All jobs in Semaphore run on separate virtual machines, in a clean, isolated environment. They don’t really communicate with each other. But what if you need them to?
That’s where artifacts come in handy. With artifacts, you can store data on your projects and pass it between jobs, workflows, and projects. Let’s take a closer look at what artifacts are, how to create them, and what benefits they bring to your team.
What are artifacts?
Artifacts are files (screenshots, logs, test reports) that are uploaded to and stored in Semaphore. Once you upload an artifact in one job or workflow, you can then pull it from another job or workflow. This will allow your jobs to “communicate” with each other, passing the information between them.
There are three levels of artifacts in Semaphore:
Job level artifacts
Job artifacts are suitable for collecting debug data. You can use them for storing data like logs, screenshots and screencasts that make debugging easier.
To upload files to the job artifact store, use the following command:
artifact push job <my_file_or_dir>Workflow level artifacts
Teams would use artifacts on the workflow level to store various build and test reports and pass data and executables between jobs in a single workflow.
Project level artifacts
The primary use case for project artifacts is storing the final deliverables of the CI/CD process.
Similarly, you’ll use the push and pull commands to create and pull artifacts on the project level:
artifact push project myapp-v1.25.tar.gzRead more about setting up artifacts in the Docs.
Setting up retention policy for artifacts
Artifacts are helpful when you’re debugging your failing builds. Once the issue is resolved, they serve little purpose.
By default, artifacts are never automatically deleted. However, setting a retention policy allows you to save costs by not keeping unnecessary data in storage.
Here’s how to set up retention policy for artifacts:
Step 1. Go to Project Settings > Artifacts settings page
Step 2. Define for how long you want to keep artifacts
Step 3. Save your changes.
Benefits for your team
Artifacts are helpful when you’re debugging failing builds. They can provide your team with insights of what’s working and what’s not, and what the problem might be.
With the help of artifacts, you can pass data between jobs in a single workflow or store final deliverables for the whole project. This will speed up your CI/CD process and ensure the quality of your builds.
Pricing policy
Uploading and pushing artifacts is free. You only have to pay if you store them in Semaphore or download (pull) them from the storage.
Your organization is charged for artifacts based on two parameters: data storage and data traffic.
Pricing example
Storage
Price per 1 GB/month of storage is 0.07$. For instance, you store 20 GB of files in artifacts for 10 days. Semaphore treats this as 1/3 of a monthly storage (assuming a 30-day month). This storage generates a charge of:
$0.07 (per GB per month) * 20 (GB) * ⅓ (months) = $0.47
Traffic
Price per 1 GB of traffic is 0.35$. For instance, you have 10 MB file stored as a workflow artifact and you are pulling that file in 10 jobs. This will generate 100 MB or 0.1 GB of traffic.
$0.35 (per GB) * 0.1 (GB) = $0.035
You can see your current artifact spendings on the billing page in Semaphore.
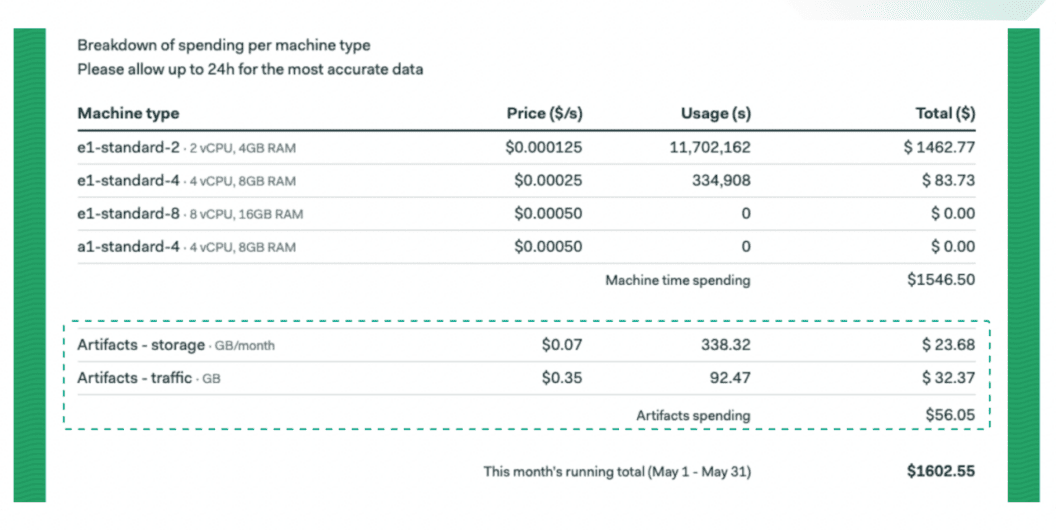
There are several ways you can optimize your artifact spendings:
- Determine which jobs download artifacts by searching for artifact pull commands in your .yml files
- Check if your pulling unnecessary artifacts in your jobs
- Avoid pulling large artifacts in jobs if you are using parallelism
- Don’t use artifacts to cache job dependencies, we provide free cache with unlimited traffic.
- Don’t use artifacts to store and pull large Docker images. Use services like Docker Hub or Amazon ECR instead.
Alternatively, you can use caching for storing dependencies and small/medium sized files that are frequently used in multiple jobs.
You can also use container registry for Docker images. You can use container image registry services like DockerHub and AWS ECR.
Would you like to learn more about artifacts?
Artifacts are a great way to store valuable data and pass it between jobs. Make sure to check out the Docs to learn more about the feature.
If you’d like to learn more about artifacts and how to set them up for your team, feel free to reach out to us. We’ll be happy to help.
Happy building!