You’re getting started with a new tool. You need to find your way around the documentation quickly. You’re not sure where to start reading. But imagine if someone could tell you which part of the documentation you should start reading first. So let’s build an AI that does that. Even if the documentation is partially written.
We will be building a bot that answers questions about the Semaphore documentation. You will learn how to build a RAG chatbot. And you will also build a tool that will help you get started with Semaphore.
But this will not be an ordinary RAG chatbot. It will also be useful while the documentation is still incomplete. So you will also learn a technique for working with sparse data.
What we are actually building
We are building a Python chatbot that will answer questions based on the new Semaphore documentation on GitHub. The bot will run in the terminal. It will answer questions about the new Sempahore documentation. It will provide a short answer and then direct you to the source document where you can read more.
These types of chat with documents systems are called Retrieval-Augmented Generation (RAG). When the user asks a question, the retriever searches for the relevant information. The retrieved information is inserted into the LLM’s prompt. And the LLM is instructed to generate the answer to the user’s question. The LLM’s answer must be based solely on the information provided in the prompt.
The LLM has a context window of a fixed size. The size of the input context window limits how much text we can include in the prompt. The size of the output context limits how much text the LLM can output. Therefore, we only augment the prompt with the most relevant chunks of documents. Because in most cases, we can’t fit all of our source documents into a single prompt.
In production, the source documents are stored in the system’s search database. In this tutorial, the documents will be stored in memory. Because we are building a first iteration quickly.
The code in this tutorial runs on Python 3.10.9, and the uses the following packages from pip.
langchain==0.3.0
langchain-openai==0.2.0
langchain-community==0.3.0
faiss-cpu==1.8.0.post1
The LLM that we are using is gpt-4o-mini. But you could swap it for any LLM that you prefer to use.
Is the data usable? This is the greatest challenge
The greatest challenge is that the documentation is still being written. At the time of writing, the new documentation is very sparse. Some documents consist of three letters, “WIP”. Some documents are mostly example code. Some documents are mostly a diagram or two. You can imagine a presenter at a data conference bleating “Garbage-In Garbage-Out!” But it’s my job to deliver a solution despite the sparse data. So here’s the solution that I came up with.
We can often guess the purpose of a document before it has been completed. We look for clues. For example, a file called “SECURITY.md” will probably be about security. Even if the contents of that file are just three letters, “WIP”.
Let’s imagine another example. A file that contains a single YAML template, and no text to describe the template. This file is probably related to config.
We will be using the LLM to augment our documents with information that is implied by their path, file name, and content so far. Some documents have a lot of text already. Others have a few letters. To make every “document” is roughly the same size, we will use the LLM to generate summaries of those documents. Our RAG chatbot will only use the document summaries and the augmented context. The bot will explicitly direct the user to the source documents in each answer.
At the time of writing, the document preprocessing step takes approximately five minutes. And it costs less than $0.10 in OpenAI fees.
Anthropic have recently published an article that also describes a technique of augmenting data for RAG. In a typical RAG use case, the documents are split into chunks. When the user asks a question, the retriever retrieves only the most relevant chunks. Usually from several different source documents. In Anthropic’s Contextual Retrieval, they generate additional context for each chunk of text. This can help the retriever understand what the source document was talking about. In our case, we are not chunking our “documents”. For each source document, we are retrieving the whole summary plus augmented context.
For example, here is a “summary plus augmented context” for docs/getting-started/guided-tour.md.
The path 'docs/getting-started/guided-tour.md' suggests that this document serves as an introductory guide for new users of SemaphoreCI, helping them navigate the initial steps of setting up and using the tool effectively.
This document provides a guided tour for new users of SemaphoreCI. It outlines essential tasks such as signing up, creating an organization, setting up a first project, and understanding Continuous Integration and Continuous Delivery processes. The document aims to help users get started with SemaphoreCI quickly and effectively, ensuring they can leverage the tool for their CI/CD workflows.
The 'Guided Tour' document is a 20-minute tutorial designed to help new users of SemaphoreCI get acquainted with the platform. It emphasizes that no credit card is required to try out Semaphore, making it accessible for users to explore its features without any commitment. The tutorial covers four key learning objectives: first, it guides users through the sign-up process and organization creation; second, it introduces a simple 'Hello, World!' project to demonstrate the basic functionalities of CI; third, it provides a real-world example of Continuous Integration, including build and test steps; and finally, it explains the Continuous Delivery process, which includes releasing and deploying apps. Overall, this document serves as a foundational resource within the broader documentation, aimed at onboarding users efficiently and encouraging them to leverage SemaphoreCI for their development workflows.
Another example is SECURITY.md. At the time of creating this tutorial, the file is a work in progress literally containing just three letters: “WIP”. On their own, these three letters would be useless to the retriever. Here is a “summary plus augmented context” for SECURITY.md:
The path 'SECURITY.md' suggests that this document is focused on security practices, guidelines, or considerations relevant to the Semaphore CI/CD tool. It likely outlines how users can secure their CI/CD processes, manage sensitive data, and comply with security standards.
This document is intended to provide insights into the security protocols and best practices associated with using Semaphore CI/CD. Security is a critical aspect of CI/CD tools as they handle code, configurations, and potentially sensitive data. This document will help users understand how to implement security measures within their Semaphore workflows, contributing to overall operational security.
The document labeled 'Security' is currently marked as 'WIP' (Work In Progress), indicating that it is not yet complete. While no specific content is provided, the intention behind the document is to outline security practices and considerations for using SemaphoreCI. Once fully developed, it is expected to cover topics such as securing deployment pipelines, managing access controls, ensuring the integrity of build artifacts, and maintaining compliance with security regulations. This document will be part of the broader SemaphoreCI documentation suite, which addresses various functionalities such as Continuous Integration, Pipelines, and Automation, among others. It will be particularly useful for developers and operations teams looking to implement secure CI/CD practices.
Our prompt for summarizing and augmenting the documents
Here’s the prompt template that we will be using to summarize and augment the source documents. Notice that I wrapped it in a Python multiline string. A prompt template is different to a finished prompt. A prompt template has space for us to insert our data. The strings {path} and {doc} will be replaced by data. They will hold the path to a source document and the text of the source document.
This Python string will live in a file called prompts.py. prompts.py contains three python strings. You will see the other two strings later in this tutorial.
#This is the prompt for summarizing and augmenting the docs
summarize_and_augment_prompt = """
The document in the "document" XML tags is part of the documentation for a CI/CD tool called SemaphoreCI.
The path in the "path_to_document" XML tags is path to that particular document. Pay attention to the file and folder names because they suggest the purpose of the document.
Semaphore is a CI/CD solution to streamline developer workflows.
Semaphore features Continuous Integration and Pipelines, Deployments and Automation, Metrics and Observability, Security and Compliance, a Developer Toolkit, Test Reports, Monorepos, and Self-hosted build agents.
Semaphore works in the cloud, on-premises, and in the hybrid cloud.
<path_to_document>
{path}
</path_to_document>
<document>
{doc}
</document>
The document in the "document" XML tags is part of the documentation for a CI/CD tool called Semaphore.
The path in the "path_to_document" XML tags is path to that particular document. Pay attention to the file and folder names because they suggest the purpose of the document.
Summarize the document. Add context to the document as well. You will need to explain what task it is useful for. And where this document fits into the broader documentation.
Use the following JSON template.
{{
"what_path_suggests": Look at the path to the document. What does the path suggest about this document's purpose?
"what_is_the_document_about": What is this document about? How does it help us use SempahoreCI?
"summarize_document": Summarize the document. If the document has a lot of text, then write many paragraphs. If the document has code or a template, describe what you think tha template is for. What language is the code or template in?
}}
"""Building the retriever
Preprocessing the documents
The new Semaphore documents are stored in a git repo. We will first clone the repo to our local disk. Then we will use Python os.path.walk() to iterate through each document. For each document, we will call the LLM to summarize and augment it. We will also generate an embedding for the combination of the summary and the augmented context.
The code below highlights the important details. The complete code file will be presented later in this article.
How to iterate through each document in the repo
import os
#1. Setup
# Define the directory containing the markdown files
docs_directory = "../semaphore/docs/"
#3.0 Loop through and summarize the markdown files.
for root, dirs, files in os.walk(docs_directory):
#3.1 We loop through the markdown files only
for filename in [ fi for fi in files if fi.endswith(".md") ]:
file_path = os.path.join(root, filename)
#3.2 Read the contents of the markdown file
with open(file_path, "r") as file:
content = file.read()
#...Then we call the LLM for each document in a loop here.How to use the LLM to summarize and augment each document
We are using the Lanchain library. Note that we are not using any of Langchain’s output parsers. We are using OpenAI’s JSON mode to get a structured output. Our chain returns a dictionary object. To enable JSON mode, we use model = ChatOpenAI(model=model_to_use).with_structured_output(None, method="json_mode").
We are also creating metadata for each document. We are creating a field called source. The source of a document is the url of its location on github. The chatbot will display the full URL when answering the user’s questions. The user will be able to click on the URL and view the document on github. The code below shows how it’s done.
import prompts #This is prompts.py, which I mentioned above.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
#1. Setup
# Define the directory containing the markdown files
clickable_url_prefix = "https://github.com/semaphoreci/semaphore/tree/main/docs/"
docs_directory = "../semaphore/docs/"
model_to_use = "gpt-4o-mini"
# Check if output_dir is missing. mkdir if missing.
if not os.path.exists(output_dir):
os.makedirs(output_dir)
summaries = []
summary_metadata = []
#2.0 Setting the Langchain objects
##2.1 Setting up a Langchain "model" object
model = ChatOpenAI(model=model_to_use).with_structured_output(None, method="json_mode")
##2.2 Setting up our prompt template
our_prompt_template = ChatPromptTemplate.from_messages(
[ ("user", prompts.summarize_and_augment_prompt)]
)
#3.0 Loop through and summarize the markdown files.
for root, dirs, files in os.walk(docs_directory):
#3.1 We loop through the markdown files only
for filename in [ fi for fi in files if fi.endswith(".md") ]:
file_path = os.path.join(root, filename)
#3.2 Read the contents of the markdown file
with open(file_path, "r") as file:
content = file.read()
#3.3 Use the LLM to summarize the markdown file
our_path = file_path.replace(docs_directory,"")
clickable_url = clickable_url_prefix + our_path
chain = our_prompt_template | model
json_formatted = chain.invoke({"path": our_path, "doc": content})
#3.4 Append to the summary and path to the lists
the_summary = json_formatted["what_path_suggests"]
the_summary += "\n"
the_summary += json_formatted["what_is_the_document_about"]
the_summary += "\n"
the_summary += json_formatted["summarize_document"]
the_summary += "\n"
summaries.append(the_summary)
summary_metadata.append({"source": clickable_url})How to compute the embeddings
Our retriever searches based on embeddings rather than based on text. Next we need to compute embeddings based on the text that we have just generated. We will compute the “document” embeddings once and then save them to disk.
When the user asks our chatbot a question, we compute the embedding for the question. We then compare our embedded question with the embeddings of our “documents”. We retrieve the documents with the most similar embeddings. The exact implementation is called FAIS and we’ll be using a library for it.
At the end of the code snippet below, we set up a dictionary object that holds the text to be retrieved, the embeddings, and the metadata. In this case, the metadata is the path to the source document. We use the pickle library to save this dictionary object to disk.
import pickle
from langchain_openai import OpenAIEmbeddings
#1. Setup
# Define the directory containing the markdown files
clickable_url_prefix = "https://github.com/semaphoreci/semaphore/tree/main/docs/"
docs_directory = "../semaphore/docs/"
output_dir = "summarized_docs/"
model_to_use = "gpt-4o-mini"
output_pickle_file_name = "texts_and_embeddings.pkl"
output_pickle_file_path = os.path.join(output_dir, output_pickle_file_name)
#...Document looping/generation code has been omitted for clarity.
#4.0 Generate the embeddings
print("Embedding summaries...")
summary_embeddings = embeddings.embed_documents(summaries)
#5.0 zip everything together and save to disk
text_embedding_metadata_triplets = {"embeddings":zip(summaries, summary_embeddings), "meta": summary_metadata}
with open(output_pickle_file_path, "wb") as p_file:
pickle.dump(text_embedding_metadata_triplets, p_file)The complete preprocessing file
We store the code to preprocess the documents in a file called summarize_docs.py.
#This file summarizes the documents, creates embeddings, and saves the data to a pickle file.
import os
import pickle
import prompts
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
#1. Setup
# Define the directory containing the markdown files
clickable_url_prefix = "https://github.com/semaphoreci/semaphore/tree/main/docs/"
docs_directory = "../semaphore/docs/"
output_dir = "summarized_docs/"
model_to_use = "gpt-4o-mini"
output_pickle_file_name = "texts_and_embeddings.pkl"
output_pickle_file_path = os.path.join(output_dir, output_pickle_file_name)
# Check if output_dir is missing. mkdir if missing.
if not os.path.exists(output_dir):
os.makedirs(output_dir)
summaries = []
summary_metadata = []
# Optional: Prompt the user for the API key
#import getpass
#os.environ["OPENAI_API_KEY"] = getpass.getpass()
#2.0 Setting the Langchain objects
##2.1 Setting up a Langchain "model" object
model = ChatOpenAI(model=model_to_use).with_structured_output(None, method="json_mode")
##2.2 Setting up our prompt template
our_prompt_template = ChatPromptTemplate.from_messages(
[ ("user", prompts.summarize_and_augment_prompt)]
)
#2.3 Set up the embeddings model
embeddings = OpenAIEmbeddings()
#3.0 Loop through and summarize the markdown files.
for root, dirs, files in os.walk(docs_directory):
#3.1 We loop through the markdown files only
for filename in [ fi for fi in files if fi.endswith(".md") ]:
file_path = os.path.join(root, filename)
#3.2 Read the contents of the markdown file
with open(file_path, "r") as file:
content = file.read()
#3.3 Use the LLM to summarize the markdown file
our_path = file_path.replace(docs_directory,"")
clickable_url = clickable_url_prefix + our_path
chain = our_prompt_template | model
json_formatted = chain.invoke({"path": our_path, "doc": content})
#3.4 Append to the summary and path to the lists
the_summary = json_formatted["what_path_suggests"]
the_summary += "\n"
the_summary += json_formatted["what_is_the_document_about"]
the_summary += "\n"
the_summary += json_formatted["summarize_document"]
the_summary += "\n"
summaries.append(the_summary)
summary_metadata.append({"source": clickable_url})
#3.5 Optional: Write the sumarised file to disk
s_file_name = os.path.join(output_dir, our_path.replace("/","_"))
with open(s_file_name, "w") as s_file:
print(s_file_name)
path_spec_text = "Path to file: {0} \n\n".format(our_path)
s_file.write(the_summary)
#4.0 Generate the embeddings
print("Embedding summaries...")
summary_embeddings = embeddings.embed_documents(summaries)
#5.0 zip everything together and save to disk
text_embedding_metadata_triplets = {"embeddings":zip(summaries, summary_embeddings), "meta": summary_metadata}
with open(output_pickle_file_path, "wb") as p_file:
pickle.dump(text_embedding_metadata_triplets, p_file)How to retrieve the relevant documents at query time
We’re using FAIS as our retriever. I chose FAIS for this tutorial because it runs in memory. We don’t need to worry installing any databases. In production, you might decide to outsource the retriever to a cloud vendor’s search product.
The code below is an extract from a larger file that is called rag_bot.py. The complete file will be presented later in this article.
We read the pickled data from disk. Then we instantiate a retriever object. To test our retriever, we could search our documents with retriever.invoke(). For example, retriever.invoke("What do I need to keep in mind for security?")
import os
import pickle
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
#1. Setup
docs_dir = "summarized_docs/"
docs_pickle_file_name = "texts_and_embeddings.pkl"
docs_pickle_file_path = os.path.join(docs_dir, docs_pickle_file_name)
with open(docs_pickle_file_path, "rb") as p_file:
text_embedding_metadata_triplets = pickle.load(p_file)
#2.3 Set up the embeddings model
embeddings = OpenAIEmbeddings()
#3.0 Setting up the retriever
faiss_vectorstore = FAISS.from_embeddings(text_embedding_metadata_triplets["embeddings"], embeddings,text_embedding_metadata_triplets["meta"])
retriever = faiss_vectorstore.as_retriever()Building the question-answering component
The RAG question-answering prompt
The question-answering component has a system prompt and a user prompt. The system prompt and the user prompt template are shown below. They are stored in prompts.py.
#This is the prompt for the RAG
rag_system_prompt = """
You are helping me find my way through the Semaphore CI documentation.
You answer my questions based on the context. And then you direct to the source of the document, where I can read more.
You must answer based on the context only. Do not use your general knowledge.
If you don't know the answer then reply with "I don't know".
You are always very optimistic and encouraging.
"""
rag_user_prompt = """
The question is in the "question" XML tags.
The context is in the "context" XML tags.
The context is made up of documents. Each "document" is delimited by its own XML tag.
Each document has a "source" property. You need to direct me to the source of the document. Because the source of the document will have more details.
Answer the question based on the context. If you don't know the answer then reply with "I don't know".
<context>
{context}
</context>
<question>
{question}
</question>
The question is in the "question" XML tags.
The context is in the "context" XML tags.
The context is made up of documents. Each "document" is delimited by its own XML tag.
Each document has a "source" property. You need to direct me to the source of the document. Because the source of the document will have more details.
Answer the question based on the context. If you don't know the answer then reply with "I don't know".
Use the following JSON template for your reply. Write valid JSON.
{{
"answer": Answer the question. Make sure that you explain where I can find more information - in the source of the relevant documents.
"sources": [Output the sources of the documents that you used to answer the question into this array.]
}}
"""How to use the LLM to answer the question
The retriever retrieves the documents that are relevant to our question. Then we need to insert those documents into the LLM’s prompt. The inserted documents are called the context. The prompt instructs the LLM to answer the question, but only based on the context in the prompt.
We need to concatenate all of the retrieved documents into one string. And the final string must be in a style that matches our prompt. We will write a function called format_docs(). You can see it in the code below. Note how we are using the metadata as well.
import prompts
from textwrap import dedent
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
#0. Function used to arrange the search results. Could be used in other code.
def format_docs(docs):
"""
This function formats the documents for insertion into the RAG prompt
"""
doc_template_string = dedent("""
<document source="{the_source}">
{content}
</document>""")
return "\n\n".join(doc_template_string.format(content=doc.page_content,the_source=doc.metadata["source"]) for doc in docs)
#1. Setup
model_to_use = "gpt-4o-mini"
#...The retriever parts of the file have been omitted for clarity
#4.0 Setting up the RAG chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| our_prompt_template
| model
)
#5.0 Calling the RAG chain in a loop to answer question in the terminal
while True:
user_question = input("Your question: ")
rag_answer = rag_chain.invoke(user_question)
print("\nBot's answer: {0}\n".format(rag_answer["answer"]))
print("For more details see: {0}\n\n".format(rag_answer["sources"]))The complete RAG chatbot file
The retriever code and the question-answering code are part of a file called rag_bot.py Here’s the complete file.
#This file has the chatbot
import os
import pickle
import prompts
from textwrap import dedent
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.vectorstores import FAISS
from langchain_core.runnables import RunnablePassthrough
#0. Function used to arrange the search results. Could be used in other code.
def format_docs(docs):
"""
This function formats the documents for insertion into the RAG prompt
"""
doc_template_string = dedent("""
<document source="{the_source}">
{content}
</document>""")
return "\n\n".join(doc_template_string.format(content=doc.page_content,the_source=doc.metadata["source"]) for doc in docs)
if __name__ == "__main__":
# Optional: Prompt the user for the API key
#import getpass
#os.environ["OPENAI_API_KEY"] = getpass.getpass()
#1. Setup
model_to_use = "gpt-4o-mini"
docs_dir = "summarized_docs/"
docs_pickle_file_name = "texts_and_embeddings.pkl"
docs_pickle_file_path = os.path.join(docs_dir, docs_pickle_file_name)
with open(docs_pickle_file_path, "rb") as p_file:
text_embedding_metadata_triplets = pickle.load(p_file)
#2.0 Setting the Langchain objects
##2.1 Setting up a Langchain "model" object
model = ChatOpenAI(model=model_to_use).with_structured_output(None, method="json_mode")
##2.2 Setting up our prompt template
our_prompt_template = ChatPromptTemplate.from_messages(
[ ("system", prompts.rag_system_prompt), ("user", prompts.rag_user_prompt)]
)
#2.3 Set up the embeddings model
embeddings = OpenAIEmbeddings()
#3.0 Setting up the retriever
faiss_vectorstore = FAISS.from_embeddings(text_embedding_metadata_triplets["embeddings"], embeddings,text_embedding_metadata_triplets["meta"])
retriever = faiss_vectorstore.as_retriever()
#4.0 Setting up the RAG chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| our_prompt_template
| model
)
#5.0 Calling the RAG chain in a loop to answer question in the terminal
while True:
user_question = input("Your question: ")
rag_answer = rag_chain.invoke(user_question)
print("\nBot's answer: {0}\n".format(rag_answer["answer"]))
print("For more details see: {0}\n\n".format(rag_answer["sources"]))Putting it all together
Directory structure
We have three .py files. Our three prompts go into prompts.py. summarize_docs.py preprocesses the documents. rag_bot.py is the RAG chatbot that runs in terminal.
I have drawn the directory structure below. The semaphore folder is a clone of the new Semaphore git repo. I haven’t shown all of the files. We are working with the markdown files in the docs directory.
All of the paths that the chatbot displays are relative to semaphore/docs/. There is a second docs directory within semaphore/docs/. So semaphore/docs/docs/getting-started/guided-tour.md will be displayed as docs/getting-started/guided-tour.md.
📂Top_level_dir
┣ 📂docs_chatbot
┃ ┣ 📂summarized_docs
┃ ┃ ┗ 📜texts_and_ebeddings.pkl <== This file is generated by summarize_docs.py
┃ ┣ 📜__init__.py <== Optional.
┃ ┣ 📜prompts.py
┃ ┣ 📜rag_bot.py
┃ ┣ 📜requirements.txt
┃ ┗ 📜summarize_docs.py
┗ 📂semaphore <== This is a clone of the repo at https://github.com/semaphoreci/semaphore.git
┃ ┣ 📁.git
┃ ┣ 📁.github
┃ ┣ 📁.semaphore
┃ ┣ 📁docs <== This is the docs directory that we are working with
┃ ┣ 📜LICENSE
┃ ┗ 📜README.md
Setting the OpenAI API KEY
I have set the OpenAI API KEY as an evironment variable on my machine. I use the following code in the terminal. Note how I clear history.
export OPENAI_API_KEY="my_api_key_here_123"
history -cThen I press ctrl+shift+L to clear the terminal window. Your keyboard shortcuts might be different.
Another option is for the python code to prompt the user for the API key. You can find some commented out code in summarize_docs.py and rag_bot.py.
# Optional: Prompt the user for the API key
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass()Optional code that writes the summmaries and augmented context to disk
summarize_docs.py has some optional code that writes the summmaries and augmented context to disk. You can remove it if you don’t want it. These files are a copy of the text that we are storing in our retriever.
#3.5 Optional: Write the sumarised file to disk
s_file_name = os.path.join(output_dir, our_path.replace("/","_"))
with open(s_file_name, "w") as s_file:
print(s_file_name)
path_spec_text = "Path to file: {0} \n\n".format(our_path)
s_file.write(the_summary)Running the chatbot
Here are the shell commands to preprocess the documents and run the RAG chatbot. I have put the code for this chatbot into a public git repo. So you can set up all of the files by just cloning two git repos.
git clone https://github.com/semaphoreci/semaphore.git
git clone https://github.com/slavarazbash/docs_chatbot.git
Then you will need to install the required packages. I recommend using a virtual environment.
CD docs_chatbot
python -m venv myenv
source myenv/bin/activate
pip install -r requirements.txt
These are the commands to preprocess the documents and start the chatbot.
python summarize_docs.py
python rag_bot.py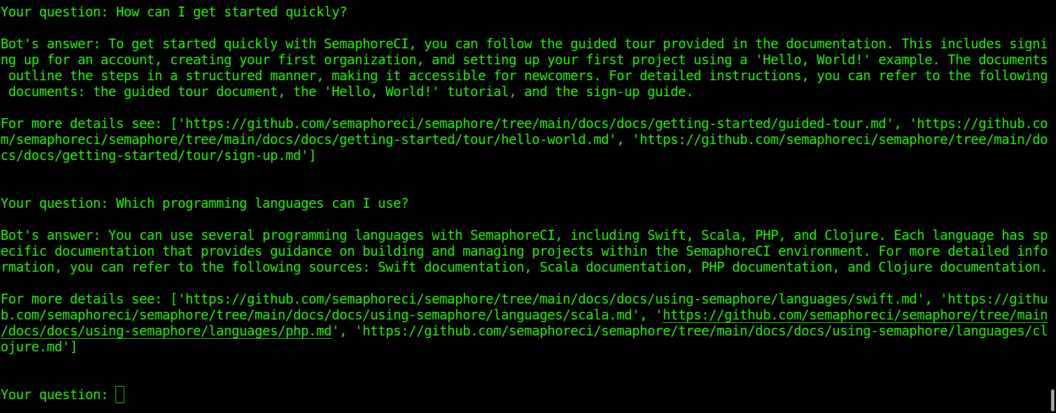

Try it yourself. Please reach out if you have any questions or difficulties.
Want to discuss this article? Join our Discord.
