmt.Printf("Message: %+v\n", event)
fmt.Printf("Message is stored in partition %d, offset %d\n",
partition, offset)
return nil
}
So far, our producer can only handle the create command.
To run the producer, just call:
go build && ./banku
Don’t forget to change our main() function to invoke mainProducer():
func main() {
mainProducer()
}
At our producer console, we can try sending a new command:
-> create###Adam Pahlevi
Nothing will happen, since we haven’t created the consumer that will process all those messages.
Consuming Events
Whenever there is an event coming, a consumer must set a clear contract, whether the event is for event sourcing or command sourcing. While both can be replayed, only event sourcing is side-effect free.
Carefully designing the contract allows us to avoid executing unnecessary commands. For instance, upon receiving a UserCreated event, the user should receive a welcome email. Then, replaying the same event must never send the email again by contract. In our case, all three events are purely event sourcing.
Since event sourcing stores the current state as a result of various events, it would be time consuming to look up the current state by always replaying the event. In such cases, CQRS comes in handy, as it allows us to maintain a materialized view as a result of the events we are receiving.
First, we need to create a process() function for each Event in a file named processor.go:
package main
func (e CreateEvent) Process() error {
return nil
}
func (e InvalidEvent) Process() error {
return nil
}
func (e AcceptEvent) Process() error {
return nil
}
Then, redefine each of the process() functions:
package main
import (
"errors"
)
func (e CreateEvent) Process() (*BankAccount, error) {
return updateAccount(e.AccId, map[string]interface{}{
"Id": e.AccId,
"Name": e.AccName,
"Balance": "0",
})
}
// other Process() codes ...
These process methods will be invoked later by our consumer. The consumer.go file itself starts out with a simple mainConsumer function:
func mainConsumer(partition int32) {
kafka := newKafkaConsumer()
defer kafka.Close()
consumer, err := kafka.ConsumePartition(topic, partition, sarama.OffsetOldest)
if err != nil {
fmt.Printf("Kafka error: %s\n", err)
os.Exit(-1)
}
go consumeEvents(consumer)
fmt.Println("Press [enter] to exit consumer\n")
bufio.NewReader(os.Stdin).ReadString('\n')
fmt.Println("Terminating...")
}
Note that we are using sarama.OffsetOldest, which means that Kafka will be sending a log all the way from the first message ever created. This may be good for development mode since we don’t need to write message after message to test out features. In production, we definitely would want to change it with sarama.OffsetNewest, which will only ask for the newest messages that haven’t been sent to us.
The new newKafkaConsumer function is then defined at kafka.go as follows:
func newKafkaConsumer() sarama.Consumer {
consumer, err := sarama.NewConsumer(brokers, newKafkaConfiguration())
if err != nil {
fmt.Printf("Kafka error: %s\n", err)
os.Exit(-1)
}
return consumer
}
The message processing itself is happening inside a goroutine consumeEvents.
func consumeEvents(consumer sarama.PartitionConsumer) {
var msgVal []byte
var log interface{}
var logMap map[string]interface{}
var bankAccount *BankAccount
var err error
for {
select {
case err := <-consumer.Errors():
fmt.Printf("Kafka error: %s\n", err)
case msg := <-consumer.Messages():
msgVal = msg.Value
}
}
}
We used the for and the blocking <- channel operator to ensure that our code continues to wait for incoming messages to that channel forever, or until the program terminates.
Inside the case for msg, let’s add the processing code:
if err = json.Unmarshal(msgVal, &log); err != nil {
fmt.Printf("Failed parsing: %s", err)
} else {
logMap = log.(map[string]interface{})
logType := logMap["Type"]
fmt.Printf("Processing %s:\n%s\n", logMap["Type"], string(msgVal))
switch logType {
case "CreateEvent":
event := new(CreateEvent)
if err = json.Unmarshal(msgVal, &event); err == nil {
bankAccount, err = event.Process()
}
default:
fmt.Println("Unknown command: ", logType)
}
if err != nil {
fmt.Printf("Error processing: %s\n", err)
} else {
fmt.Printf("%+v\n\n", *bankAccount)
}
}
Since we have three more events, you can look at the complete consumer.go implementation, but basically it is just repeated for each event.
Ideally, the consumer and the producer are residing in altogether different source code repositories. However, to make it really short and convenient for us, we combine them into a single source code repository.
Therefore, our main() function must be able to tell if the user intended to start the program as a producer, or as a consumer. We will be using flag to help us with that.
import (
"flag"
...
)
func main() {
act := flag.String("act", "producer", "Either: producer or consumer")
partition := flag.String("partition", "0",
"Partition which the consumer program will be subscribing")
flag.Parse()
fmt.Printf("Welcome to Banku service: %s\n\n", *act)
switch *act {
case "producer":
mainProducer()
case "consumer":
if part32int, err := strconv.ParseInt(*partition, 10, 32); err == nil {
mainConsumer(int32(part32int))
}
}
}
To start the application as a consumer, invoke the application and pass the “act” flag with the consumer:
go build && ./banku --act=consumer
As soon as it runs, it will fetch messages out of Kafka, and process them one by one by invoking the Process() method on each event we have previously defined.
Clustering Consumer Instances
Answer the following question: what if a Banku consumer died? The program may have suddenly crashed, or the network is gone. That’s why we need to cluster the consumer, in other words, group the consumer.
What happens is that we have all consumer instances running, but labeled the same. When there’s a new log to send, Kafka will send it to just one instance. When that instance is unable to receive the log, Kafka will deliver the log to another subscriber within the same tag label.
This mechanism has been available since Kafka 0.9. However, the Sarama library we are using doesn’t support it. That’s why we will use Sarama Cluster library instead. It’s really simple to make a grouped consumer.
First, govendor needs to fetch it:
govendor fetch github.com/bsm/sarama-cluster
We need to change our mainConsumer methods so that the customer is instantiated from the cluster library:
config := cluster.NewConfig()
config.Consumer.Offsets.Initial = sarama.OffsetNewest
consumer, err := cluster.NewConsumer(brokers, "banku-consumer", topics, config)
The topics itself is defined as follows:
var (
topics = []string{topic}
)
Our consumeEvents signature should now accept consumer *cluster.Consumer instead of sarama.PartitionConsumer.
Case for consumer errors is changed to:
case err, more := <-consumer.Errors():
if more {
fmt.Printf("Kafka error: %s\n", err)
}
Inside the consumer.Messages() we MarkOffset the msg as soon as possible:
consumer.MarkOffset(msg, "")
msgVal = msg.Value
Now, let’s try running our cluster in different terminal shells for each line:
$ go build && ./banku --act=consumer
$ go build && ./banku --act=consumer
$ go build && ./banku --act=consumer
All of our past events will be consumed soon.
Welcome to Banku service: consumer
Press [enter] to exit consumer
Processing CreateEvent:
{"AccId":"cd371b90-e51b-4801-96fe-14bbe5ddc708","Type":"CreateEvent","AccName":"Adam Pahlevi"}
{Id:cd371b90-e51b-4801-96fe-14bbe5ddc708 Name:Adam Pahlevi Balance:0}
Processing DepositEvent:
{"AccId":"cd371b90-e51b-4801-96fe-14bbe5ddc708","Type":"DepositEvent","Amount":2000}
{Id:cd371b90-e51b-4801-96fe-14bbe5ddc708 Name:Adam Pahlevi Balance:2000}
Processing WithdrawEvent:
{"AccId":"cd371b90-e51b-4801-96fe-14bbe5ddc708","Type":"WithdrawEvent","Amount":2000}
{Id:cd371b90-e51b-4801-96fe-14bbe5ddc708 Name:Adam Pahlevi Balance:0}
Processing CreateEvent:
{"AccId":"3101ff16-0181-43e1-9153-f81533d5a0df","Type":"CreateEvent","AccName":"Timmy Richardo"}
{Id:3101ff16-0181-43e1-9153-f81533d5a0df Name:Timmy Richardo Balance:0}
Processing DepositEvent:
{"AccId":"cd371b90-e51b-4801-96fe-14bbe5ddc708","Type":"DepositEvent","Amount":5000}
{Id:cd371b90-e51b-4801-96fe-14bbe5ddc708 Name:Adam Pahlevi Balance:5000}
Processing TransferEvent:
{"AccId":"cd371b90-e51b-4801-96fe-14bbe5ddc708","Type":"TransferEvent","TargetId":"3101ff16-0181-43e1-9153-f81533d5a0df","Amount":1000}
{Id:3101ff16-0181-43e1-9153-f81533d5a0df Name:Timmy Richardo Balance:1000}
{Id:cd371b90-e51b-4801-96fe-14bbe5ddc708 Name:Adam Pahlevi Balance:4000}
Now, run our producer instance, and type in the following:
-> withdraw###cd371b90-e51b-4801-96fe-14bbe5ddc708###1500
Soon, one of our consumer in the same group will process that. The other consumer in the same group will be smart enough to ignore the incoming message to avoid double-processing it.
Now, let’s terminate two of the three consumers, and then send 3 messages at once:
-> withdraw###cd371b90-e51b-4801-96fe-14bbe5ddc708###500
-> withdraw###cd371b90-e51b-4801-96fe-14bbe5ddc708###1500
-> withdraw###cd371b90-e51b-4801-96fe-14bbe5ddc708###1500
-> withdraw###cd371b90-e51b-4801-96fe-14bbe5ddc708###100
The message is processed just fine.
Processing WithdrawEvent:
{"AccId":"cd371b90-e51b-4801-96fe-14bbe5ddc708","Type":"WithdrawEvent","Amount":100}
{Id:cd371b90-e51b-4801-96fe-14bbe5ddc708 Name:Adam Pahlevi Balance:400}
Testing and Continuous Integration
So far, we have written some of our tests the TDD way. We also strictly adhered to the four-phase test technique, to best split a test spec into 4 distinct phases:
- Setup,
- Execution,
- Verification, and
- Teardown.
In this section, we will add continuous integration to our Banku project to ensure that our code has passed all the tests before it is merged into the main branch.
We’ll use Semaphore as our continuous integration service. Let’s first integrate Semaphore CI to our GitHub repository for the source code of this article.
We will also be using Docker, which will help us with preparing our testing environment regardless of what is installed in the target environment.
Now, let’s dockerize our Golang application. Our Docker container needs to have the following:
- Golang,
- Redis, and
- The Banku dependency installed.
We will achieve this by utilizing a Dockerfile to specify the host our Banku application will be running on, as well as docker-compose to link together our Dockerfile with other dependencies, which is Redis in our case.
Create a Dockerfile at the root folder on Banku, specifying the FROM and MAINTAINER indicating the base image, and the maintainer info respectively:
FROM golang:1.8.0
MAINTAINER Adam Pahlevi
After that, let’s run the go get commands to install our dependencies: govendor, ginkgo and gomega:
RUN go get -u github.com/kardianos/govendor
RUN go get github.com/onsi/ginkgo/ginkgo
RUN go get github.com/onsi/gomega
Next, we need to copy our Banku folder at the host machine to the container:
ADD . /go/src/banku
Then, let’s make sure the working directory is set at our folder:
WORKDIR /go/src/banku
Lastly, we need to install any other dependencies needed by our Banku application:
RUN govendor sync
To test our Dockerfile locally, we can run the following commands at shell:
$ docker build -t banku .
$ docker run -i -t banku /bin/bash
You will then get connected to the container’s bash shell, and if you run ginkgo our tests will fail since there is no Redis instance running locally.
Why don’t we just include Redis as an image in the Dockerfile, so we can RUN any command we want?
Well, Docker views things layer by layer. Our application is just another layer, and Redis is a completely different layer. The docker-compose.yml and its docker-compose command is where we “connect” those layers to work together.
Let’s create a docker-compose.yml in the same folder with our Dockerfile, specifying the file version:
version: "2.0"
We want to have two services running when docker-compose is running this file, namely:
app, our Banku applicationredis, layer whichredis-serverwill run
To do that, we specify the services as follows:
version: "2.0"
services:
app:
redis:
Each service can either use image, or build. Specifying image will make the composer pull the image from Docker repository. On the other hand, when build is specified, a Dockerfile will be executed instead.
version: "2.0"
services:
app:
build: .
working_dir: /go/src/banku
links:
- redis
redis:
image: redis:alpine
By specifying redis under links, we make sure that it will be started when the composer is running the app service.
Since app and redis are running on different layers, we need to specify the REDIS_URL environment variable, so that our app can connect to a Redis server.
services:
app:
environment:
REDIS_URL: redis:6379
We can now try running docker-compose run app ginkgo locally.
Running Suite: Banku Suite
==========================
Random Seed: 1490687262
Will run 10 of 10 specs
••••••••••
Ran 10 of 10 Specs in 0.040 seconds
SUCCESS! -- 10 Passed | 0 Failed | 0 Pending | 0 Skipped PASS
Ginkgo ran 1 suite in 10.515240868s
Test Suite Passed
Our local build is successful. A great thing about Docker is that, by using just these two files, Semaphore is able to pick up and do the things necessary for running our tests. In short, this is what we hear about when people refer to infrastructure as a code.
The enabling idea of infrastructure as code is that the systems and devices which are used to run software can be treated as if they, themselves, are software. — Kief Morris
Now, let’s create a Semaphore account if you haven’t got one. Connect Semaphore with your git so that you can choose your repo to integrate with.
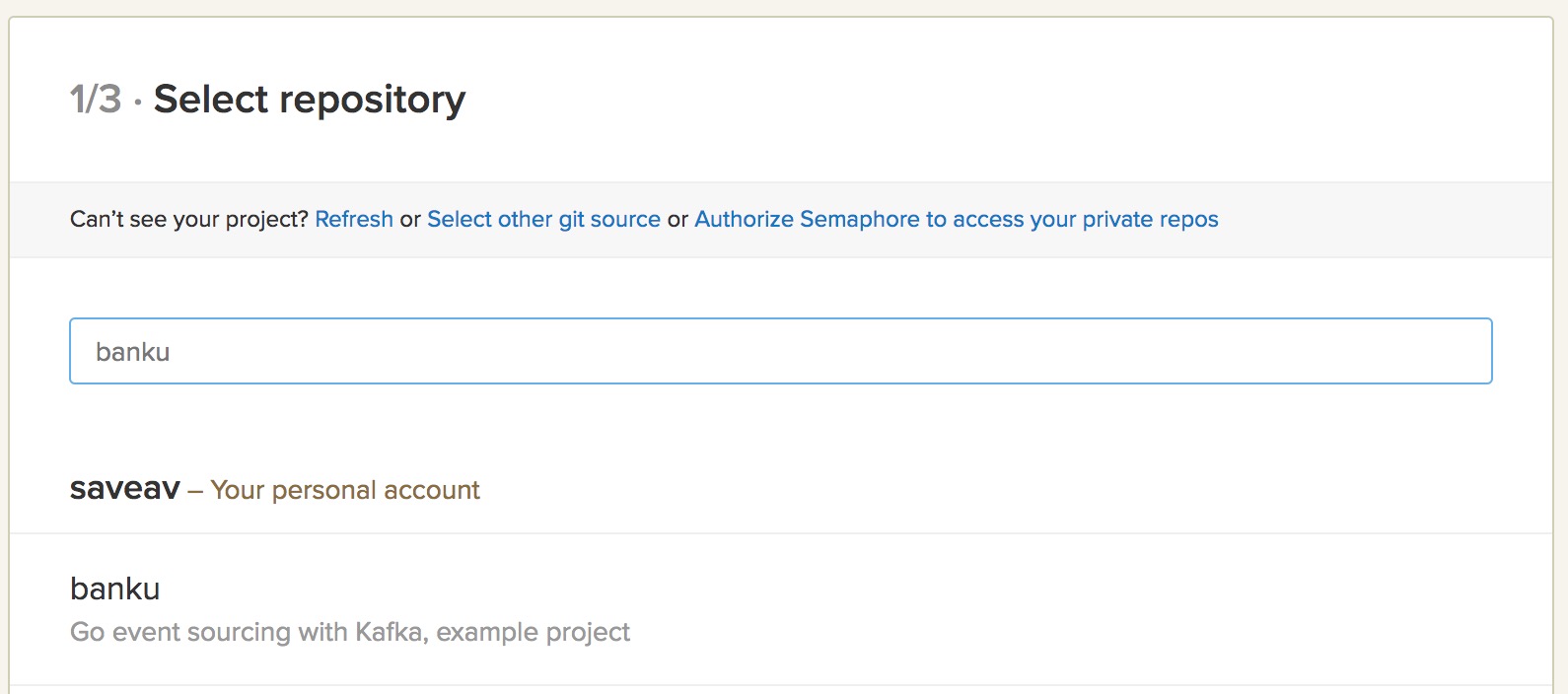
Then, choose the master branch so that Semaphore analyzes the code when a pull request is made on this branch.
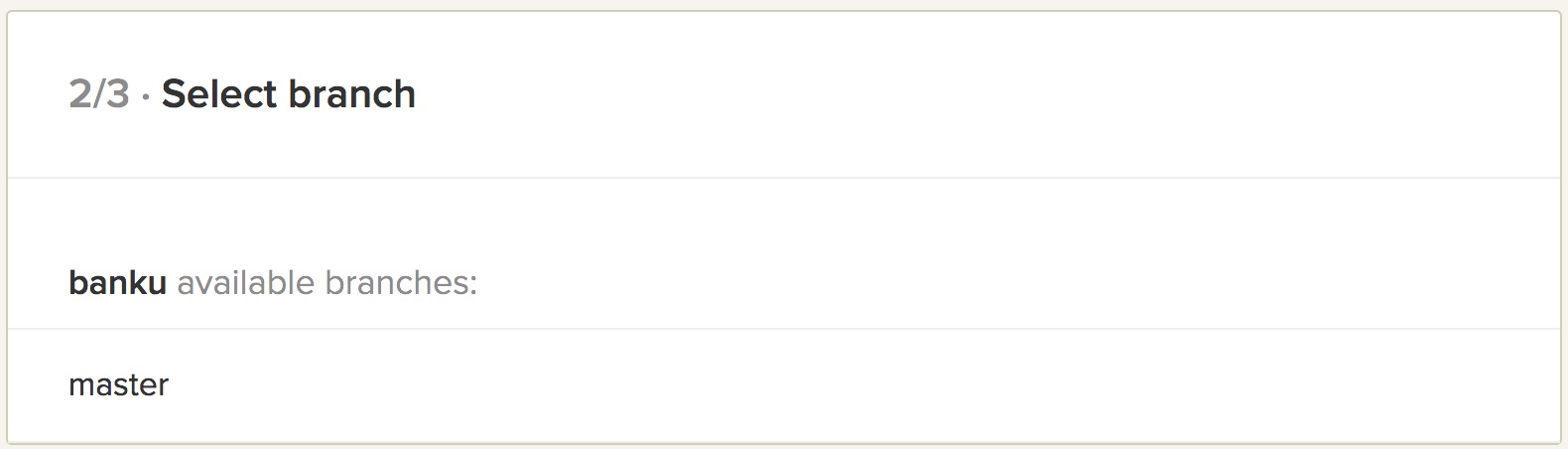
When it finds out that the repository contains a Dockerfile and docker-compose also, it will allow us to choose between platforms. Let’s just choose the recommended platform — Docker.
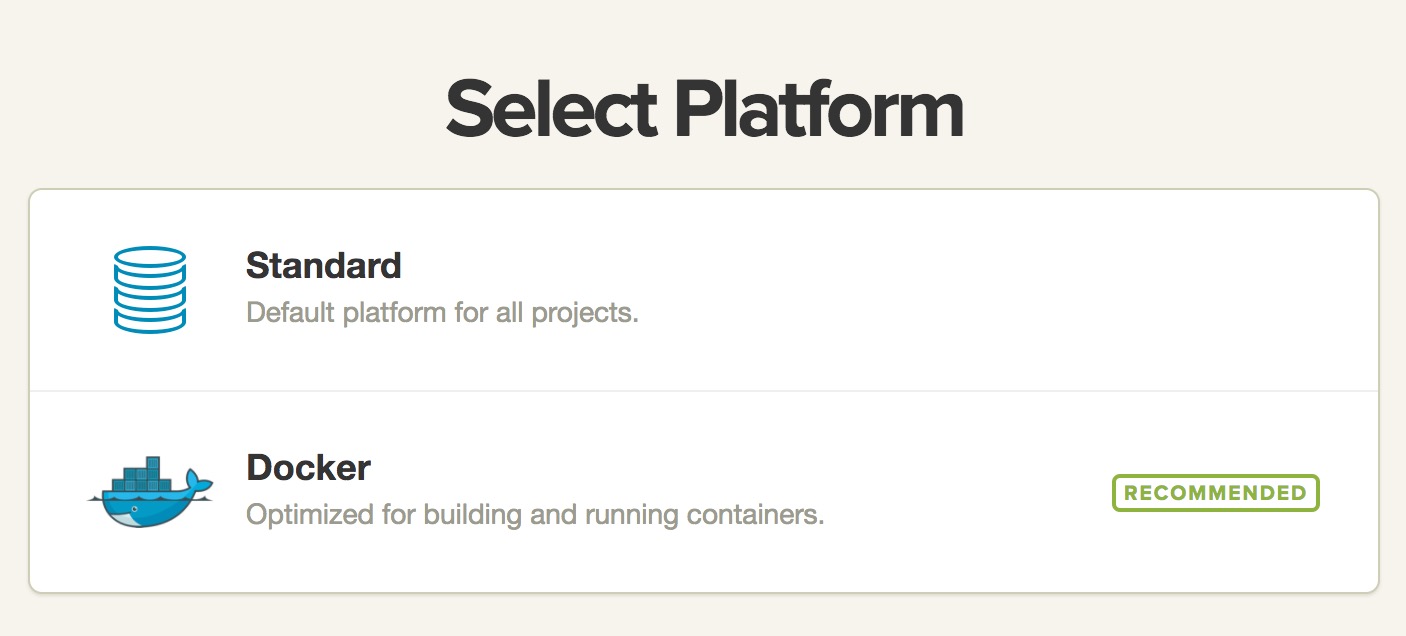
We can then set the setup script to:
docker-compose build
And the test script to :
docker-compose run app ginkgo
Those settings can later be found in Project Settings > Build Settings. Semaphore will run our test with the specified commands, and all of our tests should pass.
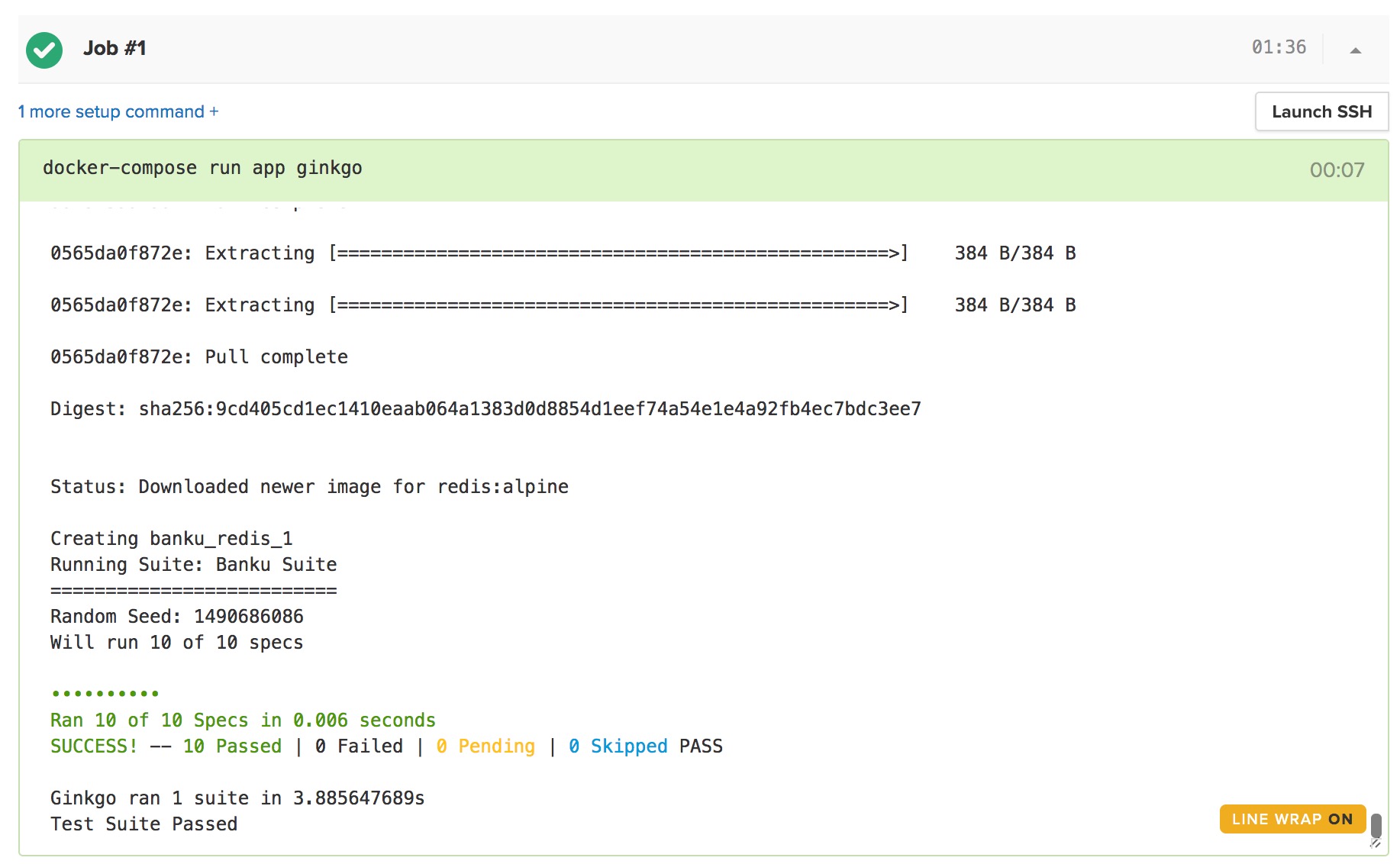
If you want to continuously deliver your applications made with Docker, check out Semaphore’s Docker platform with full layer caching for tagged Docker images.
Conclusion
In this tutorial, we have learned how to create and dockerize an event sourcing microservice in Go, by using Kafka as a message broker. We used Semaphore to perform continuous testing in the cloud.
If you have any questions or comments, feel free to leave them in the section below.