Monorepos are highly-active code repositories spanning many projects. These can test the limits of conventional continuous integration. Semaphore is the only CI/CD around with easy out-of-the-box support for monorepos.
Monorepo workflows should be easy to set up
A monorepo is a repository holding many projects, each maintained by a separate developer or team. Most times, these code repositories, while independent, will share a common CI/CD workflow.
Monorepos workflows present their own set of challenges. By default, a CI/CD pipeline will run from beginning to end on every commit. This is expected. After all, that’s the continuous in continuous integration.
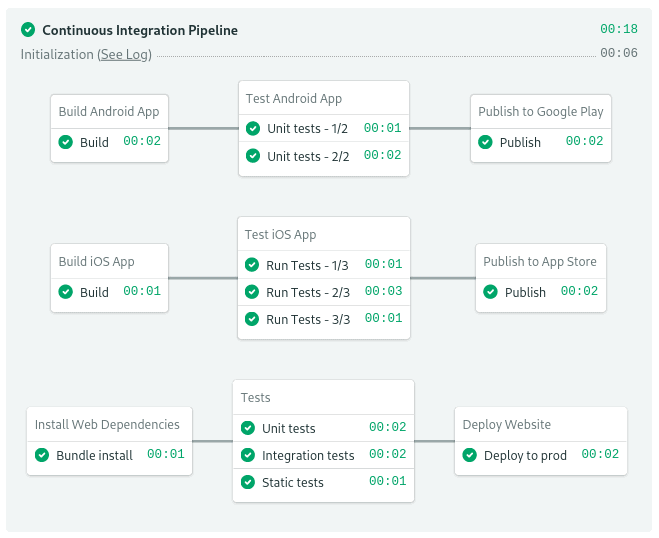
Running every job in the pipeline is perfectly logical on single-project repositories. But monorepos see a lot more activity than usual. Even the smallest change will re-run the entire pipeline — it is time-consuming and needlessly expensive. It just doesn’t make sense.
Semaphore recently introduced the change_in function. Thus adding the capability for change-based execution. With change criteria, you can skip jobs when the relevant code has not been updated. This will let you ignore parts of the pipeline you’re not interested in re-running.
How to set up monorepo workflows
In this section, we’ll set up a monorepo pipeline. We’ll use the semaphore-demo-monorepo project as a starting point, but you can adapt these steps to any CI/CD workflow on Semaphore.
To follow this guide, you’ll need:
- A GitHub account.
- A Semaphore account. Click on Sign up with GitHub to create a free trial account.
Go ahead and fork the repository on GitHub.
It contains three projects, each one in a separate folder:
-
/service/billing: written in Go, calculates user payments. -
/service/user: a Ruby-based user registration service. Exposes a HTTP REST endpoint. -
/service/ui: which is a web UI component. Written in Elixir.
All these parts are meant to work together, but each one may be maintained by a separate team and written in a different language.
Next, log in with your Semaphore account and click on Create New on the upper left corner:
Now, choose the repository you forked.

You can add people to the project at this point. When you’re done, click Continue and select “I want to configure this project from scratch.”

We’ll start with the billing application. Find the Go starter workflow and click on customize:
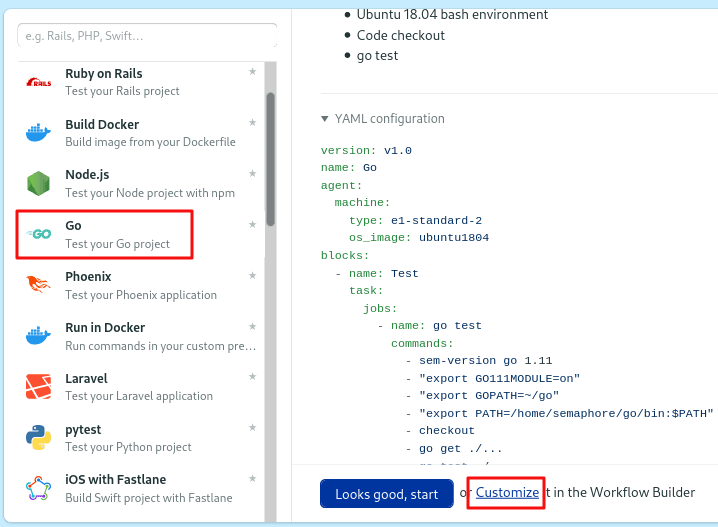
You have to modify the job a bit before it works:
- The billing app uses Go version 1.12. So, change the first line to
sem-version go 1.12. - The code is located in the
services/billingfolder, addcd services/billingaftercheckout.
The full job should look like this:
sem-version go 1.14
export GO111MODULE=on
export GOPATH=~/go
export PATH=/home/semaphore/go/bin:$PATH
checkout
cd services/billing
go get ./...
go test ./...
go build -v .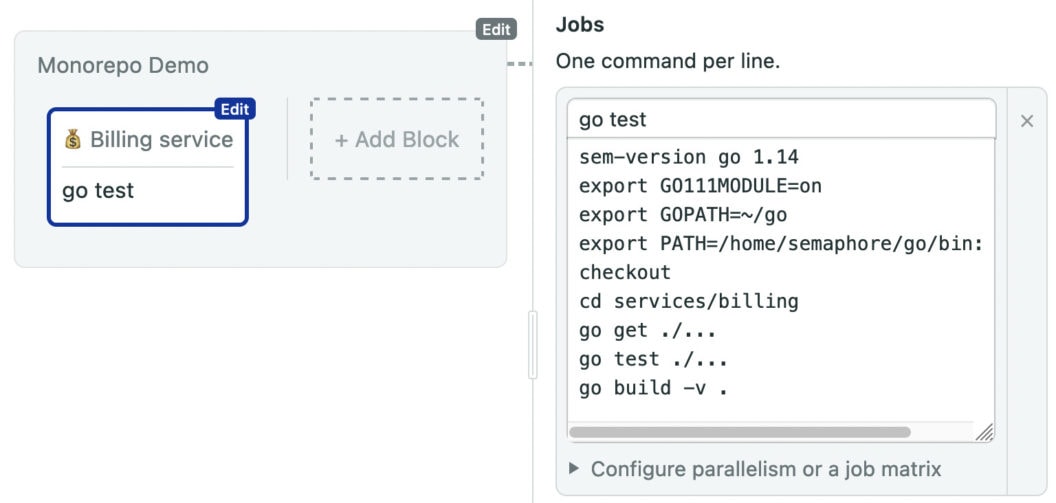
Now click on Run the workflow. Type “master” in Branch and click on Start. Choosing the right branch matters because it affects how commits are calculated. We’ll talk about that in a bit.
Semaphore should start building and testing the application.
Let’s add a second application in the pipeline. Open editor by clicking on Edit Workflow on the upper right corner.
Add a new block. Then, add the commands to install and test a Ruby application:
sem-version ruby 2.5
checkout
cd services/users
cache restore
bundle install
cache store
bundle exec ruby test.rbAnd uncheck all the checkboxes under Dependencies.
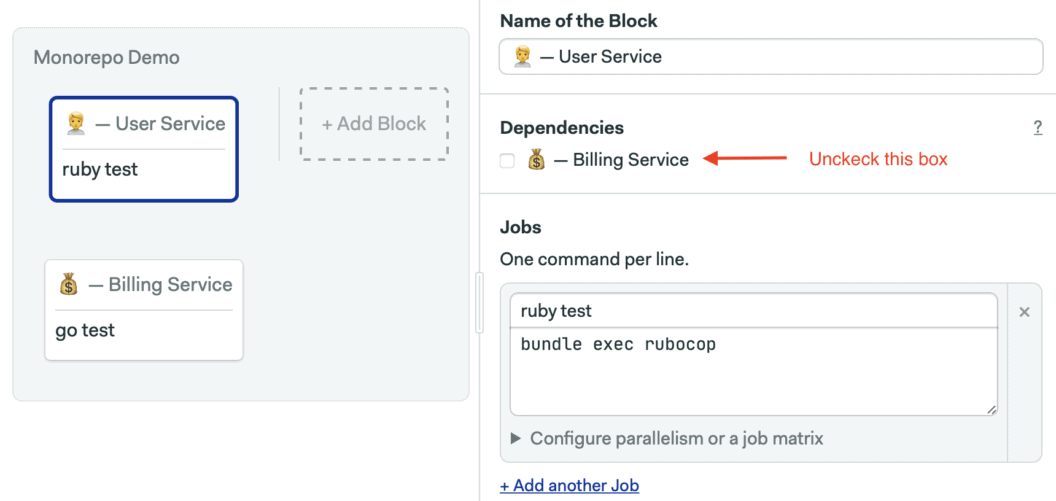
Add a third block to test the UI service. The following installs and tests the app. Remember to uncheck all block dependencies.
checkout
cd services/ui
sem-version elixir 1.9
cache restore
mix local.hex --force
mix local.rebar --force
mix deps.get
mix deps.compile
cache store
mix test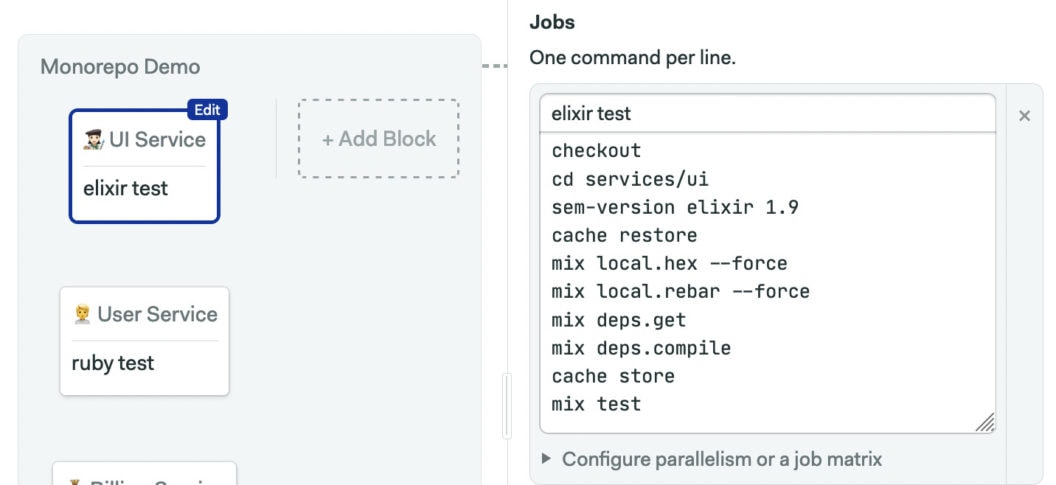
Now, can you guess what happens if we change a file inside the /services/ui folder?
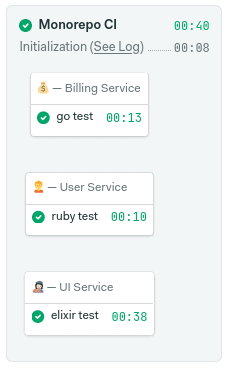
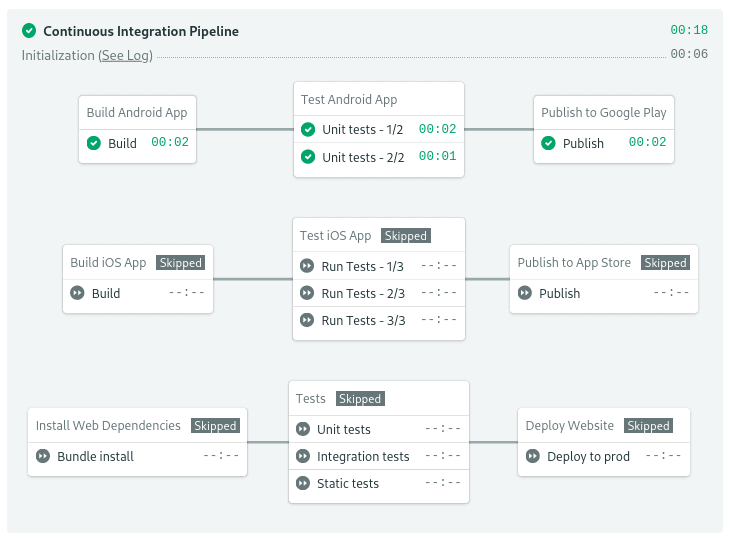
Yeah, despite only one of the projects has changed, all the blocks are running. This is… not optimal. For a big monorepo with hundreds of projects, you can imagine that’s a lot of wasted CPU cycles. The good news is that this is a perfect fit for trying out change-based execution.
Change-based execution with change_in
The change_in function calculates if recent commits have changed code in a given file or folder. We must call this function at the block level. If it detects changes, then all the jobs in the block will be executed. Otherwise, the whole block is skipped. change_in allows us to tie a specific block to parts of the repository.
We can call the function from any block by opening the Skip/Run Conditions section and enabling the option: “Run this block when conditions are met.”
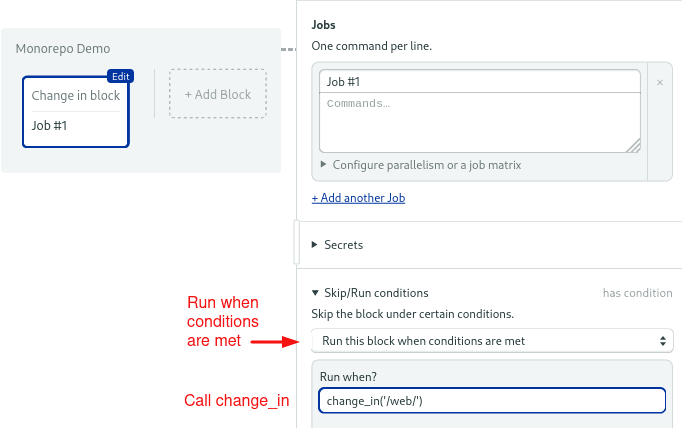
The basic usage of the function is:
change_in('/web/')This will run the block if any files inside the web folder change. Absolute paths start with / and reference the root of the repository. Relative paths don’t start with a slash, they are relative to the pipeline file, which is located inside the /.semaphore folder.
We can also target a specific file:
change_in('../package-lock.json')Wildcards are supported too:
change_in('/**/package.json')Also, you’re not limited to monitoring one path, you may define lists of files or folders. This block, for instance, will run when the /web/ folder or the /manifests/kubernetes.yml file changes (both simultaneously changing work too):
change_in(['/web/', '/manifests/kubernetes.yml'])The function can take a second optional argument to change its behavior. For instance, if your repository default branch is main instead of master (GitHub’s new default), you’ll need to add default_branch: 'main':
change_in('/web/', { default_branch: 'main' })Semaphore will re-run all jobs when we update the pipeline. We can disable this behavior with pipeline_file: 'ignore':
change_in('/web/', { pipeline_file: 'ignore' })Another useful option is exclude, which lets us ignore files or folders. This option also supports wildcards. For example, to ignore all Markdown files:
change_in('/web/', { exclude: '/web/**/*.md' })To see the rest of the options, check the conditions YAML reference.
Speeding up pipelines with change_in
Let’s see how change_in can help us speed up the pipeline.
Open the workflow editor again. Pick one of the blocks and open the Skip/Run conditions section. Add some change criteria:
change_in('/services/billing')Repeat the procedure for the rest of the blocks.
change_in('/services/ui')And:
change_in('/services/users')Now run the pipeline again. The first thing you’ll notice is that there’s a new initialization step. Here, Semaphore is calculating the differences to decide what blocks should run. You can check the log to see what is happening behind the scenes.
Once the workflow is ready, Semaphore will start running all jobs one more time (this happens because we didn’t set pipeline_file: 'ignore' ). The interesting bit comes later, when we change a file in one of the applications. This is what happens:
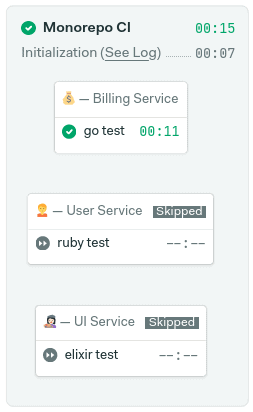
Can you guess which application I changed? Yes, that’s right. I added a file in the billing app. As a result, thanks to change_in, the rest of the blocks have been skipped because they didn’t meet the change conditions.
If we make a change outside any of the monitored folders, then all the blocks are skipped and the pipeline completes in just a few seconds.
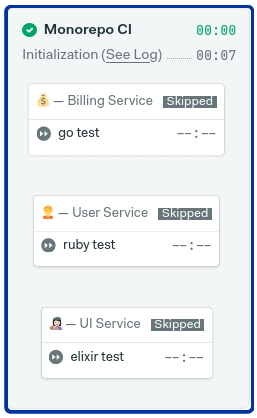
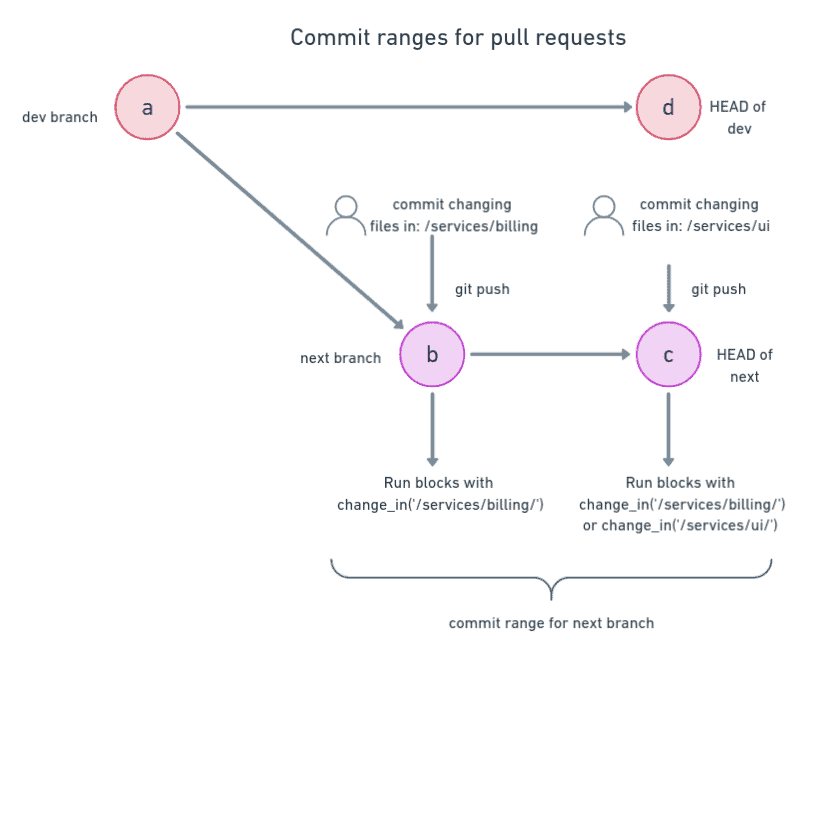
Calculating commit ranges
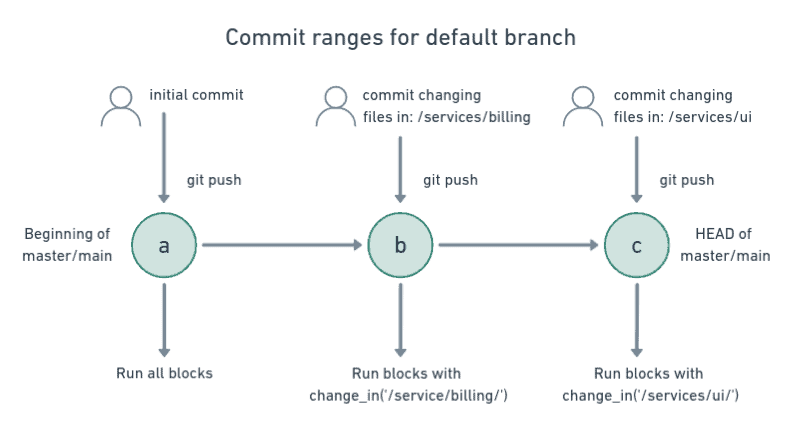
To understand what blocks will run, we must recognize how change_in calculates the changed files in recent commits. The commit range varies depending on if you’re working on main/master or a topic branch.
For the main branch, Semaphore compares the changes in all the commits for the push, then skips the change_in blocks that do not have at least one match.
Semaphore takes a broader criteria for branches. The commit range goes from the point of the first commit that branched off the mainline to the branch’s head. This means that Semaphore may re-run blocks even on commits that seemingly don’t match the change criteria.
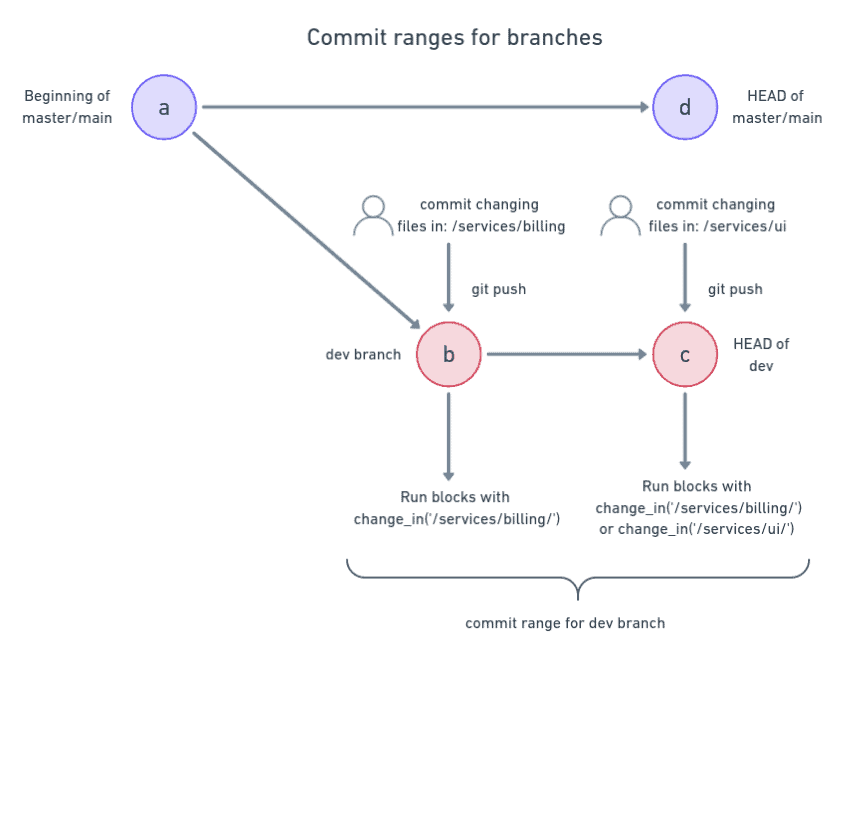
Pull requests behave similarly. The commit range is defined from the first commit that branched off the branch targeted for merging to the head of the branch.
Change-based automatic promotions
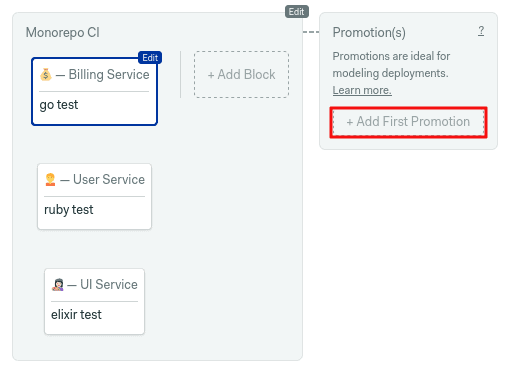
We can also use change_in on autopromotions, which let us automatically start additional pipelines on certain conditions.
To create a new pipeline, open the workflow editor once more and click on Add First Promotion:
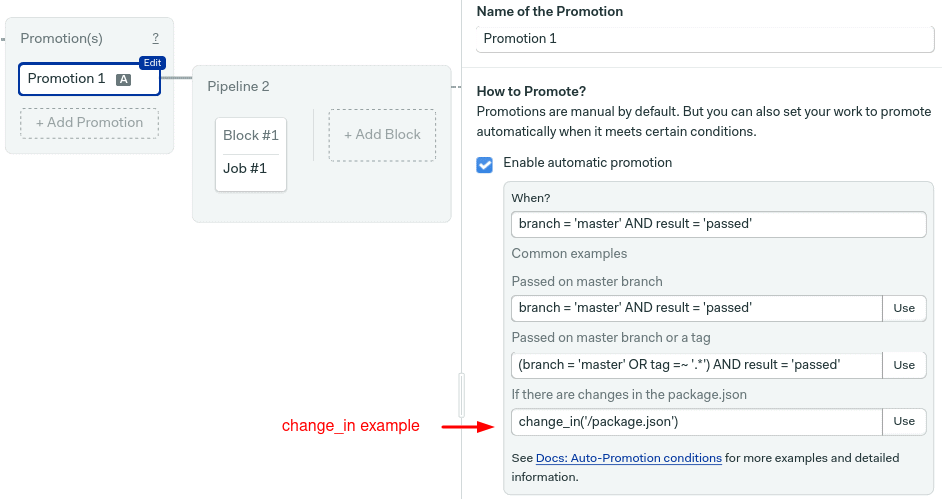
Check Enable automatic promotion. You should see an example snippet you can use as a starting point.
You can combine change_in and branch = 'master' AND result = 'passed' to start the pipeline when all jobs pass on the default branch.
change_in('/services/billing/') and branch = 'master' AND result = 'passed'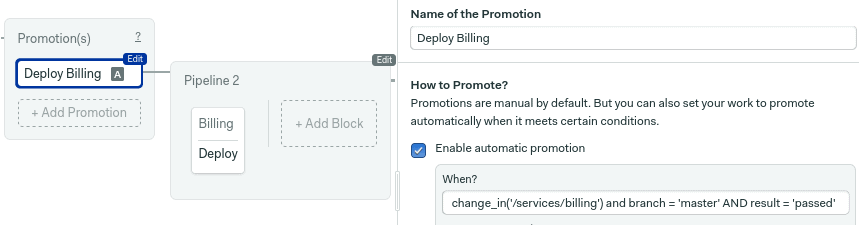
Once done, run the workflow to save the changes. From now on, when you make a change to the billing app, the new pipeline will start automatically if all tests pass on master.
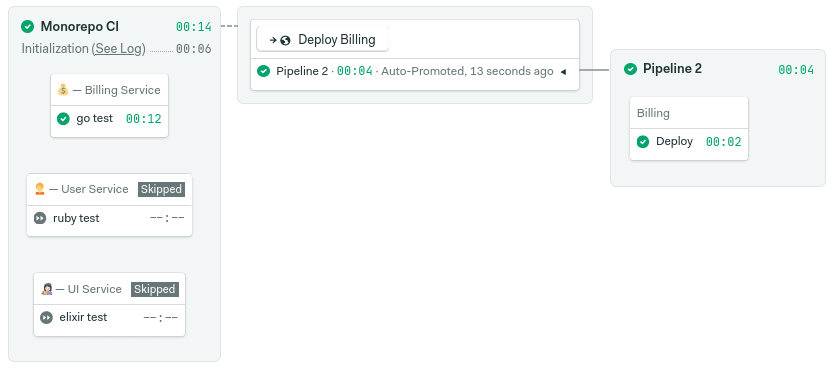
Reusing promotion pipelines
Parametrized promotions let us reuse a pipeline for many tasks. For instance, you can create a deployment pipeline and share it among multiple applications in the monorepo, ensuring you have a unified release process for all the services.
Parametrized promotions work in tandem with environment variables — we define one or more variables and set default values based on the same conditional syntax we use in regular promotions.
To create a parameter, scroll down to the promotion pane and click +Add Environment Variable.
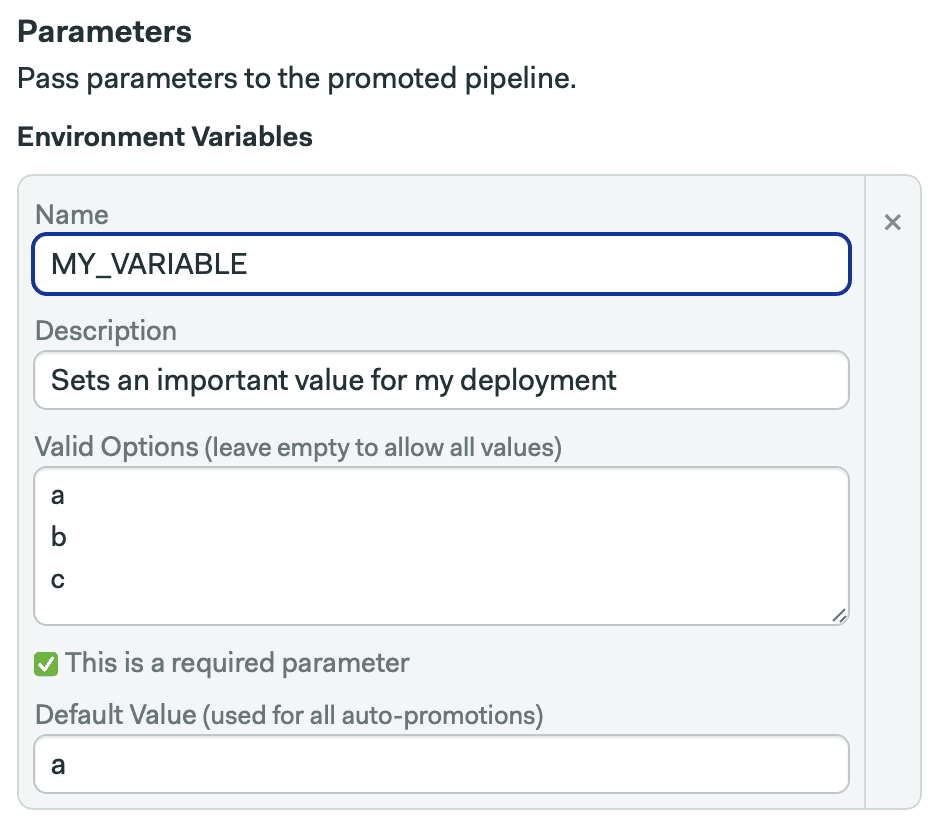
When the promotion is started manually, we can choose a value from the list. With auto-promotions, however, the default value is used.
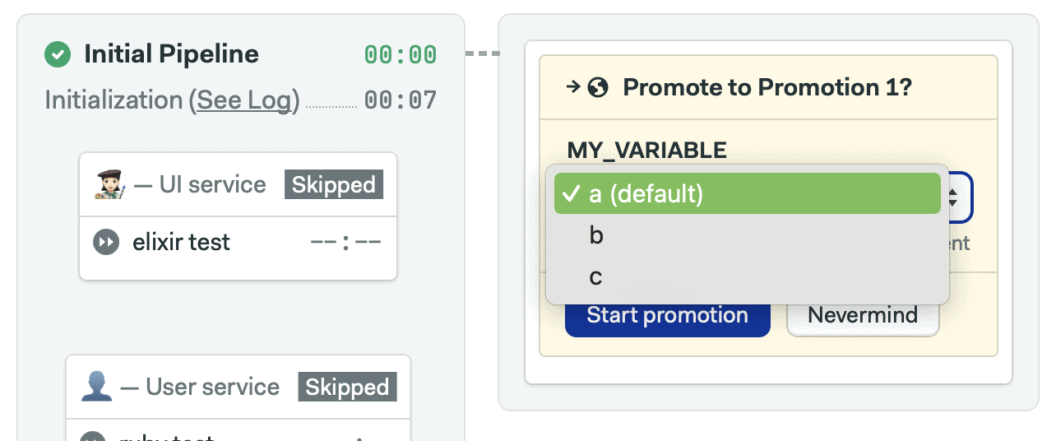
There are three important things to keep in mind while defining a parameter:
- Leaving the list of allowed values empty lets you type in any value, which opens the possibility for human errors.
- Parameters can be optional or mandatory. Required parameters must have a default value defined. Non-mandatory parameters can be empty.
- You can define multiple parameters in the same promotion.
Parameters define global, per-pipeline environment variables that jobs in it can access directly.
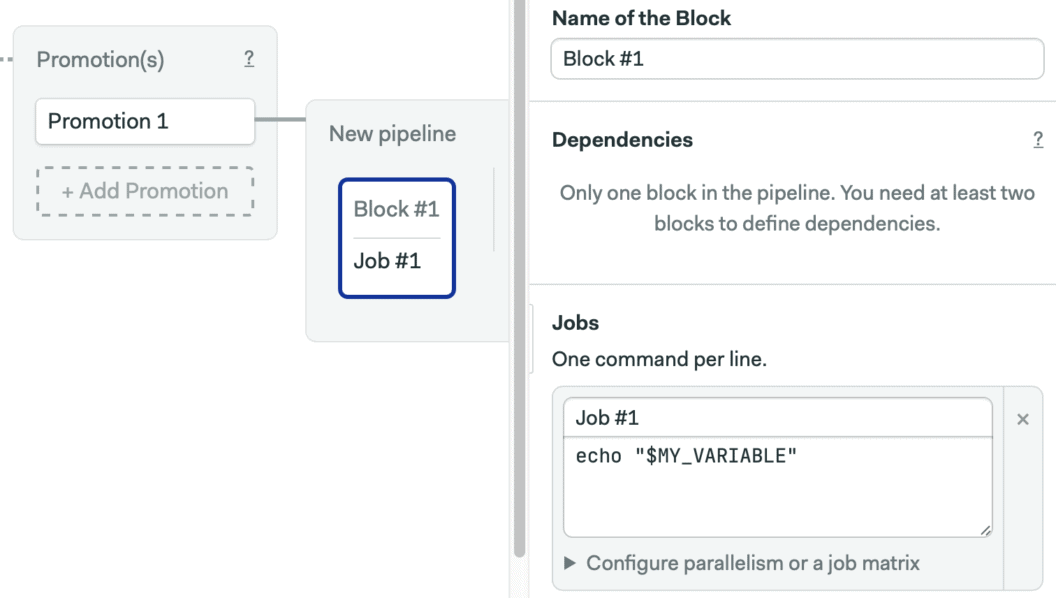
Tips for using change_in effectively
Scaling up large monorepos with change_in is easier if you follow these tips for organizing your code and pipelines:
- Define a unified folder organization, so you can use clean change conditions.
- Design your blocks around project folders.
- When needed, add multiple files and folders to
change_in. Use this to rebuild all the connected project components within a monorepo. - Keep branches small, and merge them frequently to cut build times.
- Use
excludeand wildcards to ignore files that are not relevant, such as documentation or READMEs. - Use
change_inin auto-promotions to selectively trigger continuous delivery or deployment pipelines.
Monorepo workflows got a lot faster
We’ve learned how to best take advantage of Semaphore’s features to run CI/CD pipelines on monorepos. With the change_in function, you may design faster pipelines that don’t waste time or money re-building already-tested code.
Read more about monorepo CI/CD workflows:
Hi. Tks for this article. I always hace a big question about this Workflow.
What happen if I merge into main a super featire which work and rin perfectly on PR/MR but when run on main there was a small error in a yml file? The code was already merged but no one of the changes was deployed. So i fix the yml but non of the paths defined in changein where touched then nothing will de deployed… We cann’t just rerin the las failed pipeline because it always checked oit agains the old commit..
There is no way to run the same projects that failed unless I touch some files (with empty spaces or enter or whatever change)
One idea came up, what if I always build all projects on main but when deploy the docker images that hasn’t changed won’t be deployed
Any ideas? Thanks
These are very good points. And there are many ways in which you could tackle them. If for example the .yml error is in one of the folders monitored by “change_in”, then you can commit the fix to master directly (or open a new branch and PR). This will cause the relevant test and deployment pipelines to trigger and you get a deployment. But as you said, if the error in in a file is not part of any change_in, the relevant test and deployment pipelines will not be triggered. In this case, you can always commit the fixed file to master and trigger the deployment pipeline manually. You can always start any pipeline by clicking the promote button even if its autoexecute conditions are not fulfilled. Let me know if this helps.