We’re excited to announce that Semaphore can now run and visualize arbitrarily complex CI/CD pipelines. Although this new feature brings great power and is fueled by fancy-pants directed acyclic graph (or DAG) math theory, it’s actually super simple to use. All you need to do is define how elements of your pipeline depend on each other with a single line of code.
Semaphore 2.0 originally supported sequential pipelines. In each pipeline you could chain together blocks and execute them one by one. You could also run parallel jobs within a block. Here’s an example of such a sequential pipeline:

The structure of semaphore.yml looks like this:
blocks:
- name: Build
...
- name: Unit tests
...
- name: E2E
...Sequential blocks and parallel jobs provide a lot of flexibility and can handle many continuous integration use cases. Especially when extended via promotions for continuous deployment or manual approval. But sometimes you need more.
For example, mobile developers should be able to build and test their cross-platform iOS and Android apps in parallel. If you build multiple binaries like building Docker containers from a Git repository, you want to be able to run independent test pipelines for each variant. Big data pipelines often define computational steps through map/reduce (fan-out / fan-in) patterns. The list goes on.
Introducing block dependencies
You can now define pipelines in terms of block dependencies and Semaphore will schedule and run them in a serverless manner. Here’s an example of what is possible:
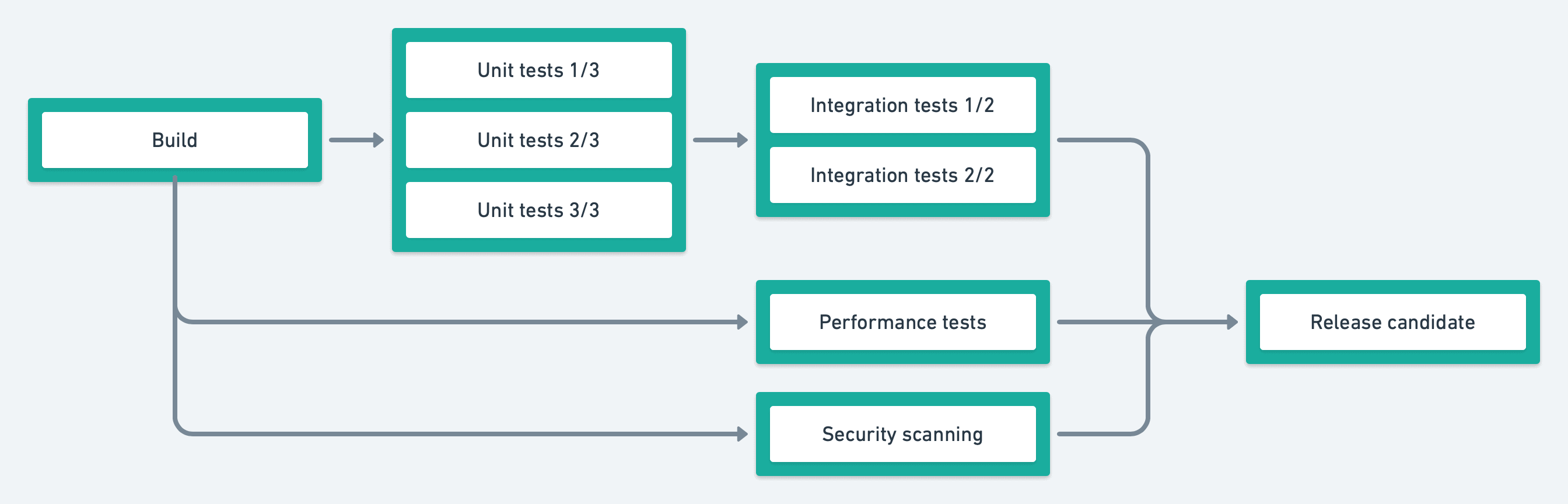
Blocks extended with dependencies can have zero or N dependencies. This gives great flexibility when modeling CI/CD pipelines.
blocks:
- name: Build
dependencies: []
...
- name: Unit tests
dependencies: ["Build"]
...
- name: Integration tests
dependencies: ["Unit tests"]
...
- name: Performance tests
dependencies: ["Build"]
...
- name: Security scanning
dependencies: ["Build"]
...
- name: Release candidate
dependencies: ["Integration tests", "Performance tests", "Security scanning"]
...With this new power, you should consider the logical dependencies of your application and translate them into dependencies within your CI/CD pipeline on Semaphore. We also recommend getting feedback as quickly as possible by parallelizing work.
New CI/CD use cases
With the introduction of block dependencies, the following CI/CD patterns are possible to implement with Semaphore:
- Sequential pipelines
- Parallel pipelines
- Fan in
- Fan out
- Diamond dependencies
Consider the following real-life use cases:
- Build an executable once and test it in parallel.
- Parallel pipelines and release management for different subsystems of your application.
- Multi-platform builds (Docker, Linux, macOS, Android).
- Optimizing pipelines for fast feedback.
- Optimizing pipelines for optimal resource utilization.
You can find examples of modeling complex workflows in Semaphore documentation, with full YML examples in the semaphoreci-demos/semaphore-demo-workflows repository.
We’re very excited to see what you do with the new CI/CD capabilities of Semaphore. We would like to share more examples on this blog — please let us know if there’s something that you’d like us to cover.
Happy building!