When companies think about how to restructure their organizations, they often focus on the new roles that must be filled and the skills that employees need to learn. However, restructuring your organization to support microservice-based applications goes beyond a few roles and job titles. A company restructuring for microservices requires an entire culture shift and new way of working.
Hierarchical Organizations
In order to take advantage of much of the value of a service-oriented architecture, you must change your traditional hierarchical organizational structure to a more horizontal one.
In a traditional hierarchical organization, such as that shown in Figure 1, your engineering company is organized around roles and job functions. Here, multiple development teams are created, and each team is responsible for building part of the application. Once they’ve completed their assigned job functions, responsibility is handed to the next group, often a QA group, which performs testing and the remainder of their job functions. Finally, responsibility is transferred to an IT operations team for hosting and operating the application. Additionally, other groups have their own roles and job functions, such as security, which is responsible for keeping the product and the company safe and secure.

Everyone has their own defined job function. Everyone has their assigned roles. The problem is, nobody is responsible for the product as a whole. Nobody owns the application. Organizationally, you have to go all the way to the highest level of engineering management—such as the VP of engineering or CTO/CPO—before you find someone who owns and manages the product as a whole. This type of structure leads to finger-pointing and a “not-my-problem” mentality.
Everyone has a role to fill, but no one has responsibility.
When you build your application using microservices, one of the advantages is the ability to define and manage smaller chunks of the application as a whole. This advantage isn’t as useful when you keep the traditional organizational structure. You have just moved from having one large application with no owner, to hundreds of smaller applications with no owners.
To fully take advantage of the structural benefits of a microservice application architecture, you must modify your organizational structure to match that model. Most importantly, you must move from a roles and job functions assignment model to a ownership and responsibility assignment model.
The Pod Model
In the pod model, your organization is not split by job functions; instead, it’s split into small, cross-functional teams, called pods. Each team has the capabilities, the resources, and the support required to be completely responsible for a small portion of the overall application—a service or two in the microservice architecture model.
A pod that owns microservices within the application typically consists of 6-10 people with the following types of job skills:
- Team management
- Software development
- Software validation
- Service operation
- Service scaling and maintaining availability
- Security
- Operational support and maintenance
- Infrastructure operational maintenance (servers, etc.)
I use the term job skills, because it’s important that the team has the necessary skills to perform these jobs. But, in a pod model, the pod as a whole has responsibilities, and no single person is assigned specific job functions. In other words, there is no “security person,” or “DevOps person,” or “QA person” in the pod. Instead, everyone in the pod shares the entire pod’s responsibilities.
Figure 2 shows the same organization using a pod model. The pods are each independent and peers of one another, and each pod provides cross-functional responsibilities.
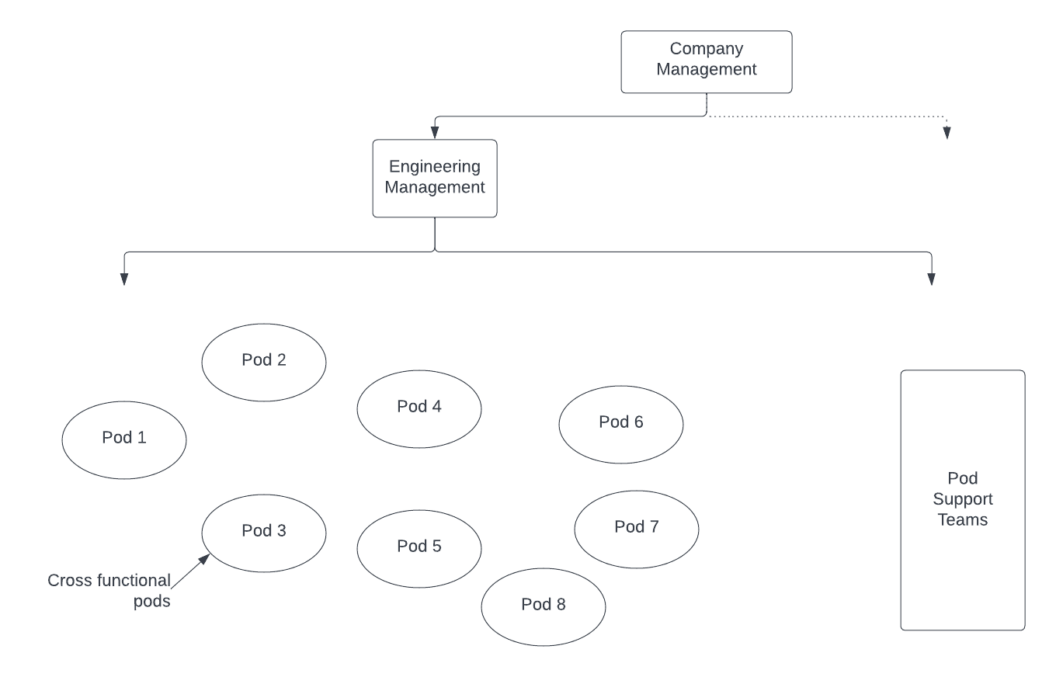
Ownership Is the Key
The key to successfully operating the pod model is to create pods with responsibilities that aren’t specific job functions. Rather, their responsibilities are ownership. A pod owns a service or set of services. Ownership means they have complete responsibility for the architecture, design, creation, testing, operation, maintenance, and security of the service. No one else has ownership, only the assigned pod. If anything happens to that service, it is the pod’s responsibility to manage and fix. This completely removes the ability to finger-point to another team when a service fails. The service’s owning pod is the one responsible. This is illustrated in Figure 3, where interconnected services are represented in blue, and the pods that own those services are shown in red.

Every service has exactly one owner, and if something is failing in a service, it is completely clear which pod is responsible for resolving the issue.
Cross-Service Finger-Pointing
But what happens if problems cross service boundaries? For example, what happens if Service E in Figure 3 is causing problems for Service C? In that case, it may appear that both services are having problems, and it may not be clear where the root cause of the problem resides. Because the two services are owned by different pods, which pod owns the problem? The answer may be difficult and complex to determine. Finger pointing between Pod 2 and Pod 4 is definitely a possibility.
If you have successfully set up a pod model and have ingrained a strong ownership mindset into the members of the pods, the likelihood of finger-pointing in this case should be low. What should happen in a high-quality team organization is both Pod 2 and Pod 4 work together to resolve the issue.
Although this is the way things should work, that’s not sufficient. The model must help resolve these ownership issues quickly and decisively in order to keep your application working, at scale, and maintain high availability. This is where two characteristics of your microservice architecture are critical: Well-designed and documented APIs and solid, maintainable SLAs. Not everyone who promotes moving to microservice architectures drives these two characteristics; but in my mind, they are the two most important characteristics of a solid microservice architecture, and they are critical to the ownership organizational model. Let’s look at these two microservice characteristics:
- Well-designed and documented APIs. Each and every service in your application must have a well-designed API describing how the service should be used and how to talk to it, and this API must be well-documented across the organization. We are used to well-designed and documented APIs when we are talking about APIs exposed to customers. But it’s equally important to design quality APIs among internal services as well. No service should talk to any other service without using a well-defined and documented API to that service. This makes sure that expectations on what each service does and does not do is clear, and those expectations drive higher-quality interactions and hence fewer application issues.
- Solid, maintainable SLAs. Besides having APIs, a set of performance expectations around those APIs must be established. If Service C is calling Service E’s API, it’s critical that Service C understand the performance expectations it can expect from Service E. What will the latency be for the API calls it makes? What happens to latency if the call rate increases? Are there limits on how often a service can be called? What happens when those limits are reached?
APIs are about understanding, and SLAs are about expectations. APIs help us know what other services do and what they are responsible for. SLAs help us know what we can expect from a performance standpoint from the service.
If Service E in Figure 3 has a well-defined and documented API, and has well-defined SLAs on how it should be used and it keeps those SLAs, then as long as Service C is using the service in accordance with the documented API and keeping within the defined SLAs, Service C should be able to expect reasonable performance from Service E.
Now, in the hypothetical example above, Service E was causing problems for Service C. In this case, it should be obvious in the measured performance compared with the documented SLAs that Service E has the problem and not Service C. By using monitoring, and API/SLA management, diagnosing problems becomes far easier.
Pods Need Support
In the pod model, pods have a lot of responsibility and a lot of authority. There is no way that a small team (6-10 people) that composes a pod can handle all aspects of the breadth and depth of responsibility for all aspects of service ownership without support.
To give them support, horizontal service teams are created to provide tools and support to the service-owning pods. These teams can handle common pod-independent problems such as creating CI/CD pipelines, understanding global security issues, creating tooling to manage infrastructures, and maintaining vendor relationships. The pods can then leverage these teams to augment the pod and give support to the pod. This is illustrated in Figure 4.

It’s important to note that these support teams are supporting the pods, and do not—can not—take ownership responsibility away from the pods. If a security issue exists in a service, responsibility for the issue lies with the pod that owns the service—not with the security support team. The pods have ultimate control and decision-making responsibilities—and hence ultimate responsibility—for all aspects of the operation of the services they own.
Summary
Moving to a service/microservice architecture for your application architecture is a valuable tool to building and managing large, complex applications. However, just changing architectures is not sufficient. You must update your organization structure to support the new architecture model or you won’t be able to effectively utilize the advantages service architectures offer. Without also organizing your teams around these changes, you risk falling back into old habits and processes that will result in lack of ownership and responsibility, and the same general problems you had before you moved to the service architecture.
More Information: The STOSA Model
The pod ownership model is part of the STOSA framework. STOSA stands for Single Team Oriented Service Architecture. It defines a model where service teams—pods—own all aspects of building and operating individual services.I developed this model and introduced it in my book, Architecting for Scale. It’s now available as a standalone model documented at stosa.org. I recommend checking it out.
Hello,
very nice blog post, but some diagrams are missing. Could you pls fix it?
BR, Jens